
引言
在大语言模型(LLMs)的时代,它们的应用范围从简单的文本摘要和翻译到基于情感和财务报告主题预测股票表现,文本数据的重要性前所未有。
有许多类型的文档共享这种非结构化信息,从网页文章和博客帖子到手写信件和诗歌。然而,这些文本数据的大部分以PDF格式存储和传输。具体而言,每年在Outlook中打开的PDF文档超过20亿份,而每天在Google Drive和电子邮件中保存的新PDF文件达7300万份(2)。
因此,更系统地处理这些文档并从中提取信息将使我们能够拥有自动化的流程,并更好地理解和利用这庞大的文本数据。而在这项任务中,当然,我们最好的朋友莫过于Python。
然而,在我们开始处理之前,我们需要明确当前存在的不同类型的PDF文档,更具体地说,是三种最频繁出现的类型:
- 程序生成的PDF:这些PDF是使用计算机上的W3C技术(如HTML、CSS和Javascript)或其他软件(如Adobe Acrobat)创建的。这种类型的文件可以包含各种组件,如图像、文本和链接,这些组件都是可搜索且易于编辑的。
- 传统扫描文档:这些PDF是通过扫描仪或移动应用程序从非电子媒介创建的。这些文件实际上只是存储在PDF文件中的图像集合。换句话说,这些图像中出现的元素,如文本或链接,无法选择或搜索。实质上,PDF文件只是这些图像的容器。
- 带有OCR的扫描文档:在这种情况下,扫描文档后使用光学字符识别(OCR)软件来识别文件中每个图像中的文本,并将其转换为可搜索和可编辑的文本。然后,软件在图像上添加一个包含实际文本的层,这样当浏览文件时,您可以将其选择为单独的组件(3)。
尽管现在越来越多的机器都安装了OCR系统来识别扫描文档中的文本,但仍然存在一些包含整个页面的图像格式文档。您可能已经看到过,当您阅读一篇精彩的文章并尝试选择一句话时,却选择了整个页面。这可能是特定OCR机器的限制或其完全缺失的结果。为了不让这些信息在本文中被忽视,我试图创建一个考虑到这些情况并充分利用我们宝贵且信息丰富的PDF的过程。
理论方法
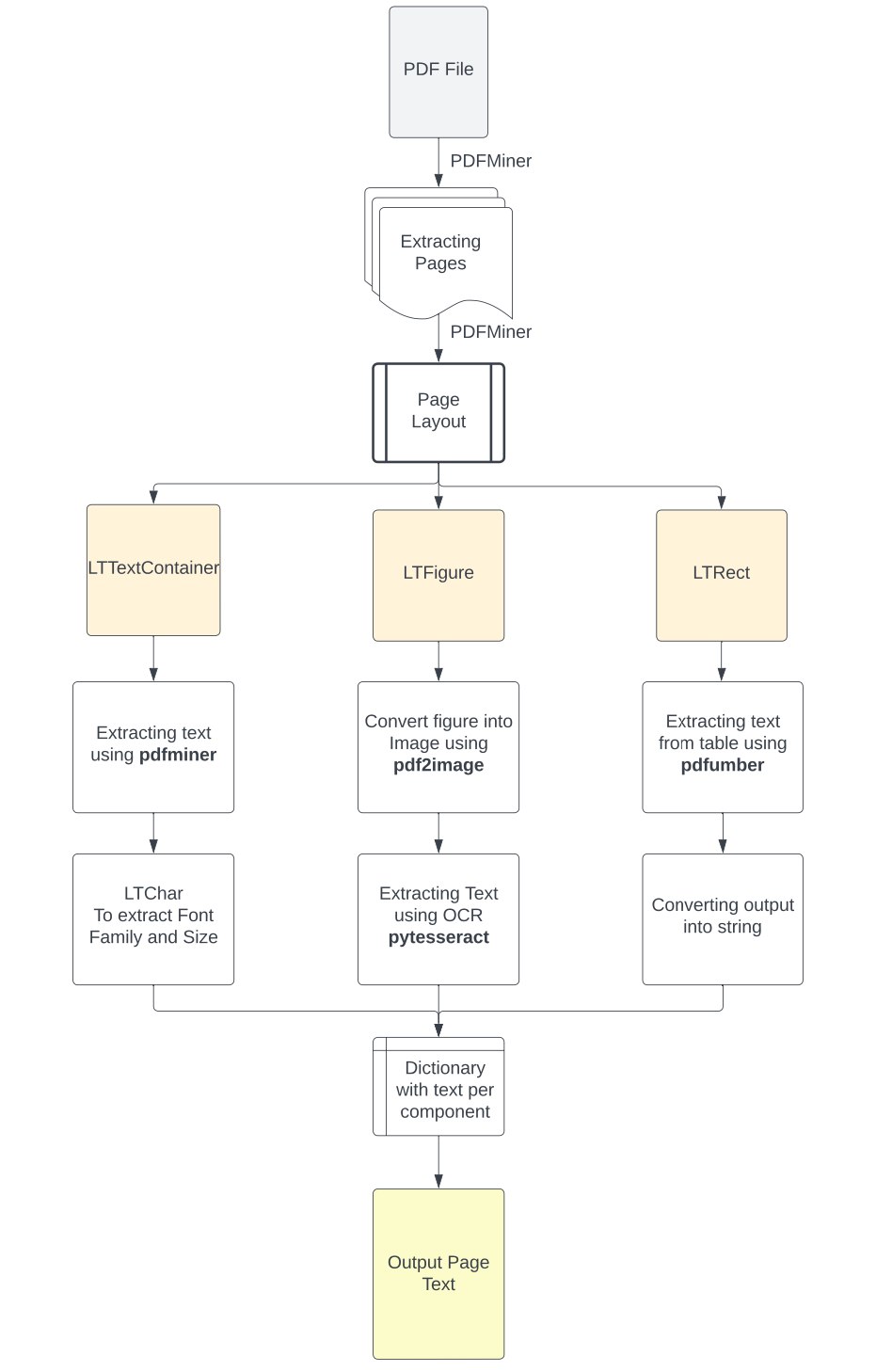
在考虑到所有这些不同类型的PDF文件和构成它们的各种元素的基础上,进行对PDF布局的初步分析以识别每个组件所需的适当工具非常重要。更具体地说,根据这一分析的结果,我们将应用适当的方法从PDF中提取文本,无论是呈现在语料库块中的文本及其元数据、图像中的文本还是表格中的结构化文本。在没有OCR的扫描文档中,识别并从图像中提取文本的方法将完成所有繁重的工作。该过程的输出将是一个Python字典,其中包含从PDF文件的每一页提取的信息。该字典中的每个键将呈现文档的页码,其对应的值将是包含以下5个嵌套列表的列表:
- 语料库块的每个文本块提取的文本
- 每个文本块中文本的字体系列和大小的格式
- 页面上提取的图像中的文本
- 以结构化格式提取的表格中的文本
- 页面的完整文本内容

通过这种方式,我们可以更合理地将从不同源组件中提取的文本分离开,有时可以帮助我们更容易地检索通常出现在特定组件中的信息(例如,标志图像中的公司名称)。此外,从文本中提取的元数据,如字体系列和大小,可以用于轻松识别文本标题或更重要的突出文本,从而帮助我们进一步将文本分成多个不同的块进行后处理。最后,在LLM能够理解的方式中保留结构化表格信息将显著增强对提取数据内关系的推断质量。然后,这些结果可以组合成一个输出,包含每一页上出现的所有文本信息。
您可以在下面的图像中看到这种方法的流程图。
安装所有必要的库
在开始这个项目之前,我们应该安装所需的库。我们假设您的计算机上已经安装了Python 3.10或更高版本。否则,您可以从这里安装。然后让我们安装以下库:
PyPDF2:用于从存储库路径读取PDF文件。
pip install PyPDF2
Pdfminer:用于执行布局分析并从PDF中提取文本和格式(该库的.six版本是支持Python 3的版本)。
pip install pdfminer.six
Pdfplumber:用于识别PDF页面中的表格并从中提取信息。
pip install pdfplumber
Pdf2image:用于将裁剪后的PDF图像转换为PNG图像。
pip install pdf2image
PIL:用于读取PNG图像。
pip install Pillow
Pytesseract:使用OCR技术从图像中提取文本。
这个安装稍微复杂,因为首先您需要安装Google Tesseract OCR,这是一种基于LSTM模型的OCR机器,用于识别行和字符模式。
