
第一部分请查看从环境设置到内存分析。以下是 Python 代码优化的第二部分,主要从 Python 脚本与 Python 解释器两个方面阐述。在这一部分中我们首先会关注如何追踪 Python 脚本的 CPU 使用情况,并重点讨论 cProfile、line_profiler、pprofile 和 vprof。而后一部分重点介绍了一些可用于在运行 Python 脚本时对解释器进行性能分析的工具和方法,主要讨论了 CPython 和 PyPy 等。
CPU 分析——Python 脚本
在这一节,我将介绍一些有助于我们解决 Python 中分析 CPU 使用的难题的工具。
CPU 性能分析(profiling)的意思是通过分析 CPU 执行代码的方式来分析这些代码的性能。也就是说要找到我们代码中的热点(hot spot),然后看我们可以怎么处理它们。
接下来我们会看看你可以如何追踪你的 Python 脚本的 CPU 使用。我们将关注以下分析器(profiler):
- cProfile
- line_profiler
- pprofile
- vprof
测量 CPU 使用
import timedef primes(n):if n == 2:return [2]elif n < 2:return []s = []for i in range(3, n+1):if i % 2 != 0:s.append(i)mroot = n ** 0.5half = (n + 1) / 2 - 1i = 0m = 3while m <= mroot:if s[i]:j = (m * m - 3) / 2s[j] = 0while j < half:s[j] = 0j += mi = i + 1m = 2 * i + 3l = [2]for x in s:if x:l.append(x)return ldef benchmark():start = time.time()for _ in xrange(40):count = len(primes(1000000))end = time.time()print "Benchmark duration: %r seconds" % (end-start)benchmark()
这一节我将使用与前一节基本一样的脚本,你也可以在 GitHub 上查看:https://gist.github.com/apatrascu/8524679175de08a54a95e22001a31d3b
另外,记住在 PyPy2 上,你需要使用一个支持它的 pip 版本:
pypy -m ensure pip
其它东西可以通过以下指令安装:
pypy -m pip install
cProfile
在 CPU 性能分析上最常用的一个工具是 cProfile,主要是因为它内置于 CPython2 和 PyPy2 中。这是一个确定性的分析器,也就是说它会在运行我们的负载时收集一系列统计数据,比如代码各个部分的执行次数或执行时间。此外,相比于其它内置的分析器(profile 或 hotshot),cProfile 对系统的开销更少。
当使用 CPython2 时,其使用方法是相当简单的:
python -m cProfile 03.primes-v1.py
如果你使用的是 PyPy2:
pypy -m cProfile 03.primes-v1.py
其输出如下:
Benchmark duration: 30.11158514022827 seconds23139965 function calls in 30.112 secondsOrdered by: standard namencalls tottime percall cumtime percall filename:lineno(function)1 0.000 0.000 30.112 30.112 03.primes.py:1(<module>)40 19.760 0.494 29.896 0.747 03.primes.py:3(primes)1 0.216 0.216 30.112 30.112 03.primes.py:31(benchmark)40 0.000 0.000 0.000 0.000 {len}23139840 6.683 0.000 6.683 0.000 {method 'append' of 'list' objects}1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}40 3.453 0.086 3.453 0.086 {range}2 0.000 0.000 0.000 0.000 {time.time}
即使是这样的文本输出,我们也可以直接看到我们脚本的大多数时间都在调用 list.append 方法。
如果我们使用 gprof2dot,我们可以用图形化的方式来查看 cProfile 的输出。要使用这个工具,我们首先必须安装 graphviz。在 Ubuntu 上,可以使用以下命令:
apt-get install graphvizpip install gprof2dot
再次运行我们的脚本:
