
一. 认识JavaScript引擎
1.1. 什么是JavaScript引擎
当我们编写JavaScript代码时,它实际上是一种高级语言,这种语言并不是机器语言。
-
高级语言是设计给开发人员使用的,它包括了更多的抽象和可读性。 -
但是,计算机的CPU只能理解特定的机器语言,它不理解JavaScript语言。 -
这意味着,在计算机上执行JavaScript代码之前,必须将其转换为机器语言。
这就是JavaScript引擎的作用:
-
事实上我们编写的JavaScript无论你交给浏览器或者Node执行,最后都是需要被CPU执行的; -
但是CPU只认识自己的指令集,实际上是机器语言,才能被CPU所执行; -
所以我们需要JavaScript引擎帮助我们将JavaScript代码翻译成CPU指令来执行;
比较常见的JavaScript引擎有哪些呢?
-
SpiderMonkey:第一款JavaScript引擎,由Brendan Eich开发(也就是JavaScript作者); -
Chakra:微软开发,用于IT浏览器; -
JavaScriptCore:WebKit中的JavaScript引擎,Apple公司开发; -
V8:Google开发的强大JavaScript引擎,也帮助Chrome从众多浏览器中脱颖而出; -
等等…
1.2. 浏览器内核和JS引擎关系
我们前面学习了浏览器内核,那么浏览器内核和JavaScript引擎之间是什么样的关系呢?
-
浏览器内核和JavaScript引擎之间有紧密的关系,因为JavaScript引擎是浏览器内核中的一个组件。 -
浏览器内核负责渲染网页,并在渲染过程中执行JavaScript代码。 -
JavaScript引擎则是负责解析、编译和执行JavaScript代码的核心组件。
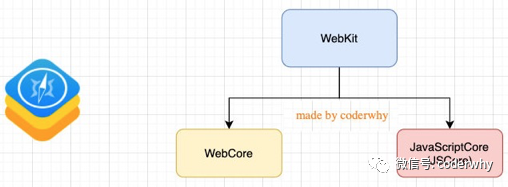
以WebKit为例,它是一种开源的浏览器内核,最初由Apple公司开发,并被用于Safari浏览器中。
-
WebKit包含了一个JavaScript引擎,名为JavaScriptCore,它负责解析、编译和执行JavaScript代码。
WebKit事实上由两部分组成的:
-
WebCore:负责HTML解析、布局、渲染等等相关的工作。 -
JavaScriptCore:解析、执行JavaScript代码。
看到这里,学过小程序的同学有没有感觉非常的熟悉呢?
-
在小程序中编写的JavaScript代码就是被JSCore执行的;