如果您是Mac用户,您可以通过终端使用Brew来安装,然后即可使用。
brew install tesseract
对于Windows用户,您可以按照这个链接中的步骤进行安装。然后,当您下载并安装软件时,您需要将其可执行路径添加到计算机的环境变量中。或者,您可以运行以下命令,直接在Python脚本中使用以下代码将其路径包含进去:
pytesseract.pytesseract.tesseract_cmd = r'C:Program FilesTesseract-OCRtesseract.exe'
然后您可以安装Python库。
pip install pytesseract
最后,我们将在脚本的开头导入所有的库。
# To read the PDF
import PyPDF2
# To analyze the PDF layout and extract text
from pdfminer.high_level import extract_pages, extract_text
from pdfminer.layout import LTTextContainer, LTChar, LTRect, LTFigure
# To extract text from tables in PDF
import pdfplumber
# To extract the images from the PDFs
from PIL import Image
from pdf2image import convert_from_path
# To perform OCR to extract text from images
import pytesseract
# To remove the additional created files
import os
现在我们已经准备好了。让我们进入有趣的部分。
使用Python进行文档布局分析

在初步分析中,我们使用了PDFMiner Python库,将文档对象中的文本分离为多个页面对象,然后分解和检查每个页面的布局。PDF文件本质上缺乏结构化信息,如人眼看到的段落、句子或单词。相反,它们只理解文本的单个字符以及它们在页面上的位置。因此,PDFMiner试图将页面的内容重构为其个体字符以及它们在文件中的位置。然后,通过比较这些字符与其他字符的距离,它组合成适当的单词、句子、行和段落的文本(4)。为了实现这一点,该库:
使用高级函数extract_pages()将PDF文件中的各个页面分离,并将它们转换为LTPage对象。
对于每个LTPage对象,它从上到下迭代每个元素,并尝试识别适当的组件,包括:
LTFigure:表示PDF中可以呈现为图形或图像的区域,这些图形或图像已嵌入到页面中作为另一个PDF文档。LTTextContainer:表示矩形区域内的一组文本行,然后进一步分析为LTTextLine对象列表。每个LTTextLine对象表示一个LTChar对象列表,它存储文本的单个字符及其元数据(5)。LTRect:表示可用于框架图像和图形或在LTPage对象中创建表格的二维矩形。
基于对页面的这种重构以及将其元素分类为LTFigure(包含页面上的图像或图形)、LTTextContainer(表示页面的文本信息)或LTRect(表明存在表格的强烈迹象),我们可以应用适当的函数更好地提取信息。
for pagenum, page in enumerate(extract_pages(pdf_path)):
# Iterate the elements that composed a page
for element in page:
# Check if the element is a text element
if isinstance(element, LTTextContainer):
# Function to extract text from the text block
pass
# Function to extract text format
pass
# Check the elements for images
if isinstance(element, LTFigure):
# Function to convert PDF to Image
pass
# Function to extract text with OCR
pass
# Check the elements for tables
if isinstance(element, LTRect):
