
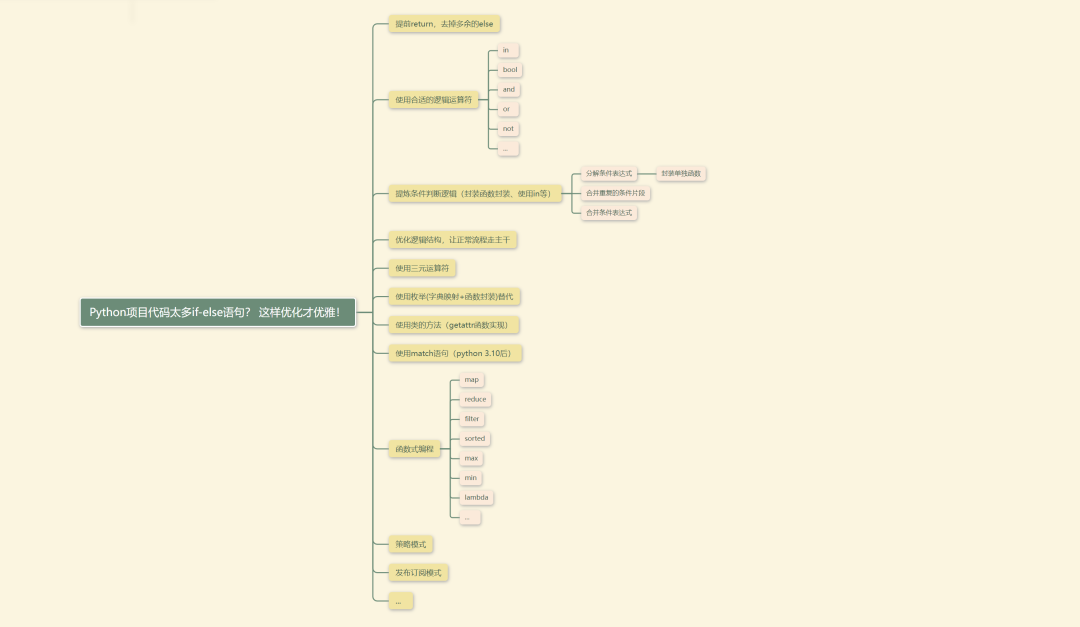
前言
代码中不可避免地会出现复杂的if-else条件逻辑,而简化这些条件表达式是一种提高代码可读性极为实用的技巧。
在 Python 中,有多种方法可以避免复杂的 if-else 条件逻辑,使代码更加清晰和易于维护。
筑基期
提前 return,去掉多余的 else
在 Python 中,使用”提前返回”(early return)可以避免深层嵌套的
if-else语句,并且使代码更加清晰。
场景:电商平台为首次购买的用户在结账时提供优惠券。如果用户不是首次购买,或者购物车中的商品总额低于某个阈值,则不提供优惠券。
未使用提前返回的原始代码:
def apply_coupon(user, cart):
if user.is_first_purchase:
if cart.total_amount >= 100:
cart.apply_discount(10) # 应用10%的折扣
print("A coupon has been applied to your purchase.")
else:
print("Your purchase does not meet the minimum amount for a coupon.")
else:
print("Coupons are only available for first-time purchases.")
return cart
使用提前返回优化后的代码:
def apply_coupon(user, cart):
# 检查是否为首次购买
if not user.is_first_purchase:
print("Coupons are only available for first-time purchases.")
return cart# 检查购物车总额是否满足条件
if cart.total_amount < 100:
print(“Your purchase does not meet the minimum amount for a coupon.”)
return cart
# 应用优惠券
cart.apply_discount(10) # 应用10%的折扣
print(“A coupon has been applied to your purchase.”)