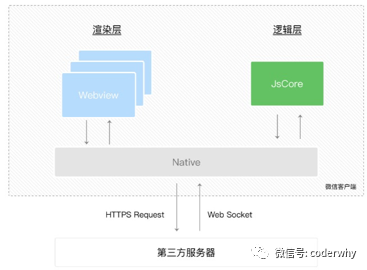
另外一个非常强大的JavaScript引擎就是V8引擎,也是我们今天要学习的重点。
二. V8引擎的运行原理
2.1. V8引擎的官方定义
V8引擎是一款Google开源的高性能JavaScript和WebAssembly引擎,它是使用C++编写的。
-
V8引擎的主要目标是提高JavaScript代码的性能和执行速度。 -
V8引擎可以在多种操作系统上运行,包括Windows 7或更高版本、macOS 10.12+以及使用x64、IA-32、ARM或MIPS处理器的Linux系统。
V8引擎可以作为一个独立的应用程序运行,也可以嵌入到其他C++应用程序中,例如Node.js。
-
由于V8引擎的开源性和高性能,许多现代浏览器都使用了V8引擎或其修改版本,以提供更快、更高效的JavaScript执行体验。
2.2. V8引擎如何工作呢?
2.2.1. V8引擎的工作过程
我这里先给出一副V8引擎的工作图:
-
后续我们会一点点解析它的工作过程
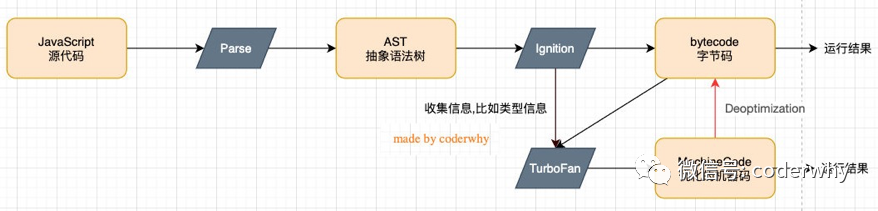
整体流程如下:(先简单了解)
-
词法分析: -
首先,V8引擎将JavaScript代码分成一个个标记或词法单元,这些标记是程序语法的最小单元。 -
例如,变量名、关键字、运算符等都是词法单元。 -
V8引擎使用词法分析器来完成这个任务。
-
-
语法分析: -
在将代码分成标记或词法单元之后,V8引擎将使用语法分析器将这些标记转换为抽象语法树(AST)。 -
语法树是代码的抽象表示,它捕捉了代码中的结构和关系。 -
V8引擎会检查代码是否符合JavaScript语言规范,并将其转换为抽象语法树。
-
-
字节码生成: -
接下来,V8引擎将从语法树生成字节码。 -
字节码是一种中间代码,它包含了执行代码所需的指令序列。 -
字节码是一种抽象的机器代码,它比源代码更接近机器语言,但仍需要进一步编译成机器指令。
-
-
机器码生成: -
最后,V8引擎将生成机器码,这是一种计算机可以直接执行的二进制代码。 -
V8引擎使用即时编译器(JIT)来将字节码编译成机器码。 -
JIT编译器将字节码分析为代码的热点部分,并生成高效的机器码,以提高代码的性能。
-
2.2.2. V8引擎的架构设计
V8引擎本身的源码非常复杂,大概有超过100w行C++代码,通过了解它的架构,我们可以知道它是如何对JavaScript执行的:
Parse模块会将JavaScript代码转换成AST(抽象语法树),这是因为解释器并不直接认识JavaScript代码;
-
如果函数没有被调用,那么是不会被转换成AST的; -
Parse的V8官方文档:https://v8.dev/blog/scanner
Ignition是一个解释器,会将AST转换成ByteCode(字节码)
-
同时会收集TurboFan优化所需要的信息(比如函数参数的类型信息,有了类型才能进行真实的运算); -
如果函数只调用一次,Ignition会执行解释执行ByteCode; -
Ignition的V8官方文档:https://v8.dev/blog/ignition-interpreter
TurboFan是一个编译器,可以将字节码编译为CPU可以直接执行的机器码;
-
如果一个函数被多次调用,那么就会被标记为热点函数,那么就会经过TurboFan转换成优化的机器码,提高代码的执行性能; -
但是,机器码实际上也会被还原为ByteCode,这是因为如果后续执行函数的过程中,类型发生了变化(比如sum函数原来执行的是number类型,后来执行变成了string类型),之前优化的机器码并不能正确的处理运算,就会逆向的转换成字节码; -
TurboFan的V8官方文档:https://v8.dev/blog/turbofan-jit
另外,V8引擎还包括了垃圾回收机制,用于自动管理内存的分配和释放。V8引擎使用了一种名为“分代式垃圾回收”(Generational Garbage Collection)的技术,它将堆区分成新生代和老年代两个部分,分别使用不同的垃圾回收策略,以提高垃圾回收的效率。
-
内存管理我们后续再单独来讨论学习。
2.3. V8的转化代码过程
比如我们有如下一段代码,V8引擎是如何一步步帮我们转化的呢?