python -m cProfile -o output.pstats 03.primes-v1.pygprof2dot -f pstats output.pstats | dot -Tpng -o output.png
然后我们会得到下面的 output.png 文件:
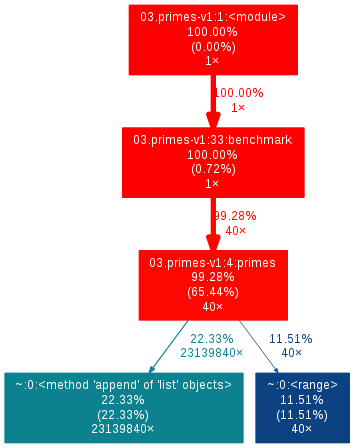
这样看起来就轻松多了。让我们仔细看看它输出了什么。你可以看到来自脚本的函数调用图(callgraph)。在每个方框中,你可以一行一行地看到:
- 第一行:Python 文件名、行数和方法名
- 第二行:这个方框所用的时间占全局时间的比例
- 第三行:括号中是该方法本身所用时间占全局时间的比例
- 第四行:调用次数
比如说,在从上到下第三个红色框中,方法 primes 占用了 98.28% 的时间,65.44% 的时间是在该方法之中做什么事情,它被调用了 40 次。剩下的时间被用在了 Python 的 list.append(22.33%)和 range(11.51%)方法中。
这是一个简单的脚本,所以我们只需要重写我们的脚本,让它不用使用那么多的 append 方法,结果如下:
import timedef primes(n):if n==2:return [2]elif n<2:return []s=range(3,n+1,2)mroot = n ** 0.5half=(n+1)/2-1i=0m=3while m <= mroot:if s[i]:j=(m*m-3)/2s[j]=0while j<half:s[j]=0j+=mi=i+1m=2*i+3return [2]+[x for x in s if x]def benchmark():start = time.time()for _ in xrange(40):count = len(primes(1000000))end = time.time()print "Benchmark duration: %r seconds" % (end-start)benchmark()
以下测试了脚本在使用前和使用 CPython2 后的运行时间:
python 03.primes-v1.pyBenchmark duration: 15.768115043640137 secondspython 03.primes-v2.pyBenchmark duration: 6.56312108039856 seconds
用 PyPy2 测量:
pypy 03.primes-v1.pyBenchmark duration: 1.4009230136871338 secondspypy 03.primes-v2.pyBenchmark duration: 0.4542720317840576 seconds
我们在 CPython2 上得到了 2.4 倍的提升,在 PyPy2 上得到了 3.1 倍的提升。很不错,其 cProfile 调用图为:

你也可以以程序的方式查看 cProfile:
import cProfilepr = cProfile.Profile()pr.enable()function_to_measure()pr.disable()pr.print_stats(sort='time')
这在一些场景中很有用,比如多进程性能测量。更多详情请参阅:https://docs.python.org/2/library/profile.html#module-cProfile
line_profiler
这个分析器可以提供逐行水平的负载信息。这是通过 C 语言用 Cython 实现的,与 cProfile 相比计算开销更少。
其源代码可在 GitHub 上获取:https://github.com/rkern/line_profiler,PyPI 页面为:https://pypi.python.org/pypi/line_profiler/。和 cProfile 相比,它有相当大的开销,需要多 12 倍的时间才能得到一个分析结果。
要使用这个工具,你首先需要通过 pip 添加:pip install pip install Cython ipython==5.4.1 line_profiler(CPython2)。这个分析器的一个主要缺点是不支持 PyPy。
就像在使用 memory_profiler 时一样,你需要在你想分析的函数上加上一个装饰。在我们的例子中,你需要在 03.primes-v1.py 中的 primes 函数的定义前加上 @profile。然后像这样调用:
kernprof -l 03.primes-v1.pypython -m line_profiler 03.primes-v1.py.lprof
你会得到一个这样的输出:
