
在编写大数据SQL的时候,有时需要进行行列的转化
什么是行列转化?如下图,不同商品在不同月份的销量数据,有时候我们希望数据和左侧一样的排列,但原始数据却像右侧一样排列,此时我们需要把右侧的列排列转换成左侧的行排列,反之亦然。
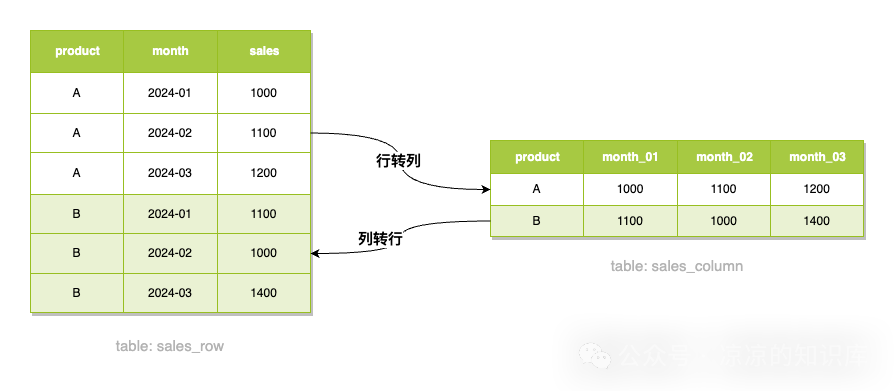
下面以上面这个例子为大家介绍一些行列转换的方式
行转列
使用CASE WHEN
适用场景:MySQL、Hive、Spark SQL
把行转换成列最简单的方式就是使用CASE WHEN
case month when '2024-01' then sales end的意思是当month的值为’2024-01’时取sales的值,其他情况取NULL,因此可以计算出不同月份的销量
select product
,max(case month when '2024-01' then sales end) as month_01
,max(case month when '2024-02' then sales end) as month_02
,max(case month when '2024-03' then sales end) as month_03
from sales_row
group by product
使用PIVOT
适用场景:Spark SQL
PIVOT关键字对于指定的每一组行值,都会生成对应的列。PIVOT关键字是FROM子句的一部分,可以和JOIN等其他关键字一同使用
SELECT ...
FROM ...
PIVOT (
<aggregate function> [AS <alias>] [, <aggregate function> [AS <alias>]] ...
FOR (<column> [, <column>] ...)
IN (
(<value> [, <value>] ...) AS <new column>
[, (<value> [, <value>] ...) AS <new column>]
...
)
)
[...]
| 参数 | 是否必选 | 说明 |
|---|---|---|
| aggregate function | 是 | 聚合函数 |
| alias | 否 | 聚合函数的别名,别名和最终PIVOT处理过后生成的列名相关 |
| column | 是 | 指定转换为列的行值在源表中的列名称 |
| value | 是 | 指定转换为列的行值 |
| new column | 否 | 转换后新的列名称 |
直接看示例
利用PIVOT把month列按值聚合出了三列month_01,month_02,month_03
select *
from sales_row
PIVOT (
MAX(sales) for month in(
'2024-01' as month_01,
'2024-02' as month_02,
'2024-03' as month_03
)
)
列转行
使用UNION ALL
适用场景:MySQL、Hive、Spark SQL
UNION ALL相当于取每一个列的值,然后并联在一起,注意'2024-01' as month中的2024-01是字符串
使用UNION ALL的好处就是,无论是mysql、hive还是spark都支持,以不变应万变
缺点就是当要关联列比较多时比较麻烦,如果要查询全年的数据,则需要UNION ALL 12次,如果是天数据则要UNION ALL 365次
select *
from (
select product, '2024-01' as month, month_01 from sales_column
union all
select product, '2024-02' as month, month_02 from sales_column
union all
select product, '2024-03' as month, month_03 from sales_column
)
仅使用EXPLODE
适用场景:Spark SQL
explode可以将一个数组或者map分解成多行,例如
select explode(split('A,B,C', ','))
# 结果
col
A
B
C
select explode(map('2024-01', 1000, '2024-02', 2000, '2024-03', 3000))
# 结果
key value
2024-01 1000
2024-02 2000
2024-03 3000
对于列转行的需求,可以先创建一个map之后再利用explode拆分成多行
注意下面SQL中,explode函数返回值有两个,因此设置列别名时需要用as (month, sales)
select product
,explode(
map('2024-01', month_01,
'2024-02', month_02,
'2024-03', month_03)
) as (month, sales)
from sales_column
类似的思路还可以利用concat+trans_array等操作
hive中的UDTF
上面的方式仅适用于Spark
当使用UDTF函数(explode就是一个UDTF函数)的时候,Hive只允许对拆分字段进行访问
select explode(map('2024-01', 1000, '2024-02', 2000, '2024-03', 3000))
# 结果
key value
2024-01 1000
2024-02 2000
2024-03 3000
也就是说在Hive中,上面SQL是没问题的,下面的SQL就会报错了
hive> select product
> ,explode(map('2024-01', month_01, '2024-02', month_02, '2024-03', month_03))