const name = "coderwhy"
console.log(name)
function sayHi(name) {
console.log("Hi " + name)
}
sayHi(name)
下面是官方给出的一个图解:
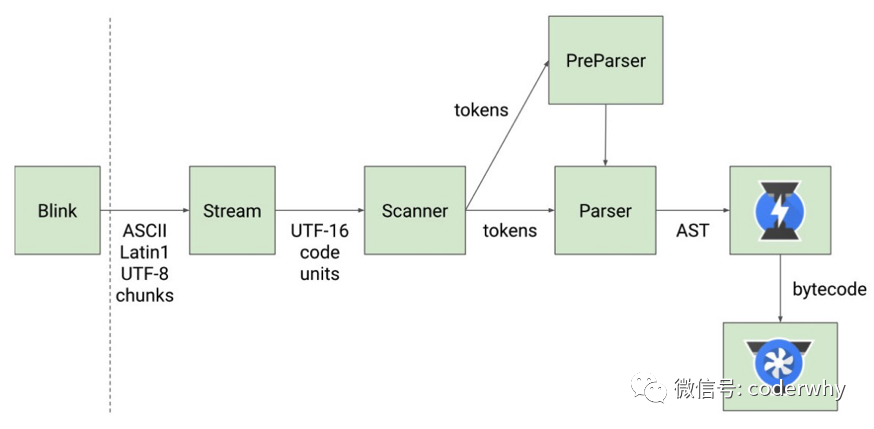
2.3.1. 词法分析的过程
词法分析是将JavaScript代码转换成一系列标记的过程,它是编译过程的第一步。
-
在V8引擎中,词法分析器会将JavaScript代码分解成一系列标识符、关键字、操作符和字面量等基本元素,以供后续的语法分析和代码生成等步骤使用。
这里仅仅举一个例子,作为参考即可
Token(type='const', value='const')
Token(type='identifier', value='name')
Token(type='operator', value='=')
Token(type='string', value='"coderwhy"')
Token(type='operator', value=';')
Token(type='console', value='console')
Token(type='operator', value='.')
Token(type='identifier', value='log')
Token(type='operator', value='(')
Token(type='identifier', value='name')
Token(type='operator', value=')')
Token(type='operator', value=';')
Token(type='function', value='function')
Token(type='identifier', value='sayHi')
Token(type='operator', value='(')
Token(type='identifier', value='name')
Token(type='operator', value=')')
Token(type='operator', value='{')
Token(type='console', value='console')
Token(type='operator', value='.')
Token(type='identifier', value='log')
Token(type='operator', value='(')
Token(type='string', value='"Hi "')
Token(type='operator', value='+')
Token(type='identifier', value='name')
Token(type='operator', value=')')
Token(type='operator', value=';')
Token(type='operator', value='}')
Token(type='identifier', value='sayHi')
Token(type='operator', value='(')
Token(type='identifier', value='name')
Token(type='operator', value=')')
Token(type='operator', value=';')
2.3.2. 语法分析的过程
接下来我们可以根据上面得到的tokens代码,进行语法分析,生成对应的AST树。
在V8引擎中,语法分析的过程可以分为两个阶段:解析(Parsing)和预处理(Pre-parsing)。
解析阶段是将tokens转换成抽象语法树(AST)的过程,而预处理阶段则是在解析阶段之前进行的,用于预处理一些代码,如函数和变量声明等。
对于你提供的JavaScript代码,V8引擎的解析和预处理过程如下所示:
V8引擎的解析和预处理过程如下所示:
-
预处理阶段
-
在预处理阶段,V8引擎会扫描整个代码,查找函数和变量声明,并将其添加到当前作用域的符号表中。 -
在这个过程中,V8引擎会同时进行词法分析和语法分析,生成一些中间表示,以便后续使用。 -
对于我们的代码,预处理阶段不会生成任何AST节点,因为它只包含了一个常量声明和一个函数声明,而没有变量声明(var声明的变量)。
-
解析阶段
-