# Function to extract table
pass
# Function to convert table content into a string
pass
因此,现在我们理解了流程分析的部分,让我们创建从每个组件中提取文本所需的函数。
定义从PDF中提取文本的函数
从这里开始,从文本容器中提取文本非常简单。
# Create a function to extract text
def text_extraction(element):
# Extracting the text from the in-line text element
line_text = element.get_text()
# Find the formats of the text
# Initialize the list with all the formats that appeared in the line of text
line_formats = []
for text_line in element:
if isinstance(text_line, LTTextContainer):
# Iterating through each character in the line of text
for character in text_line:
if isinstance(character, LTChar):
# Append the font name of the character
line_formats.append(character.fontname)
# Append the font size of the character
line_formats.append(character.size)
# Find the unique font sizes and names in the line
format_per_line = list(set(line_formats))
# Return a tuple with the text in each line along with its format
return (line_text, format_per_line)
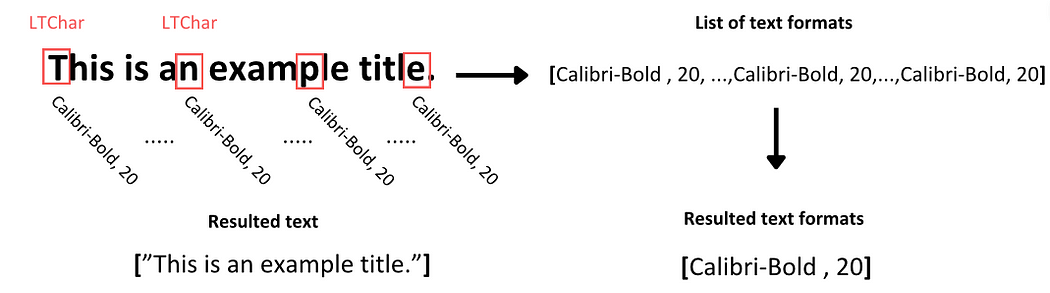
要从文本容器中提取文本,我们只需使用LTTextContainer元素的get_text()方法。此方法检索构成特定语料库框内单词的所有字符,并将输出存储在文本数据列表中。此列表中的每个元素代表容器中包含的原始文本信息。
现在,为了识别此文本的格式,我们迭代LTTextContainer对象以逐个访问此语料库的每一行。在每次迭代中,都会创建一个新的LTTextLine对象,表示此语料块中的文本行。然后,我们检查嵌套的行元素是否包含文本。如果包含,我们访问每个单独的字符元素,即LTChar,其中包含该字符的所有元数据。从这些元数据中,我们提取两种格式,并将它们存储在一个分开的列表中,相应地放置在检查的文本中:
- 字符的字体系列,包括字符是否以粗体或斜体格式显示。
- 字符的字体大小。
通常,特定文本块中的字符往往具有一致的格式,除非某些字符以粗体突出显示。为了便于进一步分析,我们为文本中的所有字符捕获文本格式的唯一值,并将它们存储在适当的列表中。
定义从图像中提取文本的函数
在这里,我认为这是一个更棘手的部分。
如何处理在PDF中找到的图像中的文本?
首先,我们需要在这里明确,存储在PDF中的图像元素并不是与文件(如JPEG或PNG)不同的格式。因此,为了在它们上应用OCR软件,我们需要首先将它们从文件中分离出来,然后将它们转换为图像格式。
# Create a function to crop the image elements from PDFs
def crop_image(element, pageObj):
# Get the coordinates to crop the image from the PDF
[image_left, image_top, image_right, image_bottom] = [element.x0,element.y0,element.x1,element.y1]
# Crop the page using coordinates (left, bottom, right, top)
pageObj.mediabox.lower_left = (image_left, image_bottom)
