
1.1 编码
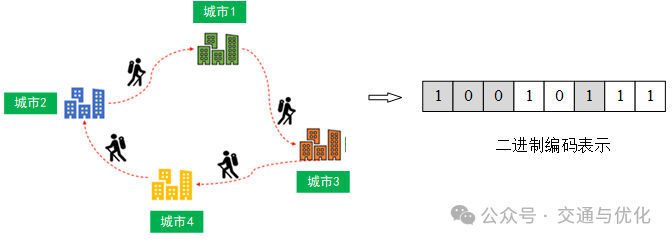
(1)二进制编码
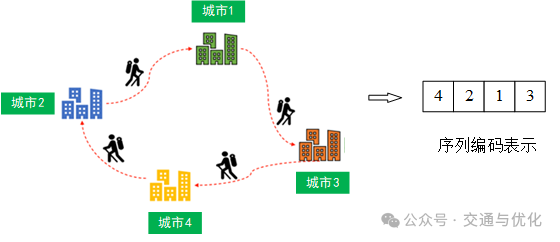
(2)序列编码
1.2初始解
1.3评价函数
1.4邻域结构
(1)元素交换
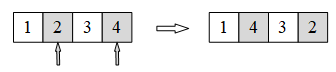
(2)元素嵌入

(3)元素反转

1.5候选集
1.6禁忌表
(1)以状态本身或者状态的变化作为禁忌对象。例如:在上述TSP问题中,可将解作为禁忌对象。
(2)以状态分量以及分量的变化作为禁忌对象。例如:在上述TSP问题中,解的变化为:,可将元素{3, 4}变化的过程作为禁忌对象。
(3)以状态分量以及目标值变化作为禁忌对象。例如:在上述TSP问题中,将解(1, 2, 3, 4)对应的目标函数值44作为禁忌对象。
1.7选择策略
1.8破禁策略
1.9停止准则
(1)设置最大迭代次数,例如:将算法的最大迭代次数设置为500。
(2)设置最好的解不再更新的次数,例如:将最好的解不再更新的次数设置为100,达到该条件后停止迭代。
(3)设置某个禁忌对象禁忌的次数,例如:假设上述TSP问题中,禁忌对象为解(1, 2, 3, 4),当其禁忌次数达到50次时,停止迭代。
1.10解码
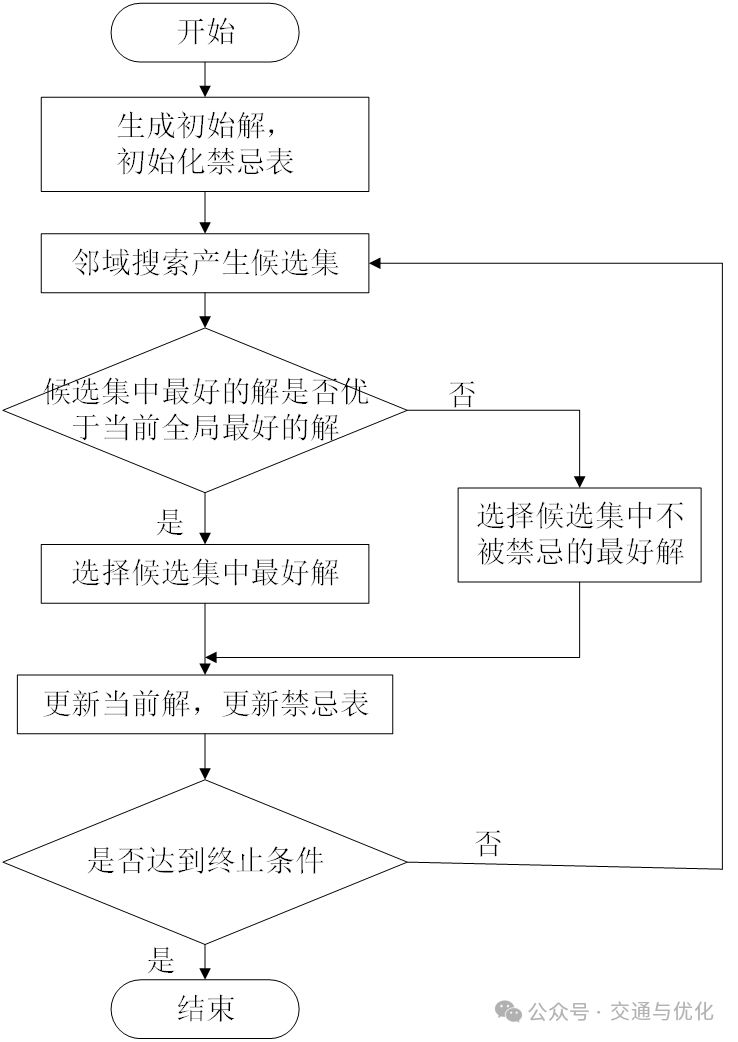
(1)初始化,产生初始解,清空禁忌表;
(2)判断是否满足终止条件,若满足,则输出当前最优解并进一步执行解码操作;否则执行步骤(3);
(3)在当前解的邻域内产生候选解集合,并计算候选解的适应值;
(4)将适应值最好的解与当前搜索得到的最好的解进行比较:如果优于当前最好解,更新其为最好的解,并作为下次迭代的当前解;否则从候选集中选择未被禁忌的最好解作为下次迭代的当前解;
(5)更新禁忌表;
(6)返回步骤(2)。
本节以禁忌搜索算法求解50个城市TSP问题为背景,从环境声明、主函数以及子函数定义几个方面,详细介绍Python代码实现过程。
3.1环境声明
1. import numpy as np #关于数值运算的函数库
2. import random #关于随机数的函数库
3. import xlrd #读取excel的函数库
4. import copy #复制变量的函数
5. import matplotlib.pyplot as plt #绘图
6. from matplotlib import rcParams #绘图
1. ############## 类声明 ###############################
2. class Node: #将节点的所有信息打包为Node类变量
3. def __init__(self):
4. self.node_id = 0 #节点编号
5. self.x = 0.0 #节点横坐标
6. self.y = 0.0 #节点纵坐标
7. class Solution: #将求解打包为Solution类变量
8. def __init__(self):
9. self.cost = 0
10. self.route = []
11. def copy(self):
12. solution = Solution()
13. solution.cost = self.cost
14. solution.route = copy.deepcopy(self.route)
15. return solution
1. ############## 数据导入 #############################
2. #将"input_node.xlsx"中的节点信息汇总为集合N
3. N={}
4. book = xlrd.open_workbook("input_node.xlsx")
5. sh = book.sheet_by_index(0)
6. for l in range(1, sh.nrows): # read each lines
7. node_id = str(int(sh.cell_value(l, 0)))
8. node = Node()
9. node.node_id = int(sh.cell_value(l, 0))
10. node.x = float(sh.cell_value(l, 1))
11. node.y = float(sh.cell_value(l, 2))