return cart
首先,定义用户和购物车类,以及必要的属性和方法:
class User:
def __init__(self, is_first_purchase):
self.is_first_purchase = is_first_purchaseclass Cart:
def __init__(self, total_amount):
self.total_amount = total_amount
self.discount = 0
def apply_discount(self, percentage):
self.discount = self.total_amount * (percentage / 100)
self.total_amount -= self.discount
def __str__(self):
return f”Cart(total_amount={self.total_amount}, discount={self.discount})”
然后,我们创建两个用户和两个购物车对象。
-
第一个用户是首次购买,购物车总额为150,满足应用优惠券的条件,因此会看到优惠券被应用,并且购物车总额减少。 -
第二个用户不是首次购买,购物车总额为50,不满足应用优惠券的条件,因此会看到相应的提示信息,购物车总额不变。
# 创建用户对象,假设是首次购买
user = User(is_first_purchase=True)# 创建购物车对象,假设购物车总额为150
cart = Cart(total_amount=150)
# 打印原始购物车状态
print(“原始购物车状态:”, cart)
# 调用apply_coupon函数
cart = apply_coupon(user, cart)
# 打印应用优惠券后的购物车状态
print(“应用优惠券后的购物车状态:”, cart)
# 再次创建一个购物车对象,假设购物车总额为50,且用户不是首次购买
another_user = User(is_first_purchase=False)
another_cart = Cart(total_amount=50)
# 打印原始购物车状态
print(“n原始购物车状态:”, another_cart)
# 调用apply_coupon函数
another_cart = apply_coupon(another_user, another_cart)
# 打印应用优惠券后的购物车状态(实际上不会应用优惠券)
print(“应用优惠券后的购物车状态(实际上不会应用优惠券):”, another_cart)

在这个优化后的版本中,我们使用了提前返回来简化逻辑流程:
-
首先检查用户是否为首次购买,如果不是,则立即返回,不再执行后续代码。 -
然后检查购物车总额是否满足优惠券的最低限额,如果不满足,同样立即返回。 -
只有当这两个条件都满足时,才应用优惠券并打印相应的消息。
提前返回的好处:
-
逻辑清晰:每个条件都被单独检查,并且不满足时立即返回,逻辑流程非常清晰。 -
减少嵌套:避免了深层嵌套的 if-else结构,使得代码更加扁平化。 -
易于维护:当需要修改条件或者添加新的条件时,可以很容易地在函数开头添加新的检查。 -
避免冗余:去掉了不必要的 else语句,因为每个if语句都有明确的返回点。
通过这种方式,提前返回使得代码更加简洁、直观,并且易于理解和维护。
使用合适的逻辑运算符
在Python开发中,逻辑运算符and、or、in、bool()和not等可以帮助我们简化条件判断,从而减少if语句的使用。以下是使用逻辑运算符优化if语句的一个电商例子。
场景:电商平台想要为特定条件下的用户提供优惠券。条件包括:
-
用户必须是新用户( is_new属性为True)。 -
用户的购物车中必须包含至少一种电子产品( category属性为"electronics")。 -
用户的购物车总价必须超过一定金额(例如200元)。
未使用逻辑运算符的原始代码:
from collections import namedtupledef apply_coupon(_cart_items, _user):
if _user.is_new:
if any(item[‘category’] == ‘electronics’ for item in _cart_items):
if sum(item[‘price’] * item[‘quantity’] for item in _cart_items) > 200:
# 应用优惠券逻辑
print(“Coupon applied!”)
else:
print(“Cart total is less than 200.”)
else:
print(“No electronics in cart.”)
else:
print(“User is not new.”)
# 示例用户和购物车
User = namedtuple(‘User’, [“is_new”])
user = User(is_new=True)
cart_items = [
{‘name’: ‘Laptop’, ‘category’: ‘electronics’, ‘price’: 150, ‘quantity’: 1},
{‘name’: ‘Book’, ‘category’: ‘books’, ‘price’: 50, ‘quantity’: 2},
]
apply_coupon(cart_items, user) # Coupon applied!
使用逻辑运算符优化后的代码:
from collections import namedtupledef apply_coupon(cart_items, user):
# 使用逻辑运算符组合条件
new_user = user.is_new
has_electronics = any(item[‘category’] == ‘electronics’ for item in cart_items)
cart_total = sum(item[‘price’] * item[‘quantity’] for item in cart_items) > 200
# 如果所有条件都满足,则应用优惠券
if new_user and has_electronics and cart_total:
print(“Coupon applied!”)
else:
print(“Coupon not applied.”)
# 示例用户和购物车
User = namedtuple(‘User’, [“is_new”])
user = User(is_new=True)
cart_items = [
{‘name’: ‘Laptop’, ‘category’: ‘electronics’, ‘price’: 150, ‘quantity’: 1},
{‘name’: ‘Book’, ‘category’: ‘books’, ‘price’: 50, ‘quantity’: 2},
]
apply_coupon(cart_items, user) # Coupon applied!
