
随着Python语言在科学计算、数据分析、机器学习和开发等领域的广泛应用,熟悉Python及其常用库的功能和优势变得愈加重要。

一、列表推导式
squares = [x**2 for x in range(10)]
print(squares)
这段代码展示了如何使用列表推导式快速生成1-9所有整数的平方组成的列表,是一种简洁高效的数据集合构建方式。输出结果如下:
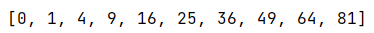

二、数据筛选
# 用Pandas库筛选DataFrame中的数据
df = pd.DataFrame({‘A’: [1, 2, 3], ‘B’: [4, 5, 6]})
filtered = df[df[‘A’] > 1]
print(‘原始数据:’)
print(df)
print(‘筛选后的数据:’)
print(filtered)
在这个片段中,我们利用Pandas库创建了一个DataFrame,并删选‘A’属性大于1的数据。输出结果如下:

三、数组操作
# 使用NumPy库进行高效的数组操作
arr = np.array([1, 2, 3, 4, 5])
arr = arr + 1
a = np.array(([1, 2], [3, 4]))
b = np.array(([5, 6], [7, 8]))
print(np.matmul(a, b))
这段代码计算了矩阵a和矩阵b的相乘,输出结果是:

四、数据可视化
import numpy as np
# 使用Matplotlib库绘制简单的函数图
x = np.linspace(0, 2 * np.pi)
y = np.sin(x)
plt.plot(x, y)
plt.title(‘Sin(x)’)
plt.show()
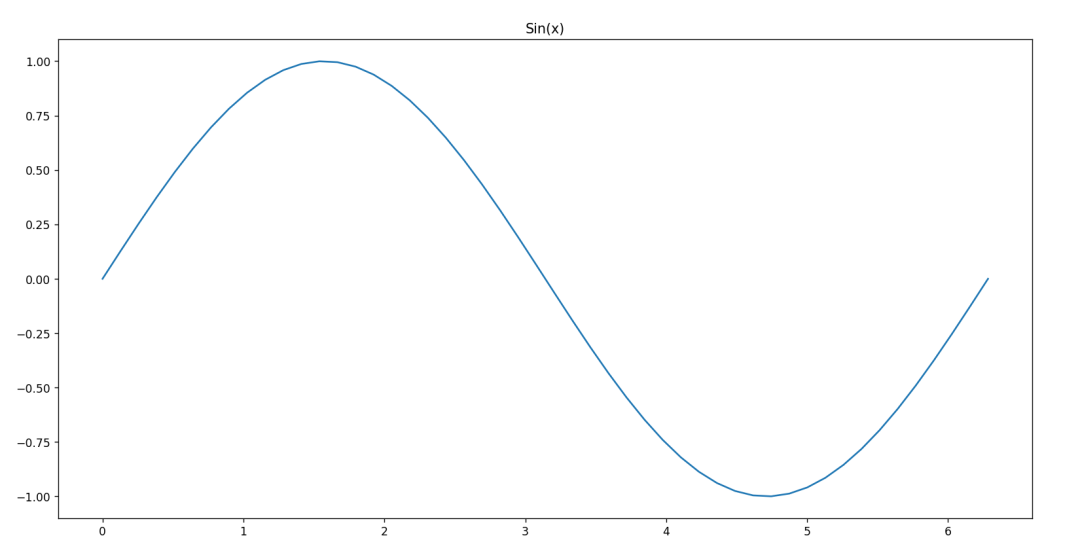
代码运行结果如下:
五、数据集成化展示
