
1、递归函数定义没有问题,递归深层次后易引发什么问题?
(1)影响执行效率
(2)栈溢出。
因为每一次调用函数是,栈区都要给函数分配空间,而且上一次调用并没有结束,调用的次数太多,栈区的内存不够分配了,便会出现栈溢出的情况。
2、堆与栈的区别?
(1)栈的空间是系统自动分配和回收,堆的空间是用户手动分配回收(malloc,calloc,realloc,free)
(2)栈的空间较小,堆的空间较大
(3)栈的地址空间往地址向下增长,堆的地址空间是由低地址到高地址
(4)栈的存储效率更高
3、循环控制条件关键字goto被经常使用,但是goto的使用场合为什么受到局限?
因为goto会破坏程序的栈逻辑。
4、循环控制条件关键字goto的使用场景有哪些?
(1)常用来跳出死循坏;
(2)打印错误;
(3)goto被经常使用,只是使用场合受到局限,因为他会破坏程序的栈逻辑。
5、字节对齐的理解
5.1 什么是字节对齐?
字节对齐主要是针对结构体而言的,通常编译器会自动对其成员变量进行对齐,以提高数据存取的效率;
5.2 字节对齐的两种方式
默认对齐方式、指定对齐方式;
(1)默认对齐方式内存分配满足以下三个条件:
-
结构体第一个成员的地址和结构体的首地址相同; -
结构体每个成员地址相对于结构体首地址的偏移量(offset)是该成员大小的整数倍,如果不是则编译器会在成员之间添加填充字节; -
结构体总的大小要是其成员中最大size的整数倍,如果不是编译器会在其末尾添加填充字节。
如char是1字节,short是2字节,int是4字节…
(2)指定对齐方式使用以下方式声明:
//注:通过#pragma pack(n)改变C编译器的字节对齐方式
#pragma pack(4) //安装4字节的对齐方式
指定对齐方式内存分配满足以下几个条件:
-
结构体第一个成员的地址和结构体的首地址相同 -
结构体每个成员的地址偏移需要满足:N大于等于该成员的大小,那么该成员的地址偏移需满足默认对齐方式(地址偏移是其成员大小的整数倍);N小于该成员的大小,那么该成员的地址偏移是N的整数倍。 -
结构体总的大小需要时N的整数倍,如果不是需要在结构体的末尾进行填充。 -
如果N大于结构体成员中最大成员的大小,则N不起作用,仍然按照默认方式对齐。
注:在使用#pragma pack设定对齐方式一定要是2的整数幂,也就是(1,2,4,8,16,…),不然不起作用的,仍然按照默认方式对齐。
例1:结构体使用字节对齐为1
// date:2022年 11月 08日 星期二 19:35:36 CST
// author: HeiBaiYe
// path: /mnt/hgfs/CD2206/02-c语言
#include <stdio.h>
#pragma pack(1) //通过#pragma pack(n)改变C编译器的字节对齐方式 在C语言中,结构是一种复合数据类型
struct s1{
char ch; // 1
int a; //4
double b; //8
char c1; //1
};
#pragma pack(1)
struct s2{
char ch; //1
int a; //4
double b; //8
};
int main()
{
printf("s1的大小:%ldn ",sizeof(struct s1));
printf("s2的大小:%ldn ",sizeof(struct s2));
return 0;
}
结果:
s1的大小:14
s2的大小:13
例2:结构体使用默认字节对齐方式,m值
// date:2022年 11月 08日 星期二 19:35:36 CST
// author: HeiBaiYe
// path: /mnt/hgfs/CD2206/02-c语言
#include <stdio.h>
struct s1{
char ch; // 1
int a; //4
double b; //8
char c1; //1
};
struct s2{
char ch; //1
int a; //4
double b; //8
};
int main()
{
printf("s1的大小:%ldn ",sizeof(struct s1));
printf("s2的大小:%ldn ",sizeof(struct s2));
return 0;
}
结果:
s1的大小:24
s1的大小:16
参考链接:https://blog.csdn.net/wdl20170204/article/details/109386825
6、局部变量和全局变量可以重名吗?
(1)能,局部变量会屏蔽全局变量。C++中要用全局变量,需要使用 “::”(域解析符) 。C语言中局部变量可以与全局变量同名,在函数内引用这个变量时,会用到同名的局部变量,而不会用到全局变量。
(2)对于有些编译器而言,在同一个函数内可以定义多个同名的局部变量,比如在两个循环体内都定义一个同名的局部变量,而那个局部变量的作用域就在那个循环体内。
7、UNIX系统中fsync函数的作用?
fsync()负责将参数fd 所指的文件数据, 由系统缓冲区写回磁盘, 以确保数据同步。
头文件:#include
定义函数:int fsync(int fd);
函数说明:fsync()负责将参数fd 所指的文件数据, 由系统缓冲区写回磁盘, 以确保数据同步.