Timer unit: 1e-06 sTotal time: 181.595 sFile: 03.primes-v1.pyFunction: primes at line 3Line # Hits Time Per Hit % Time Line Contents==============================================================3 @profile4 def primes(n):5 40 107 2.7 0.0 if n == 2:6 return [2]7 40 49 1.2 0.0 elif n < 2:8 return []9 40 44 1.1 0.0 s = []10 39999960 34410114 0.9 18.9 for i in range(3, n+1):11 39999920 29570173 0.7 16.3 if i % 2 != 0:12 19999960 14976433 0.7 8.2 s.append(i)13 40 329 8.2 0.0 mroot = n ** 0.514 40 82 2.0 0.0 half = (n + 1) / 2 - 115 40 46 1.1 0.0 i = 016 40 30 0.8 0.0 m = 317 20000 17305 0.9 0.0 while m <= mroot:18 19960 16418 0.8 0.0 if s[i]:19 6680 6798 1.0 0.0 j = (m * m - 3) / 220 6680 6646 1.0 0.0 s[j] = 021 32449400 22509523 0.7 12.4 while j < half:22 32442720 26671867 0.8 14.7 s[j] = 023 32442720 22913591 0.7 12.6 j += m24 19960 15078 0.8 0.0 i = i + 125 19960 16170 0.8 0.0 m = 2 * i + 326 40 87 2.2 0.0 l = [2]27 20000000 14292643 0.7 7.9 for x in s:28 19999960 13753547 0.7 7.6 if x:29 3139880 2417421 0.8 1.3 l.append(x)30 40 33 0.8 0.0 return l
我们可以看到两个循环在反复调用 list.append,占用了脚本的大部分时间。
pprofile
地址:http://github.com/vpelletier/pprofile
据作者介绍,pprofile 是一个「行粒度的、可感知线程的确定性和统计性纯 Python 分析器」。
它的灵感来源于 line_profiler,修复了大量缺陷,但因为其完全是用 Python 写的,所以也可以通过 PyPy 使用。和 cProfile 相比,使用 CPython 时分析的时间会多 28 倍,使用 PyPy 时的分析时间会长 10 倍,但具有粒度更大的细节水平。
而且还支持 PyPy 了!除此之外,它还支持线程分析,这在很多情况下都很有用。
要使用这个工具,你首先需要通过 pip 安装:pip install pprofile(CPython2)/ pypy -m pip install pprofile(PyPy),然后像这样调用:
pprofile 03.primes-v1.py
其输出和前面工具的输出不同,如下:
886.8774709701538 secondsCommand line: ['03.primes-v1.py']Total duration: 886.878sFile: 03.primes-v1.pyFile duration: 886.878s (100.00%)Line #| Hits| Time| Time per hit| %|Source code------+----------+-------------+-------------+-------+-----------1| 2| 7.10487e-05| 3.55244e-05| 0.00%|import time2| 0| 0| 0| 0.00%|3| 0| 0| 0| 0.00%|4| 41| 0.00029397| 7.17e-06| 0.00%|def primes(n):5| 40| 0.000231266| 5.78165e-06| 0.00%| if n == 2:6| 0| 0| 0| 0.00%| return [2]7| 40| 0.000178337| 4.45843e-06| 0.00%| elif n < 2:8| 0| 0| 0| 0.00%| return []9| 40| 0.000188112| 4.70281e-06| 0.00%| s = []10| 39999960| 159.268| 3.98171e-06| 17.96%| for i in range(3, n+1):11| 39999920| 152.924| 3.82312e-06| 17.24%| if i % 2 != 0:12| 19999960| 76.2135| 3.81068e-06| 8.59%| s.append(i)13| 40| 0.00147367| 3.68416e-05| 0.00%| mroot = n ** 0.514| 40| 0.000319004| 