pageObj.mediabox.upper_right = (image_right, image_top)
# Save the cropped page to a new PDF
cropped_pdf_writer = PyPDF2.PdfWriter()
cropped_pdf_writer.add_page(pageObj)
# Save the cropped PDF to a new file
with open('cropped_image.pdf', 'wb') as cropped_pdf_file:
cropped_pdf_writer.write(cropped_pdf_file)
# Create a function to convert the PDF to images
def convert_to_images(input_file,):
images = convert_from_path(input_file)
image = images[0]
output_file = "PDF_image.png"
image.save(output_file, "PNG")
# Create a function to read text from images
def image_to_text(image_path):
# Read the image
img = Image.open(image_path)
# Extract the text from the image
text = pytesseract.image_to_string(img)
return text
为实现此目的,我们遵循以下过程:
- 我们使用从PDFMiner检测到的LTFigure对象的元数据来裁剪图像框,利用其在页面布局中的坐标。然后,我们使用PyPDF2库将其保存为我们目录中的新PDF。
- 然后,我们使用pdf2image库的convert_from_file()函数将目录中的所有PDF文件转换为图像列表,并以PNG格式保存它们。
- 最后,现在我们有了图像文件,我们在脚本中使用PIL模块的Image包读取它们,并使用pytesseract的image_to_string()函数从图像中提取文本,使用tesseract OCR引擎。
因此,这个过程返回图像中的文本,然后我们将其保存在输出字典中的第三个列表中。此列表包含从所检查页面上提取的图像中的文本信息。
定义从表格中提取文本的函数
在本节中,我们将从PDF页面的表格中提取更有逻辑结构的文本。这比从语料中提取文本稍微复杂,因为我们需要考虑信息的粒度和表格中呈现的数据点之间形成的关系。
虽然有几个用于从PDF中提取表格数据的库,其中Tabula-py是最知名的之一,但我们发现了它们功能上的某些限制。
我们认为最明显的限制之一来自该库使用表格文本中的换行特殊字符n 来识别表格的不同行。这在大多数情况下运作良好,但当单元格中的文本包装到2行或更多行时,它无法正确捕获,导致添加不必要的空行并丢失提取的单元格的上下文。
您可以看到下面的示例,当我们尝试使用tabula-py从表格中提取数据时的情况:
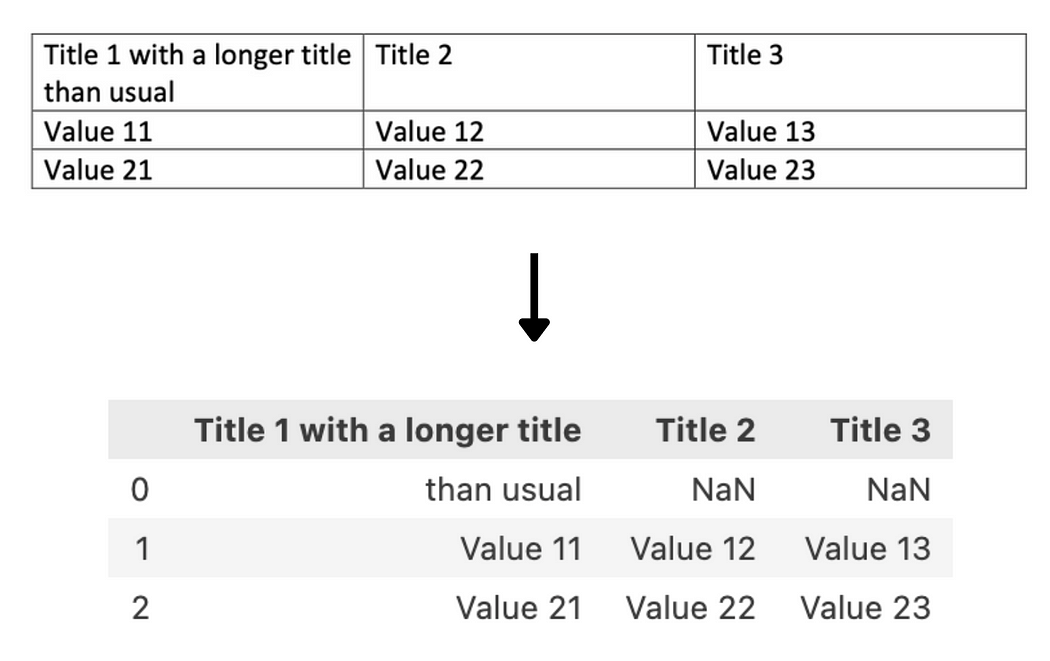
然后,提取的信息以Pandas DataFrame的形式输出,而不是字符串。在大多数情况下,这可能是一种理想的格式,但在考虑文本的转换器的情况下,这些结果需要在馈入模型之前进行转换。
因此,为了解决这个任务,我们使用pdfplumber库,原因有几个。首先,它是基于我们用于初步分析的pdfminer.six构建的,这意味着它包含类似的对象。此外,它的表格检测方法基于线元素及其交叉点来构造包含文本的单元格,然后是表格本身。因此,在我们识别表格的单元格后,我们可以提取单元格内的内容,而无需关心需要渲染多少行。然后,当我们有了表格的内容时,我们将其格式化为类似表格的字符串,并将其存储在适当的列表中。
# Extracting tables from the page
def extract_table(pdf_path, page_num, table_num):
# Open the pdf file
pdf = pdfplumber.open(pdf_path)
# Find the examined page
table_page = pdf.pages[page_num]
# Extract the appropriate table
table = table_page.extract_tables()[table_num]