在解析阶段,V8引擎会将tokens转换成AST节点,生成一棵抽象语法树(AST)。 -
AST是一种树形结构,用于表示程序的语法结构,它包含了多种类型的节点,如表达式节点、语句节点和声明节点等。
转化的AST树代码参考:
Program
└── VariableDeclaration (const name = "coderwhy")
└── ExpressionStatement (console.log(name))
└── FunctionDeclaration (function sayHi(name) { ... })
└── BlockStatement
└── ExpressionStatement (console.log("Hi " + name))
└── ExpressionStatement (sayHi(name))
从AST树中可以看出,整个程序由一个Program节点和三个子节点组成。
-
其中,第一个子节点是一个VariableDeclaration节点,表示常量声明语句; -
第二个子节点是一个ExpressionStatement节点,表示console.log语句; -
第三个子节点是一个FunctionDeclaration节点,表示函数声明语句。 -
FunctionDeclaration节点包含一个BlockStatement子节点,表示函数体,其中包含一个ExpressionStatement节点,表示console.log语句。 -
最后一个子节点是一个ExpressionStatement节点,表示调用函数语句。
-
2.3.3. 转化的字节码(了解)
根据上面得到的AST树,我们可以将其转换成对应的字节码。在V8引擎中,字节码是一种中间表示,用于表示程序的执行流程和指令序列。
V8引擎会将AST树转换成如下的字节码序列:
// 字节码指令集
[Constant name="coderwhy"]
[SetLocal name]
[GetLocal name]
[LoadProperty console]
[LoadProperty log]
[Call 1]
[Constant Hi ]
[GetLocal name]
[BinaryOperation +]
[Call 1]
[SetLocal sayHi]
[GetLocal name]
[GetLocal sayHi]
[Call 1]
[Return]
根据上面生成的字节码,我们可以看到V8引擎生成的字节码指令集,每个指令都对应了一种操作,如Constant、SetLocal、GetLocal等等。下面是对字节码指令集的解释:
-
Constant:将常量值压入操作数栈中。 -
SetLocal:将操作数栈中的值存储到本地变量中。 -
GetLocal:将本地变量的值压入操作数栈中。 -
LoadProperty:从对象中加载属性值,并将其压入操作数栈中。 -
Call:调用函数,并将返回值压入操作数栈中。 -
BinaryOperation:对两个操作数执行二元运算,并将结果压入操作数栈中。 -
Return:从当前函数中返回,并将返回值压入操作数栈中。
由于字节码是一种中间表示,它可以跨平台运行,在不同的操作系统和硬件平台上都可以执行。这种跨平台的特性,使得V8引擎成为了一款非常流行的JavaScript引擎。
在Node环境中,我们可以通过如下命令查看到字节码:
-
但是默认Node环境下是打印所有的字节码的,所以内容会非常多(了解即可)
node --print-bytecode test.js
2.3.4. 生成的机器码(了解)
在V8引擎中,机器码是通过即时编译(Just-In-Time Compilation,JIT)技术生成的。
-
JIT编译是一种动态编译技术,它将字节码转换成本地机器码,并将其缓存起来以提高代码的执行速度和性能。 -
JIT编译器可以根据运行时信息对代码进行优化,并且可以根据不同的平台和硬件生成对应的机器码。
在V8引擎中,机器码的生成过程分为两个阶段:
-
预编译(pre-compilation)和优化(optimization)。 -
预编译阶段会生成一些简单的机器码,用于快速执行代码; -
优化阶段则会根据代码的运行时信息生成更优化的机器码,以提高代码的执行效率和性能。
具体的生成过程如下:
-
预编译阶段
-
在预编译阶段,V8引擎会生成一些简单的机器码,用于快速执行代码。 -
这些机器码是基于字节码生成的,它们可以直接执行,并且具有一定的优化效果。 -