7.9751e-06| 0.00%| half = (n + 1) / 2 - 115| 40| 0.000220776| 5.51939e-06| 0.00%| i = 016| 40| 0.000243902| 6.09756e-06| 0.00%| m = 317| 20000| 0.0777466| 3.88733e-06| 0.01%| while m <= mroot:18| 19960| 0.0774016| 3.87784e-06| 0.01%| if s[i]:19| 6680| 0.0278566| 4.17015e-06| 0.00%| j = (m * m - 3) / 220| 6680| 0.0275929| 4.13067e-06| 0.00%| s[j] = 021| 32449400| 114.858| 3.5396e-06| 12.95%| while j < half:22| 32442720| 120.841| 3.72475e-06| 13.63%| s[j] = 023| 32442720| 114.432| 3.5272e-06| 12.90%| j += m24| 19960| 0.0749919| 3.75711e-06| 0.01%| i = i + 125| 19960| 0.0765574| 3.83554e-06| 0.01%| m = 2 * i + 326| 40| 0.000222206| 5.55515e-06| 0.00%| l = [2]27| 20000000| 68.8031| 3.44016e-06| 7.76%| for x in s:28| 19999960| 67.9391| 3.39696e-06| 7.66%| if x:29| 3139880| 10.9989| 3.50295e-06| 1.24%| l.append(x)30| 40| 0.000155687| 3.89218e-06| 0.00%| return l31| 0| 0| 0| 0.00%|32| 0| 0| 0| 0.00%|33| 2| 8.10623e-06| 4.05312e-06| 0.00%|def benchmark():34| 1| 5.00679e-06| 5.00679e-06| 0.00%| start = time.time()35| 41| 0.00101089| 2.4656e-05| 0.00%| for _ in xrange(40):36| 40| 0.232263| 0.00580657| 0.03%| count = len(primes(1000000))(call)| 40| 886.644| 22.1661| 99.97%|# 03.primes-v1.py:4 primes37| 1| 5.96046e-06| 5.96046e-06| 0.00%| end = time.time()38| 1| 0.000678062| 0.000678062| 0.00%| print "Benchmark duration: %r seconds" % (end-start)39| 0| 0| 0| 0.00%|40| 0| 0| 0| 0.00%|41| 1| 5.79357e-05| 5.79357e-05| 0.00%|benchmark()(call)| 1| 886.878| 886.878|100.00%|# 03.primes-v1.py:33 benchmark
我们现在可以看到更详细的细节。让我们稍微研究一下这个输出。这是这个脚本的整个输出,每一行你可以看到调用的次数、运行它所用的时间(秒)、每次调用的时间和占全局时间的比例。此外,pprofile 还为我们的输出增加了额外的行(比如 44 和 50 行,行前面写着 (call)),这是累积指标。
同样,我们可以看到有两个循环在反复调用 list.append,占用了脚本的大部分时间。
vprof
地址:https://github.com/nvdv/vprof
vprof 是一个 Python 分析器,为各种 Python 程序特点提供了丰富的交互式可视化,比如运行时间和内存使用。这是一个图形化工具,基于 Node.JS,可在网页上展示结果。
使用这个工具,你可以针对相关 Python 脚本查看下面的一项或多项内容:
- CPU flame graph
- 代码分析(code profiling)
- 内存图(memory graph)
- 代码热图(code heatmap)
要使用这个工具,你首先需要通过 pip 安装:pip install vprof(CPython2)/ pypy -m pip install vprof(PyPy),然后像这样调用:
在 CPython2 上,要显示代码热图(下面的第一行调用)和代码分析(下面的第二行调用):
vprof -c h 03.primes-v1.pyvprof -c p 03.primes-v1.py
在 PyPy 上,要显示代码热图(下面的第一行调用)和代码分析(下面的第二行调用):
