
1 紧凑模式
struct userbase{unsigned short cmd;//1-get, 2-set, 定义一个short,为了扩展更多命令(理想那么丰满)unsigned char gender; //1 – man , 2-woman, 3 - ??char name[8]; //当然这里可以定义为 string name;或len + value 组合,为了叙述方便,就使用简单定长数据}
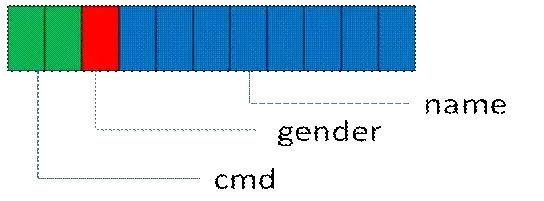
2 可扩展性
struct userbase{unsigned short cmd;unsigned char gender;unsigned int birthday;char name[8];}
struct userbase{unsigned short version;unsigned short cmd;unsigned char gender;unsigned int birthday;char name[8];}
3 更好的可扩展性
struct userbase{unsigned short version;unsigned short cmd;unsigned char gender;unsigned int birthday;char name[8];}
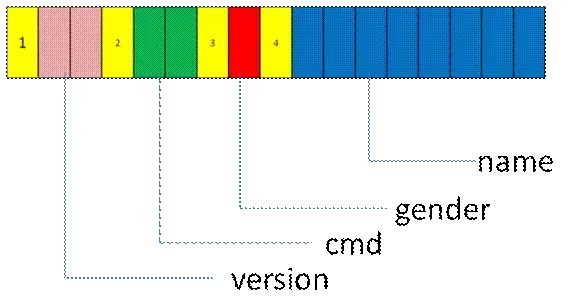


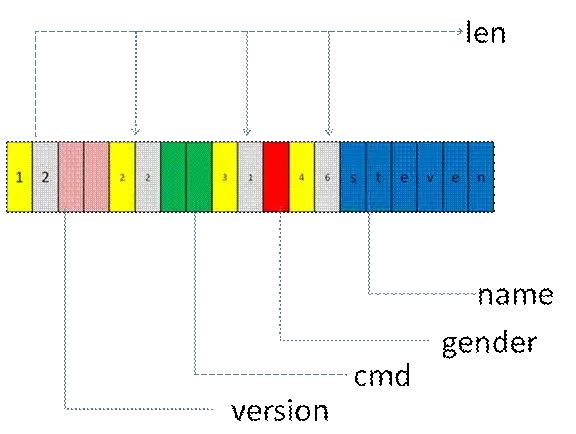
4 自解释性
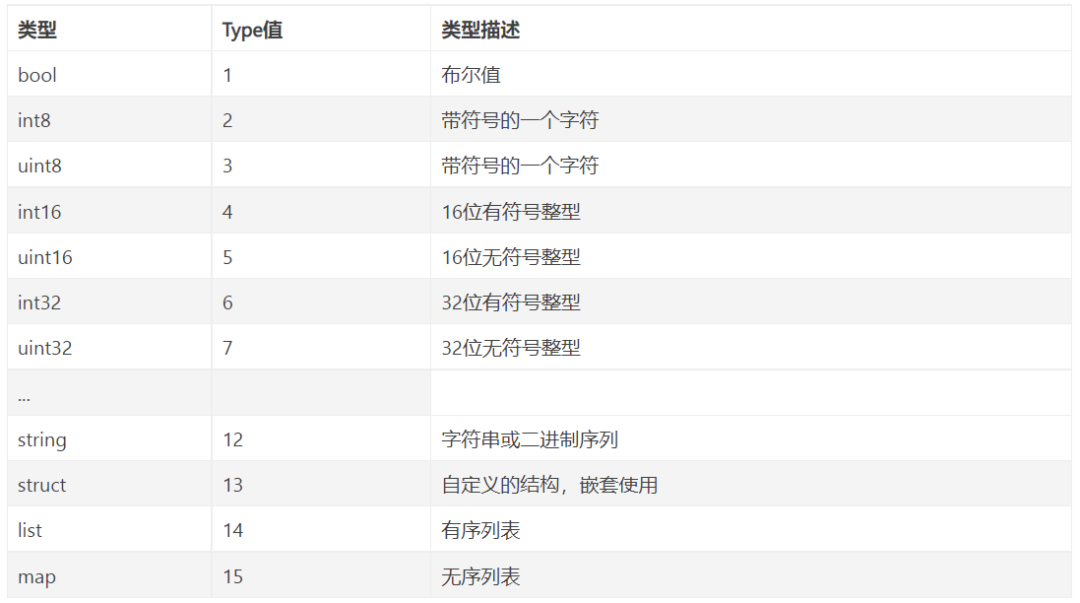
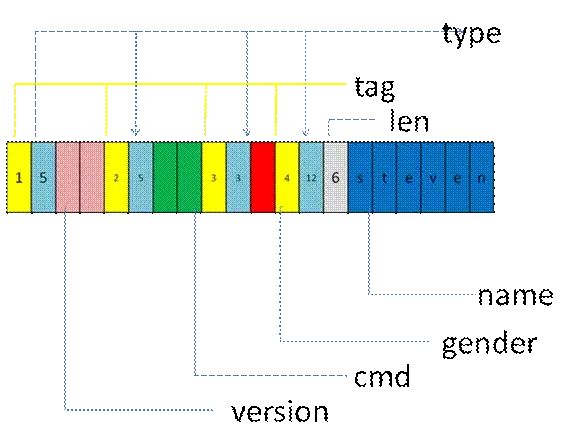
5 跨语言特性
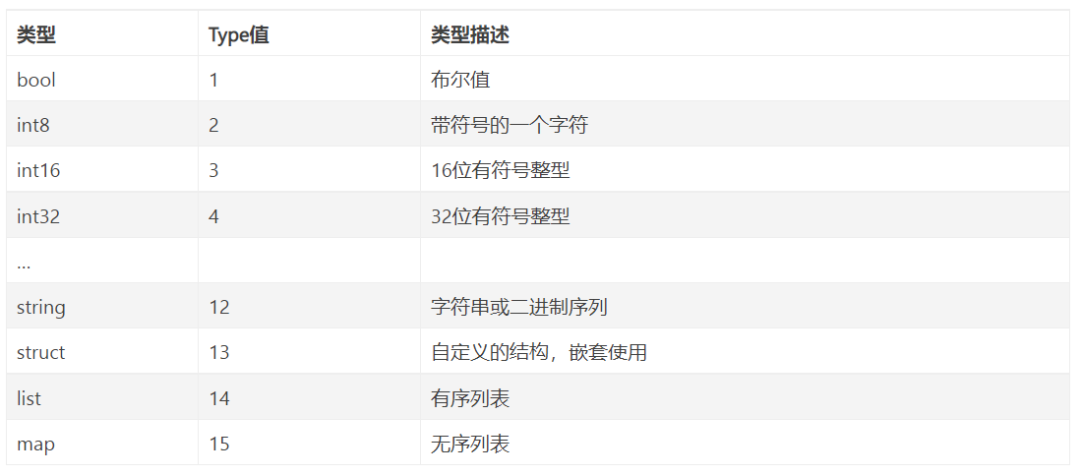
6 代码自动化——IDL语言的产生
Gencpp.exe sample.idl 输出 sample.cpp sample.hGenphp.exe sample.idl 输出 sample.phpGenjava.exe sample.idl 输出 sample.java
7 总结
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/89588.html