在这个阶段,V8引擎会根据代码的运行时信息生成一些简单的机器码,如对象和数组的存取、字符串的拼接、函数的调用等。
-
优化阶段
-
在优化阶段,V8引擎会根据代码的运行时信息生成更优化的机器码,以提高代码的执行效率和性能。 -
在这个阶段,V8引擎会通过分析代码的执行路径、类型信息、控制流程等,生成一些高效的机器码,并且可以进行多次优化,以获得更高的性能。
在优化阶段,V8引擎会使用TurboFan编译器来生成机器码。
-
TurboFan是一个基于中间表示(Intermediate Representation,IR)的编译器,它可以将字节码转换成高效的机器码,并且可以进行多层次的优化,包括基于类型的优化、内联优化、控制流优化、垃圾回收优化等。
通过机器码的生成过程,我们可以看到V8引擎是如何根据代码的运行时信息生成高效的机器码,并且可以多次优化,以获得更高的性能。
-
在后续的执行过程中,V8引擎会将机器码缓存起来,以提高代码的执行速度和性能。
三. V8引擎的内存管理
3.1. 认识内存管理
不管什么样的编程语言,在代码的执行过程中都是需要给它分配内存的,不同的是某些编程语言需要我们自己手动的管理内存,某些编程语言会可以自动帮助我们管理内存。
不管以什么样的方式来管理内存,内存的管理都会有如下的生命周期:
-
第一步:分配申请你需要的内存(申请); -
第二步:使用分配的内存(存放一些东西,比如对象等); -
第三步:不需要使用时,对其进行释放;
不同的编程语言对于第一步和第三步会有不同的实现:
-
手动管理内存:比如C、C++,包括早期的OC,都是需要手动来管理内存的申请和释放的(malloc和free函数); -
这种方式需要程序员手动管理内存,容易出现内存泄漏和野指针等问题,程序的稳定性和安全性有一定的风险。
-
-
自动管理内存:比如Java、JavaScript、Python、Swift、Dart等,它们有自动帮助我们管理内存; -
在这些语言中,存在垃圾回收机制来自动回收不再使用的内存空间,程序员只需要正确地使用变量和对象等引用类型数据,垃圾回收器就会自动进行内存管理,释放不再被引用的内存空间。 -
这种方式可以避免内存泄漏和野指针等问题,提高了程序的稳定性和安全性。
-
对于开发者来说,JavaScript 的内存管理是自动的、无形的。
-
我们创建的原始值、对象、函数……这一切都会占用内存; -
但是我们并不需要手动来对它们进行管理,JavaScript引擎会帮助我们处理好它;
3.2. JS的内存管理
在JavaScript中,内存分为栈内存和堆内存两种类型。
-
栈内存用于存储基本数据类型和引用类型的地址,它具有自动分配和自动释放的特点。 -
堆内存用于存储引用类型的对象和数组等数据结构,它需要手动分配和释放内存。
在JavaScript中,使用var、let和const声明的变量都是存在栈内存中的。
-
当我们声明一个变量时,JavaScript引擎会在栈内存中为其分配一块空间,并将变量的值存储在该空间中。 -
当变量不再被引用时,JavaScript引擎会自动将其释放掉,以回收其空间。
在JavaScript中,创建的对象和数组等引用类型数据都是存在堆内存中的。
-
当我们创建一个对象时,JavaScript引擎会在堆内存中为其分配一块空间,并将其属性存储在该空间中。 -
当对象不再被引用时,垃圾回收器会自动将其标记为垃圾,并回收其空间。
为内存的大小是有限的,所以当内存不再需要的时候,我们需要对其进行释放,以便腾出更多的内存空间。
在手动管理内存的语言中,我们需要通过一些方式自己来释放不再需要的内存,比如free函数:
-
但是这种管理的方式其实非常的低效,影响我们编写逻辑的代码的效率; -
并且这种方式对开发者的要求也很高,并且一不小心就会产生内存泄露和野指针的情况; -
影响程序的稳定性和安全性,同时也会影响编写逻辑代码的效率;
所以大部分现代的编程语言都是有自己的垃圾回收机制:
-
垃圾回收的英文是Garbage Collection,简称GC; -
对于那些不再使用的对象,我们都称之为是垃圾,它需要被回收,以释放更多的内存空间; -
而我们的语言运行环境,比如Java的运行环境JVM,JavaScript的运行环境js引擎都会内存 垃圾回收器; -
垃圾回收器我们也会简称为GC,所以在很多地方你看到GC其实指的是垃圾回收器;
但是这里又出现了另外一个很关键的问题:GC怎么知道哪些对象是不再使用的呢?这里就要用到GC的实现以及对应的算法;