返回值:成功则返回0, 失败返回-1, errno 为错误代码。
参考链接:https://blog.csdn.net/Michaelwubo/article/details/41210547
8、const关键字使用有哪些?
8.1 修饰变量
const的 常规用法,在变量初次定义时赋初,并用关键字const修饰,使变量只可访问,不能重新赋值修改变量。
8.2 修饰指针
(1)限制指针变量修饰:指针变量指向的位置不能被修改。定义时,被 const 修饰的指针变量指针只能在定义时初始化,不能定义之后重新指向新的数据。
(2)限制指针变量指向的数据修饰【指针的解引用】:修饰的指针变量指向的变量的值不能被修改,但是该指针可以指向其它空间。
(3)同时限制指针变量和指针变量指向的变量的值修饰:指针变量指向的位置不能被修改,并且指针变量指向变量的值也不能被修改。
(4)修饰函数形参【指针】:函数形参可以利用const关键字进行限制,来防止在函数内部修改指针指向的数据。
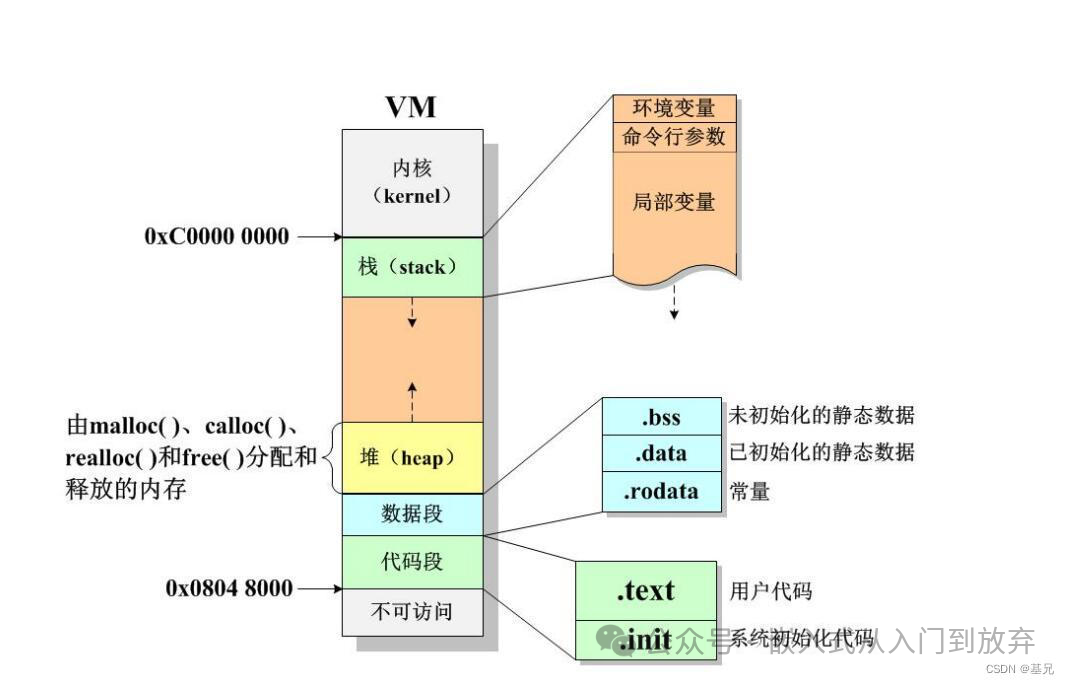
9、内存布局中有哪些段?
文本段(.text)、数据段(.data)、.bss段、堆(heap)、栈(stack)
10、volatile关键字的作用?
(1)裸机编程时,某变量是指向寄存器中某一特定地址,添加volatile的变量不进行优化处理;
(2)某函数与中断函数共享全局变量时,加上volatile,让编译器不要省略该变量的访问;
(3)多线程中修饰共享全局变量,让编译器不要省略该变量的访问。
11、sizeof()与strlen()的区别?
(1)sizeof是运算符,计算能容纳实现所建立的最大对象的字节大小,参数可以是数组、指针、类型、对象、函数等;
(2)strlen是函数,功能是返回字符串的长度,参数必须是字符型指针(char*)。
12、内存泄漏和内存溢出是什么?