pypy -m vprof -c h 03.primes-v1.pypypy -m vprof -c p 03.primes-v1.py
在上面的两个例子中,你都会看到如下的代码热图:
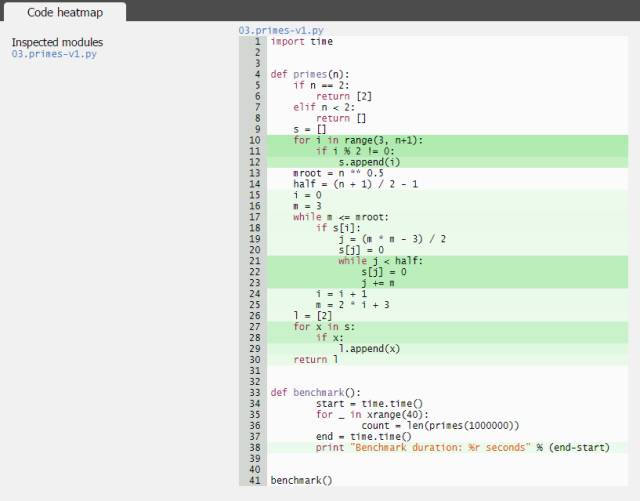
以及如下的代码分析:

结果是以图形化的方式展示的,你可以将鼠标悬浮或点击每一行,从而查看更多信息。同样,我们可以看到有两个循环在反复调用 list.append 方法,占用了脚本的大部分时间。
CPU 分析——Python 解释器
在这一节,我将介绍一些可用于在运行 Python 脚本时对解释器进行性能分析的工具和方法。
正如前几节提到的,CPU 性能分析的意义是一样的,但现在我们的目标不是 Python 脚本。我们现在想要知道 Python 解释器的工作方式,以及 Python 脚本运行时在哪里消耗的时间最多。
接下来我们将看到你可以怎样跟踪 CPU 使用情况以及找到解释器中的热点。
测量 CPU 使用情况
这一节所使用的脚本基本上和前面内存分析和脚本 CPU 使用情况分析时使用的脚本一样,你也可以在这里查阅代码:https://gist.github.com/apatrascu/44f0c6427e2df96951034b759e16946f
import timedef primes(n):if n == 2:return [2]elif n < 2:return []s = []for i in range(3, n+1):if i % 2 != 0:s.append(i)mroot = n ** 0.5half = (n + 1) / 2 - 1i = 0m = 3while m <= mroot:if s[i]:j = (m * m - 3) / 2s[j] = 0while j < half:s[j] = 0j += mi = i + 1m = 2 * i + 3l = [2]for x in s:if x:l.append(x)return ldef benchmark():start = time.time()for _ in xrange(40):count = len(primes(1000000))end = time.time()print "Benchmark duration: %r seconds" % (end-start)benchmark()
优化后的版本见下面或访问:https://gist.github.com/apatrascu/ee660bf95469a55e5947a0066e930a69
import timedef primes(n):if n==2:return [2]elif n<2:return []s=range(3,n+1,2)mroot = n ** 0.5half=(n+1)/2-1i=0m=3while m <= mroot:if s[i]:j=(m*m-3)/2s[j]=0while j<half:s[j]=0j+=mi=i+1m=2*i+3return [2]+[x for x in s if x]def benchmark():start = time.time()for _ in xrange(40):count = len(primes(1000000))end = time.time()print "Benchmark duration: %r seconds" % (end-start)benchmark()
CPython
CPython 的功能很多,这是完全用 C 语言写的,因此在测量和/或性能分析上可以更加容易。你可以找到托管在 GitHub 上的 CPython 资源:https://github.com/python/cpython。默认情况下,你会看到最新的分支,在本文写作时是 3.7+ 版本,但向前一直到 2.7 版本的分支都能找到。
在这篇文章中,我们的重点是 CPython 2,但最新的第 3 版也可成功应用同样的步骤。
1. 代码覆盖工具(Code coverage tool)
要查看正在运行的 C 语言代码是哪一部分,最简单的方法是使用代码覆盖工具。
首先我们克隆这个代码库:
git clone https://github.com/python/cpython/cd cpythongit checkout 2.7./configure
复制该目录中的脚本并运行以下命令:
make coverage./python 04.primes-v1.pymake coverage-lcov
第一行代码将会使用 GCOV 支持(https://gcc.gnu.org/onlinedocs/gcc/Gcov.html)编译该解释器,第二行将运行负载并收集在 .gcda 文件中的分析数据,第三行代码将解析包含这些分析数据的文件并在名为 lcov-report 的文件夹中创建一些 HTML 文件。
如果我们在浏览器中打开 index.html,我们会看到为了运行我们的 Python 脚本而执行的解释器源代码的位置。你会看到类似下面的东西:

在上面一层,我们可以看到构成该源代码的每个目录以及被覆盖的代码的量。举个例子,让我们从 Objects 目录打开 listobject.c.gcov.html 文件。尽管我们不会完全看完这些文件,但我们会分析其中一部分。看下面这部分。