在这个优化后的版本中,我们首先使用逻辑运算符来单独评估每个条件:
-
new_user检查用户是否为新用户。 -
has_electronics检查购物车中是否有电子产品。 -
cart_total检查购物车总价是否超过 200 元。
然后,我们使用and运算符来确保所有条件都满足,只有当这个组合条件为真时,才应用优惠券。
使用逻辑运算符的好处包括:
-
代码简化:减少了嵌套的 if语句,使代码更加简洁。 -
逻辑清晰:每个条件的评估清晰明了,易于理解和维护。 -
易于调整:如果需要修改条件或添加新条件,只需调整逻辑表达式即可。
通过这种方式,逻辑运算符帮助我们编写出更加Pythonic和易于维护的代码。
提炼条件判断逻辑
当条件判断变得过于复杂时,它不仅难以理解,还可能导致代码维护困难。将复杂的条件判断逻辑提炼成独立的函数是一种很好的实践,这样可以使代码更加清晰、可读性更高,并且易于维护。
假设我们有一个函数,根据用户的购物车中的商品种类和数量来决定是否提供折扣。原始的代码可能包含多个嵌套的if-else语句,如下所示:
def calculate_discount(_cart_items):
discount = 0
if 'electronics' in _cart_items:
if len(_cart_items['electronics']) >= 3:
discount += 10
if 'laptop' in _cart_items['electronics']:
discount += 5
elif 'clothing' in _cart_items:
if len(_cart_items['clothing']) >= 5:
discount += 15
# ... 更多条件
return discount
这个函数的可读性很差,很难一眼看出它在做什么。我们可以将复杂的条件判断逻辑提炼成独立的函数,如下所示:
# 定义检查商品的函数
def has_bulk_electronic_items(_cart_items):
return len(_cart_items.get('electronics', [])) >= 3def has_laptop_in_electronics(_cart_items):
return ‘laptop’ in _cart_items.get(‘electronics’, [])
def has_many_clothing_items(_cart_items):
return len(_cart_items.get(‘clothing’, [])) >= 5
# 定义计算折扣的函数
def calculate_discount(_cart_items):
discount = 0
if has_bulk_electronic_items(_cart_items):
discount += 10 # 电子产品数量超过3个,折扣10%
if has_laptop_in_electronics(_cart_items):
discount += 5 # 电子产品中有笔记本电脑,额外折扣5%
if has_many_clothing_items(_cart_items):
discount += 15 # 服装数量超过5个,折扣15%
return discount
# 定义购物车商品
cart_items = {
‘electronics’: [‘laptop’, ‘smartphone’, ‘headphones’], # 电子产品分类下有3个商品
‘clothing’: [‘shirt’, ‘pants’], # 服装分类下有2个商品
# 可以添加更多商品分类和数量…
}
# 计算折扣
total_discount = calculate_discount(cart_items)
# 打印折扣信息
print(f”The total discount for the cart is: {total_discount}%”) # The total discount for the cart is: 15%
通过这种方式,每个函数都有一个明确的目的,并且函数名清晰地表达了这个目的。calculate_discount函数现在更加简洁,逻辑清晰,易于理解和维护。如果需要修改折扣逻辑,我们只需找到对应的函数并进行修改,而不需要深入嵌套的if-else语句。
此外,每个独立的函数都可以单独测试,这有助于确保代码的正确性和可靠性。这种将复杂逻辑分解为简单、可管理的部分的做法,是编写高质量代码的一个重要原则。
优化逻辑结构,让正常流程走主干
优化逻辑结构通常意味着将正常流程放在主干路径中,而将特殊情况或错误处理放在分支路径中。这个和
提前 return,去掉多余的 else是有点重合,这里也是来强调逻辑结构优化的重要性。
假设我们有一个函数,用于计算用户的购物车中商品的最终价格,并根据商品种类和数量应用不同的折扣规则。
原始的复杂逻辑结构:
def calculate_final_price(cart_items, user_info):
if len(cart_items) > 10000:
_final_price = 0 # 价格不能为负else:
_final_price = sum(item[‘price’] * item[‘quantity’] for item in cart_items)
# 复杂的折扣逻辑
if user_info[‘is_member’]:
if ‘electronics’ in [item[‘category’] for item in cart_items]:
_final_price *= 0.95 # 会员购买电子产品享受5%的折扣
elif ‘clothing’ in [item[‘category’] for item in cart_items]:
_final_price *= 0.9 # 会员购买服装享受10%的折扣
else:
if len([item for item in cart_items if item[‘category’] == ‘books’]) >= 3:
_final_price *= 0.9 # 非会员购买三本及以上书籍享受10%的折扣
return _final_price
优化后的逻辑结构:
def calculate_final_price(cart_items, user_info):
# 异常情况:购物车项目过多
if len(cart_items) > 10000:
print("Error: Too many items in cart.")