> from sales_column
SemanticException [Error 10081]: UDTF's are not supported outside the SELECT clause, nor nested in expressions
因此这块需要使用LATERAL VIEW功能来进行处理。LATERAL VIEW将explode生成的结果当做一个视图来处理。
使用Lateral View
适用场景:Hive、Spark SQL
lateral view为侧视图,意义是为了配合UDTF来使用,把某一行数据拆分成多行数据
Hive中不加lateral view的UDTF只能提取单个字段拆分。加上lateral view就可以将拆分的单个字段数据与原始表数据关联上
LATERAL VIEW [ OUTER ] generator_function ( expression [ , ... ] ) [ table_alias ] AS column_alias [ , ... ]
| 参数 | 是否必选 | 说明 |
|---|---|---|
| generator_function | 是 | 将一行数据拆成多行数据的UDTF (EXPLODE, INLINE等) |
| table_alias | 否 | UDTF结果的别名 |
| columnAlias | 是 | 拆分后得到的列的别名 |
直接看如何利用lateral view实现列转行
select product, t_view.month, t_view.sales
from sales_column
lateral view explode(
map('2024-01', month_01, '2024-02', month_02, '2024-03', month_03)
) t_view as month, sales
其中explode(map('2024-01', month_01, '2024-02', month_02, '2024-03', month_03))把map分解成多行
lateral view同时指定了这个侧视的表名t_view和两列的列名month 、sales
lateral view explode(
map('2024-01', month_01, '2024-02', month_02, '2024-03', month_03)
) t_view as month, sales
# 模拟结果,lateral view不能单独使用
month sales
2024-01 1000
2024-02 1100
2024-03 1200
2024-01 1100
2024-02 1000
2024-03 1400
此时select product, t_view.month, t_view.sales就能达成UDTF拆分的单个字段数据与原始表数据关联的效果了
select product, t_view.month, t_view.sales
from sales_column
# 结果
product month sales
A 2024-01 1000
A 2024-02 1100
A 2024-03 1200
B 2024-01 1100
B 2024-02 1000
B 2024-03 1400
使用UNPIVOT
适用场景:Spark 3.4+
UNPIVOT关键字对于指定的每一组列,都会生成对应的行。其中UNPIVOT关键字是FROM子句的一部分,可以和JOIN关键字等其他关键字一同使用。
SELECT ...
FROM ...
UNPIVOT (
<new column of value> [, <new column of value>] ...
FOR (<new column of name> [, <new column of name>] ...)
IN (
(<column> [, <column>] ...) [AS (<column value> [, <column value>] ...)]
[, (<column> [, <column>] ...) [AS (<column value> [, <column value>] ...)]]
...
)
)
[...]
参数说明如下:
| 参数 | 是否必选 | 说明 |
|---|---|---|
| new column of value | 是 | 转换后新生成的列名称,该列的值由指定转换为行的列的值填充。 |
| new column of name | 是 | 转换后新生成的列名称,该列的值由指定转换为行的列名称填充。 |
| column | 是 | 指定转换为行的列名称,列的名称用来填充new column of name;列的值用来填充new column of value。 |
| column value | 否 | 指定转换为行的列的别名 |
也是直接看示例
select *
from sales_column
UNPIVOT (
sales for month in (month_01 as '2024-01', month_02 as '2024-02', month_03 as '2024-03')
)
sales for month in (month_01, month_02, month_03)的意思就是
生成一个新列sales,这一列的值是month_01, month_02, month_03这三列的值
生成一个新列month, 这里一列的值是month_01, month_02, month_03这三列的列名,即’2024-01′, ‘2024-02’, ‘2024-03’
总结
以上介绍了不少行列转换的方式,你还知道哪些方式欢迎评论区留言
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/88574.html