import matplotlib.pyplot as plt
# 使用Seaborn进行数据集成化展示
sns.set(style=”darkgrid”)
tips = sns.load_dataset(“tips”)
sns.relplot(x=”total_bill”, y=”tip”, data=tips)
plt.show()
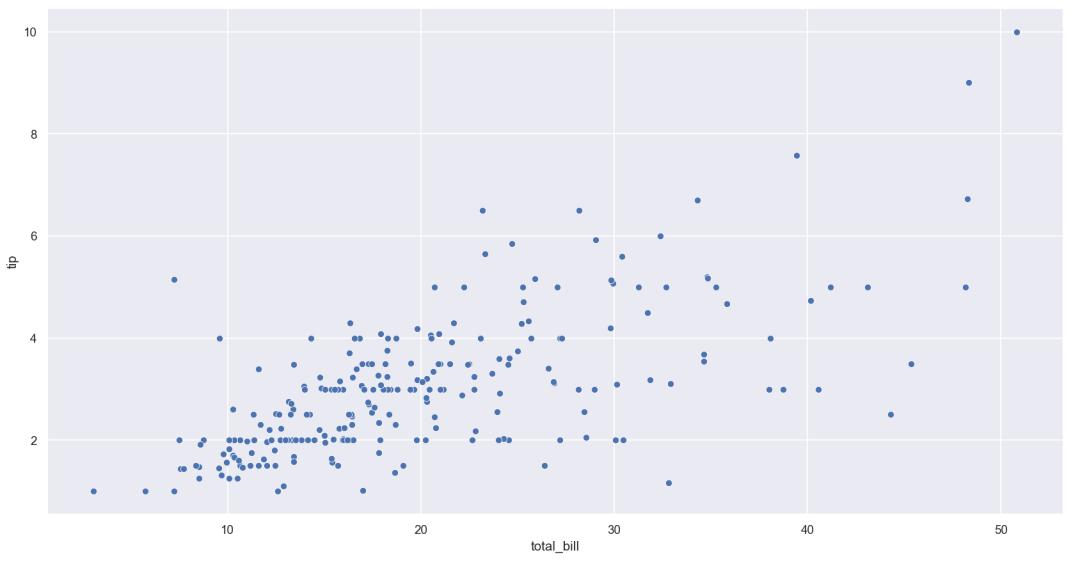
Seaborn是基于Matplotlib的高级绘图库,可用于制作更为美观和更加集成化的统计图表。这段代码可以生成“tips”数据集的散点图,代码运行结果如下:
六、Excel数据读写
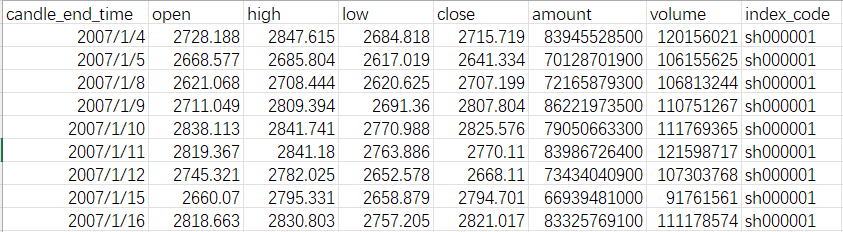
现在我们有一份2007年1月至2024年2月的上证指数数据,保存为“sh000001.xlsx”:
pandas库的函数可以帮助我们很方便的读写这份数据。
df = pd.read_excel(‘sh000001.xlsx’)
df[‘5日移动平均线’] = df[‘close’].rolling(5).mean()
df.to_excel(‘sh000001_new.xlsx’)
我们首先利用pd.read_excel读取这份数据,计算一下收盘价的5日移动平均线,并且将数据保存为新的excel表格。新表格数据如下:
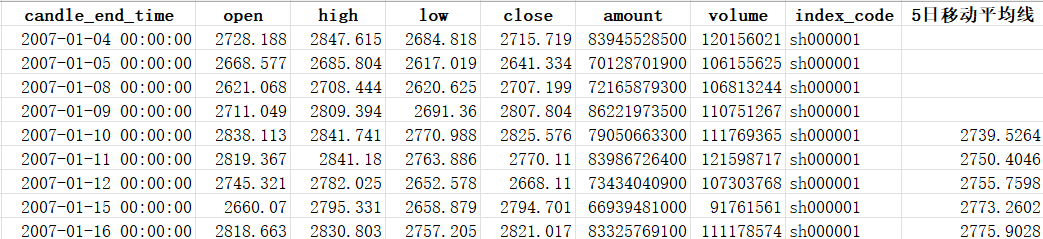
前几行的5日移动平均线是空值,这是因为5日移动平均线至少需要5天的数据才能计算,数据不足则会显示空值。如果想让程序对空值自动填充,可以将第4行代码改为:
这6个Python代码片段囊括了实际编程工作中的常见需求,从基本的数据分析到文件操作,再到图形绘制。
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/88197.html