return table
# Convert table into the appropriate format
def table_converter(table):
table_string = ''
# Iterate through each row of the table
for row_num in range(len(table)):
row = table[row_num]
# Remove the line breaker from the wrapped texts
cleaned_row = [item.replace('n', ' ') if item is not None and 'n' in item else 'None' if item is None else item for item in row]
# Convert the table into a string
table_string+=('|'+'|'.join(cleaned_row)+'|'+'n')
# Removing the last line break
table_string = table_string[:-1]
return table_string
为此,我们创建了两个函数,extract_table() 用于将表格的内容提取到一个嵌套列表中,table_converter() 用于将这些列表的内容连接成类似表格的字符串。
在extract_table() 函数中:
- 我们打开PDF文件。
- 我们导航到PDF文件的受检查页面。
- 从pdfplumber找到的页面上的表格列表中,我们选择所需的表格。
- 我们提取表格的内容并将其输出为表示表格每一行的嵌套列表。
在table_converter() 函数中:
- 我们在每个嵌套列表中迭代,并从任何包含来自任何换行文本的不需要的行断开其上下文。
- 我们使用 | 符号将行的每个元素分隔以创建表格单元格的结构。
- 最后,我们在最后添加一个换行符以移动到下一行。
这将生成一个文本字符串,呈现表格的内容,而不会失去其中呈现的数据的细粒度。
汇总所有内容
现在,我们已经准备好了代码的所有组件,让我们将它们全部组合成一个完全功能的代码。您可以从这里复制代码,或者您可以在我的GitHub仓库中找到代码以及示例PDF。
# Find the PDF path
pdf_path = 'OFFER 3.pdf'
# create a PDF file object
pdfFileObj = open(pdf_path, 'rb')
# create a PDF reader object
pdfReaded = PyPDF2.PdfReader(pdfFileObj)
# Create the dictionary to extract text from each image
text_per_page = {}
# We extract the pages from the PDF
for pagenum, page in enumerate(extract_pages(pdf_path)):
# Initialize the variables needed for the text extraction from the page
pageObj = pdfReaded.pages[pagenum]
page_text = []
line_format = []
text_from_images = []
text_from_tables = []
page_content = []
# Initialize the number of the examined tables
table_num = 0
first_element= True
table_extraction_flag= False
# Open the pdf file
pdf = pdfplumber.open(pdf_path)
# Find the examined page
page_tables = pdf.pages[pagenum]
# Find the number of tables on the page
tables = page_tables.find_tables()
# Find all the elements
page_elements = [(element.y1, element) for element in page._objs]