12. N[l-1]=node
1. #根据节点信息计算距离矩阵distance,distance[i][j]代表从i节点到j节点的出行成本
2. distance=[[0 for j in range(sh.nrows-1)] for i in range(sh.nrows-1)]
3. for i in range(sh.nrows-1):
4. for j in range(sh.nrows-1):
5. distance[i][j]=((N[i].x-N[j].x)**2+(N[i].y-N[j].y)**2)**0.5
1. ############## 参数设置 ############################
2. Iter=500 #迭代次数
3. City_number = sh.nrows-1 # 城市数量
4. tabu_length = City_number*0.2 #禁忌长度
5. candidate_length = 200 #候选集的个数
1. history_best = [] #存放历史最优目标值
2. history_route=[[]]#存放历史最优路径
3. best_solution.cost = 9999#初始最优值
3.2主函数
1. ############## 主函数 ############################
2. for k in range(Iter):
3. candidate,candidate_distance,swap_position = get_candidate(current_solution.route,distance,City_number)
4. min_index = np.argmin(candidate_distance)
5. #判断邻域动作是否在禁忌表中,若不在禁忌表中则判断候选集中最小值与全局最优值的大小
6. if swap_position[min_index] not in tabu_list:#若邻域动作不在禁忌表中
7. if candidate_distance[min_index] < best_solution.cost:#若候选集中最小值小于最优值,则更新当前解与最优解
8. best_solution.cost = candidate_distance[min_index]
9. best_solution.route = candidate[min_index].copy()
10. current_solution.route = candidate[min_index].copy()
11. current_solution.cost = candidate_distance[min_index]
12. tabu_list.append(swap_position[min_index])#更新禁忌表
13. history_best.append(best_solution.cost)
14. history_route.append(best_solution.route)
15. else:#若候选集中最小值大于最优值,则只更新当前解
16. current_solution.route = candidate[min_index].copy()
17. current_solution.cost = candidate_distance[min_index]
18. tabu_list.append(swap_position[min_index])
19. history_best.append(best_solution.cost)
20. history_route.append(best_solution.route)
21. else:#若邻域动作在禁忌表中,判断候选集中最小值与全局最优值的关系
22. if candidate_distance[min_index] < best_solution.cost:#若候选集中最小值小于最优值,则此邻域动作解禁,并更新全局最最优解与当前解
23. del_list.append(tabu_list[tabu_list.index(swap_position[min_index])])
24. del tabu_list[tabu_list.index(swap_position[min_index])]