(1)内存溢出: 指程序申请内存时,没有足够的内存供申请者使用。或者说,给了你一块存储int类型数据的存储空间,但是你却存储long类型的数据,那么结果就是内存不够用,此时就会报错Out Of Memory,即所谓的内存溢出。
(2)内存泄漏: 是指程序在申请内存后,无法释放已申请的内存空间。一次内存泄漏似乎不会有大的影响,但内存泄漏堆积后的后果就是内存溢出。
13、定义一个指针赋值字符串与定义一个数组赋值字符串有什么区别?
(1)指针赋值字符串是指向一定内存的指针,只不过是指向字符串常量的指针,指针中的数据不能修改。
(2)数组赋值字符串是一片char型的数组,可以理解为缓冲区,只不过是赋值为了字符串。
14、malloc()与calloc分配空间有什么不一样?
(1)malloc申请后空间的值是随机的,并没有进行初始化;而calloc却在申请后,对空间逐一进行初始化,并设置值为0;
(2)malloc要申请的空间大小,需要我们手动的去计算;calloc并不需要人为的计算空间的大小。
15、实现循环的方式?
while、for 、do while 、goto 循环。
16、全局变量和局部变量在内存中有什么不同?
(1)全局变量保存在内存的全局存储区中,占用静态的存储单元;
(2)局部变量保存在栈中,只有在所在函数被调用时才动态地为变量分配存储单元。
17、预处理的作用是什么?
预处理器可以删除注释、包含其他文件以及执行宏(宏macro是一段重复文字的简短描写)替代。
18、编译器的作用?
编译器就是将一种语言(通常为高级语言)翻译为另一种语言(通常为低级语言)的程序。一个现代编译器的主要工作流程:源代码(.c)→ 预处理器(.i) → 编译器 (.s)→ 目标代码 (.o)→ 链接器 → 可执行程序 。
19、.ELF文件是什么?
.ELF是C语言在linux中的可执行文件。
20、C语言程序编译的流程是什么?
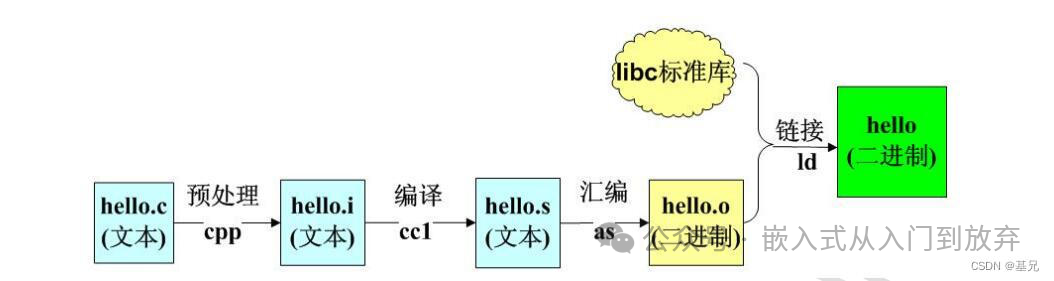
(1)预处理: 根据以字符#开头的命令修给原始的C程序,结果得到另一个C程序,通常以.i作为文件扩展名。主要是进行文本替换、宏展开、删除注释这类简单工作。
对应的命令:linux> gcc -E hello.c hello.i
(2)编译: 编译器将文本文件hello.i翻译成hello.s,包含相应的汇编语言程序。
对应的命令:linux> gcc -S hello.c hello.s
(3)汇编: 将.s文件翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序的格式,并将结果保存在目标文件.o中(把汇编语言翻译成机器语言的过程)。
把一个源程序翻译成目标程序的工作过程分为五个阶段:词法分析;语法分析;语义检查和中间代码生成;代码优化;目标代码生成。主要是进行词法分析和语法分析,又称为源程序分析,分析过程中发现有语法错误,给出提示信息。
对应的命令:linux> gcc -c hello.c hello.o
(4)链接: 将静态库和动态库的库函数连接到可执行程序中。静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为.a。动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为.so,gcc在编译时默认使用动态库。
原文链接:https://blog.csdn.net/daide2012/article/details/73065204
21、如何用C语言实现C++的类?
(1)由于C语言是面向过程,而C++是面向对象,所以在定义数据时,可以用C的结构体成员充当C++类的成员定义;
(2)由于结构体只能定义变量,不能够定义函数,所以通过函数指针的方法来实现其类函数的定义。
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/89036.html