3.3. 常见的GC算法
3.3.1. 引用计数(Reference counting)
引用计数(Reference counting)是一种常见的垃圾回收算法。
-
它的基本思想是在对象中添加一个引用计数器。 -
每当有一个指针引用该对象时,引用计数器就加一。 -
当指针不再引用该对象时,引用计数器就减一。 -
当引用计数器的值为0时,表示该对象不再被引用,可以被回收。
引用计数算法的优点是实现简单,垃圾对象的回收及时,可以避免内存泄漏。
但是引用计数算法也有一些缺点。
-
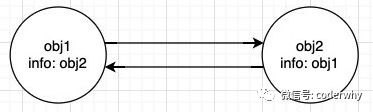
最大的缺点是很难解决循环引用问题。 -
如果两个对象相互引用,它们的引用计数器永远不会为0,即使它们已经成为垃圾对象。 -
这种情况下,引用计数算法就无法回收它们,导致内存泄漏。
3.3.2. 标记清除(mark-Sweep)
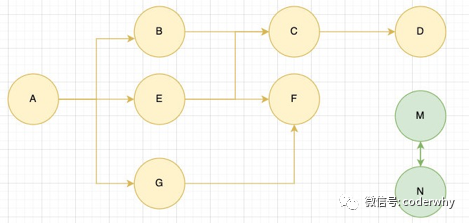
标记清除(mark-Sweep)是一种常见的垃圾回收算法,其核心思想是可达性(Reachability)。算法的实现过程如下:
-
设置一个根对象(root object),垃圾回收器会定期从这个根开始,找所有从根开始有引用到的对象。 -
对于每一个找到的对象,标记为可达(mark),表示该对象正在使用中。 -
对于所有没有被标记为可达的对象,即不可达对象,就认为是不可用的对象,需要被回收。 -
回收不可达对象所占用的内存空间,并将其加入空闲内存池中,以备将来重新分配使用。
标记清除算法可以很好地解决循环引用的问题,因为它只关注可达性,不会被循环引用的对象误判为可用对象。
但是这种算法也有一些缺点,最主要的是它的效率不高,因为在标记可达对象和回收不可达对象的过程中需要遍历整个对象图。
此外,标记清除算法还会造成内存碎片的问题,因为回收的内存空间不一定是连续的,导致大块的内存无法被分配使用。
3.3.3. 其他算法优化补充
S引擎比较广泛的采用的就是可达性中的标记清除算法,当然类似于V8引擎为了进行更好的优化,它在算法的实现细节上也会结合一些其他的算法。
标记整理(Mark-Compact)
-
和“标记-清除”相似; -
不同的是,回收期间同时会将保留的存储对象搬运汇集到连续的内存空间,从而整合空闲空间,避免内存碎片化;
分代收集(Generational collection)—— 对象被分成两组:“新的”和“旧的”。
-
许多对象出现,完成它们的工作并很快死去,它们可以很快被清理; -
那些长期存活的对象会变得“老旧”,而且被检查的频次也会减少;
增量收集(Incremental collection)
-
如果有许多对象,并且我们试图一次遍历并标记整个对象集,则可能需要一些时间,并在执行过程中带来明显的延迟。 -
所以引擎试图将垃圾收集工作分成几部分来做,然后将这几部分会逐一进行处理,这样会有许多微小的延迟而不是一个大的延迟;
闲时收集(Idle-time collection)
-
垃圾收集器只会在 CPU 空闲时尝试运行,以减少可能对代码执行的影响。 -
这种算法通常用于移动设备或其他资源受限的环境,以确保垃圾收集对用户体验的影响最小。
3.3.4. V8引擎的内存图
事实上,V8引擎为了提供内存的管理效率,对内存进行非常详细的划分。(详细参考视频学习)
这幅图展示了一个堆(heap)的内存结构,下面是对每个内存块的解释:
-
Old Space(老生代):分配的内存较大,存储生命周期较长的对象,比如页面或者浏览器的长时间使用对象; -
New Space(新生代):分配的内存较小,存储生命周期较短的对象,比如临时变量、函数局部变量等; -
Large Object Space(大对象):分配的内存较大,存储生命周期较长的大型对象,比如大数组、大字符串等; -
Code Space(代码空间):存储编译后的函数代码和 JIT 代码; -
Map Space(映射空间):存储对象的属性信息,比如对象的属性名称、类型等信息; -
Cell Space(单元格空间):存储对象的一些元信息,比如字符串长度、布尔类型等信息。
这些不同的内存块都有各自的特点和用途,V8 引擎会根据对象的生命周期和大小将它们分配到不同的内存块中,以优化内存的使用效率。
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/89707.html