25. best_solution.cost = candidate_distance[min_index]
26. best_solution.route = candidate[min_index].copy()
27. current_solution.route = candidate[min_index].copy()
28. current_solution.cost = candidate_distance[min_index]
29. history_best.append(best_solution.cost)
30. else:#若候选集中最小值大于最优值,则将此解设置为最大,不再搜索,更新当前解
31. candidate_distance[min_index] = 99999
32. current_solution.route = candidate[min_index].copy()
33. current_solution.cost = candidate_distance[min_index]
34. tabu_list.append(swap_position[min_index])#更新禁忌表
35. history_best.append(best_solution.cost)
36. history_route.append(best_solution.route)
37. if len(tabu_list) > tabu_length:#禁忌表移动
38. del tabu_list[0]
3.3子函数
(1)关键技术1:计算目标函数值。
1. ############## 计算路径成本消耗 ############################
2. def route_cost(route,distance,City_number):
3. cost = 0
4. for i in range(City_number - 1):
5. cost += distance[int(route[i])][int(route[i + 1])]
6. cost += distance[int(route[City_number - 1])][int(route[0])] # 加上返回起点的距离
7. return cost
(2)关键技术2:实现两点交换的邻域结构,即:2-opt。
1. ############## 邻域操作 ############################
2. def swap(route,route_i,route_j):
3. new_route=copy.deepcopy(route)
4. while route_i<route_j:
5. temp=new_route[route_i]
6. new_route[route_i]=new_route[route_j]
7. new_route[route_j]=temp
8. route_i+=1
9. route_j-=1
10. return new_route
(3)关键技术3:根据邻域结构随机生成候选解集合。
1. ############## 产生邻域候选解集合############################
2. def get_candidate(route,distance,City_number):
3. swap_position = []
4. i = 0
5. while i < candidate_length:
6. current = random.sample(range(0,City_number),2)
7. if current not in swap_position:
8. swap_position.append(current)
9. candidate[i] = swap(route,current[0],current[1])
10. candidate_distance[i] = route_cost(candidate[i],distance,City_number)
11. i += 1
12. return candidate,candidate_distance,swap_position
3.4求解结果
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/88179.html