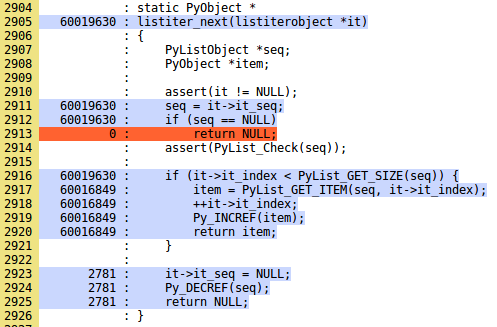
怎么读懂其中的信息?在黄色一列,你可以看到 C 语言文件代码的行数。接下来一列是特定一行代码执行的次数。最右边一列是实际的 C 语言源代码。
在这个例子中,listiter_next 方法被调用了 6000 万次。
我们怎么找到这个函数?如果我们仔细看看我们的 Python 脚本,我们可以看到它使用了大量的列表迭代和 append。(这是另一个可以一开始就做脚本优化的地方。)
让我们继续看看其它一些专用工具。在 Linux 系统上,如果我们想要更多信息,我们可以使用 perf。官方文档可参阅:https://perf.wiki.kernel.org/index.php/Main_Page
我们使用下面的代码重建了 CPython 解释器。你应该将这个 Python 脚本下载到同一个目录。另外,要确保你的系统安装了 perf。
make clean./configure --with-pydebugmake
如下运行 perf。使用 perf 的更多方式可以看 Brendan Gregg 写的这个:http://www.brendangregg.com/perf.html
sudo perf record ./python 04.primes-v1.py
运行脚本后,你会看到下述内容:
Benchmark duration: 32.03910684585571 seconds[21868 refs]perf record: Woken up 20 times to write data ][ perf record: Captured and wrote 4.914 MB perf.data (125364 samples) ]
要查看结果,运行 sudo perf report 获取指标。
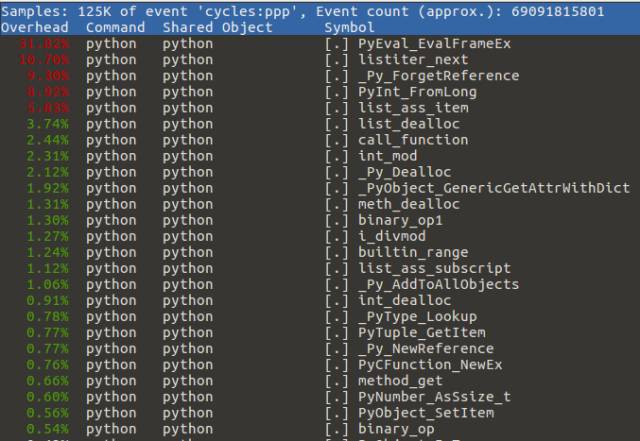
只有最相关的调用会被保留。在上面的截图中,我们可以看到占用时间最多的是 PyEval_EvalFrameEx。这是其中的主解释器循环,在这个例子中,我们对此并不关心。我们感兴趣的是下一个耗时的函数 listiter_next,它占用了 10.70% 的时间。
在运行了优化的版本之后,我们可以看到以下结果:
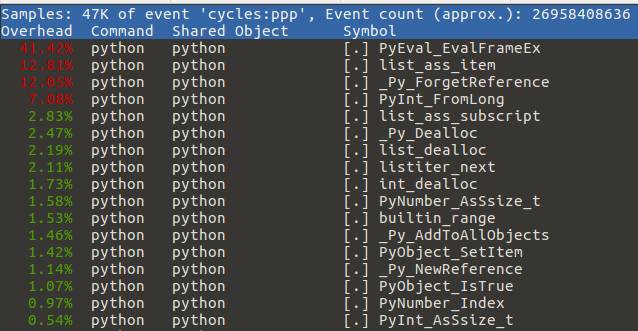
在我们优化之后,listiter_next 函数的时间占用降至了 2.11%。读者还可以探索对该解释器进行进一步的优化。
2. Valgrind/Callgrind
另一个可用于寻找瓶颈的工具是 Valgrind,它有一个被称为 callgrind 的插件。更多细节请参阅:http://valgrind.org/docs/manual/cl-manual.html
我们使用下面的代码重建了 CPython 解释器。你应该将这个 Python 脚本下载到同一个目录。另外,确保你的系统安装了 valgrind。
make clean./configure --with-pydebugmake
按下面方法运行 valgrind:
valgrind --tool=callgrind --dump-instr=yes--collect-jumps=yes --collect-systime=yes--callgrind-out-file=callgrind-%p.out -- ./python 04.primes-v1.py
结果如下:
Benchmark duration: 1109.4096319675446 seconds[21868 refs]==24152====24152== Events : Ir sysCount sysTime==24152== Collected : 115949791666 942 208==24152====24152== I refs: 115,949,791,666
我们使用 KCacheGrind 进行了可视化:http://kcachegrind.sourceforge.net/html/Home.html
kcachegrind callgrind-2327.out
PyPy
在 PyPy 上,可以成功使用的分析器是非常有限的。PyPy 的开发者为此开发了工具 vmprof:https://vmprof.readthedocs.io/en/latest/
首先,你要下载 PyPy:https://pypy.org/download.html。在此之后,为其启用 pip 支持。
bin/pypy -m ensurepip
安装 vmprof 的方式很简单,运行以下代码即可:
bin/pypy -m pip install vmprof
按以下方式运行工作负载:
bin/pypy -m vmprof --web 04.primes-v1.py
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/89435.html