# Sort all the elements as they appear in the page
page_elements.sort(key=lambda a: a[0], reverse=True)
# Find the elements that composed a page
for i,component in enumerate(page_elements):
# Extract the position of the top side of the element in the PDF
pos= component[0]
# Extract the element of the page layout
element = component[1]
# Check if the element is a text element
if isinstance(element, LTTextContainer):
# Check if the text appeared in a table
if table_extraction_flag == False:
# Use the function to extract the text and format for each text element
(line_text, format_per_line) = text_extraction(element)
# Append the text of each line to the page text
page_text.append(line_text)
# Append the format for each line containing text
line_format.append(format_per_line)
page_content.append(line_text)
else:
# Omit the text that appeared in a table
pass
# Check the elements for images
if isinstance(element, LTFigure):
# Crop the image from the PDF
crop_image(element, pageObj)
# Convert the cropped pdf to an image
convert_to_images('cropped_image.pdf')
# Extract the text from the image
image_text = image_to_text('PDF_image.png')
text_from_images.append(image_text)
page_content.append(image_text)
# Add a placeholder in the text and format lists
page_text.append('image')
line_format.append('image')
# Check the elements for tables
if isinstance(element, LTRect):
# If the first rectangular element
if first_element == True and (table_num+1) <= len(tables):
# Find the bounding box of the table
lower_side = page.bbox[3] - tables[table_num].bbox[3]
upper_side = element.y1
# Extract the information from the table
table = extract_table(pdf_path, pagenum, table_num)
# Convert the table information in structured string format
table_string = table_converter(table)
# Append the table string into a list
text_from_tables.append(table_string)
page_content.append(table_string)
# Set the flag as True to avoid the content again
table_extraction_flag = True
# Make it another element
first_element = False
# Add a placeholder in the text and format lists
page_text.append('table')
line_format.append('table')
# Check if we already extracted the tables from the page
if element.y0 >= lower_side and element.y1 <= upper_side:
pass
elif not isinstance(page_elements[i+1][1], LTRect):
table_extraction_flag = False
first_element = True
table_num+=1
# Create the key of the dictionary
dctkey = 'Page_'+str(pagenum)
# Add the list of list as the value of the page key
text_per_page[dctkey]= [page_text, line_format, text_from_images,text_from_tables, page_content]
# Closing the pdf file object
pdfFileObj.close()
# Deleting the additional files created
os.remove('cropped_image.pdf')
os.remove('PDF_image.png')
# Display the content of the page
result = ''.join(text_per_page['Page_0'][4])
print(result)
上述脚本将执行以下操作:
导入必要的库。
使用pyPDF2库打开PDF文件。
提取PDF的每一页并迭代以下步骤。
检查页面上是否有表格,并使用pdfplumner创建一个表格列表。
找到页面中的所有嵌套元素并按其在布局中出现的顺序排序。
然后,对于每个元素:
检查它是否是文本容器,并且不出现在表格元素中。然后使用text_extraction()函数提取文本以及其格式,否则跳过此文本。
检查它是否是图像,并使用crop_image()函数从PDF中裁剪图像组件,使用convert_to_images()将其转换为图像文件,并使用image_to_text()函数从中提取文本。
检查它是否是矩形元素。在这种情况下,我们检查第一个rect是否是页面表格的一部分,如果是,则执行以下步骤:
- 找到表格的边界框,以防止使用text_extraction()函数再次提取其文本。
- 提取表格的内容并将其转换为字符串。
- 然后添加一个布尔参数以明确我们从表格中提取文本。
- 此过程将在最后一个LTRect落入表格的边界框并且布局中的下一个元素不是矩形对象时结束。(组成表格的其他对象将被忽略)
将该过程的输出存储在每次检查时表示的页面编号的字典中,每次迭代都有5个列表,命名为:
- page_text:包含来自PDF文本容器的文本(当文本是从其他元素提取时,将放置占位符)。
- line_format:包含上面提取的文本的格式(当文本是从其他元素提取时,将放置占位符)。
- text_from_images:包含从页面上提取的图像中提取的文本。
- text_from_tables:包含具有表格内容的类似表格的字符串。
- page_content:包含以元素列表形式呈现在页面上的所有文本。
然后,我们将关闭PDF文件。
接下来,我们将删除在过程中创建的所有附加文件。
最后,我们可以通过连接page_content列表的元素来显示页面的内容。
结论
这是我认为使用许多库的最佳特性并使该过程对我们可能遇到的各种类型的PDF和元素具有韧性的一种方法,尽管PDFMiner为大部分繁重的工作提供了支持。此外,关于文本格式的信息可以帮助我们识别可能的标题,将文本分隔成不同的逻辑部分,而不仅仅是每页的内容,并且可以帮助我们识别更重要的文本。
然而,总会有更有效的方法来执行此任务,尽管我认为这种方法更具包容性,但我真的很期待与您讨论解决此问题的新方法和更好的方法。
参考引用
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/89412.html