_final_price = 0 # 根据业务规则处理, 这里价格假设为0
return _final_price
# 首先计算基础价格
_final_price = sum(item['price'] * item['quantity'] for item in cart_items)# 应用折扣逻辑
if user_info[‘is_member’]:
# 会员折扣
if ‘electronics’ in [item[‘category’] for item in cart_items]:
_final_price *= 0.95 # 会员购买电子产品享受5%的折扣
elif ‘clothing’ in [item[‘category’] for item in cart_items]:
_final_price *= 0.9 # 会员购买服装享受10%的折扣
else:
# 非会员折扣
if len([item for item in cart_items if item[‘category’] == ‘books’]) >= 3:
_final_price *= 0.9 # 非会员购买三本及以上书籍享受10%的折扣
return _final_price
调用示例:
# 示例购物车商品列表
cart_items = [
{'name': 'Laptop', 'category': 'electronics', 'price': 1200, 'quantity': 1},
{'name': 'Jeans', 'category': 'clothing', 'price': 200, 'quantity': 2},
{'name': 'Book', 'category': 'books', 'price': 50, 'quantity': 2},
# 可以添加更多商品...
]# 示例用户信息
user_info = {
‘is_member’: True, # 假设用户是会员
# 可以添加更多用户信息…
}
# 计算最终价格
final_price = calculate_final_price(cart_items, user_info)
# 打印价格信息
print(f”The final price after discounts is: ${final_price:.2f}“)
# The final price after discounts is: $1615.00
在这个优化后的版本中,主逻辑是计算基础价格,然后根据用户是否为会员分别应用折扣。这样,正常流程(会员折扣和非会员折扣)成为主干路径,而特殊情况则作为分支处理。
这种结构的优点包括:
-
清晰的主干流程:正常逻辑(计算基础价格和应用折扣)清晰地展现在主干路径中,易于理解和维护。 -
简化的分支处理:特殊情况(价格检查)被隔离在单独的分支中,不会干扰主干逻辑。 -
更好的可扩展性:添加新的折扣规则或调整现有规则变得更加简单,因为每个折扣逻辑都被封装在独立的函数中。 -
易于测试:每个函数都可以单独测试,有助于确保代码的正确性。
通过这种方式,我们优化了逻辑结构,使得代码更加清晰、易于理解和维护,同时也提高了代码的可扩展性和可测试性。
使用三元运算符
使用三元运算符(也称为条件表达式)是 Python 中简化if-else语句的常用方法。三元运算符允许你在一个表达式中包含逻辑判断,其基本语法是:
a if condition else b
这里是一个电商场景中使用三元运算符的例子:
原始的 if-else 语句:
def get_user_status(user_points):
if user_points >= 1000:
return "Gold Member"
elif user_points >= 500:
return "Silver Member"
else:
return "Bronze Member"
使用三元运算符优化后的语句:
def get_user_status(user_points):
return (
"Gold Member" if user_points >= 1000 else
"Silver Member" if user_points >= 500 else
"Bronze Member"
)print(get_user_status(1001)) # Gold Member
在这个例子中,我们用三元运算符替换了if-elif-else链。这种写法可能使得代码更加简洁和易于阅读,尤其是当有少数个条件需要判断时。三元运算符是 Python 中一种非常有用的工具,可以减少代码的冗余,提高代码的可读性。
请注意,虽然三元运算符可以提高代码的简洁性,但如果过度使用或嵌套过深,可能会导致代码难以理解。因此,
合理使用三元运算符,保持代码的清晰和可维护性是非常重要的。
使用枚举(字典映射+函数封装)替代
使用字典和函数来优化if语句是一种常见的设计模式,尤其是在处理多种条件分支时。这种方式可以减少代码中的重复逻辑,提高代码的可读性和可维护性。下面是一个电商场景中的例子,其中我们根据用户的行为来执行不同的函数。
原始的 if-else 语句:
def handle_user_action(action):
if action == 'add_to_cart':
print("Item added to cart.")
elif action == 'checkout':
print("Processing checkout.")
elif action == 'view_product':
print("Viewing product details.")
elif action == 'search':
print("Searching for products.")
else:
print("Unknown action.")
使用字典和函数优化后的语句:
def add_to_cart():
print("Item added to cart.")def checkout():
print(“Processing checkout.”)
def view_product():
print(“Viewing product details.”)
def search():
print(“Searching for products.”)
def unknown_action():
print(“Unknown action.”)
def handle_user_action(action):
actions = {
‘add_to_cart’: add_to_cart,
‘checkout’: checkout,
‘view_product’: view_product,
‘search’: search
}
actions.get(action, unknown_action)() # 调用相应的函数,如果找不到则调用unknown_action
handle_user_action(“add_to_cart”) # Item added to cart.
handle_user_action(“checkout”) # Processing checkout.
handle_user_action(“view_product”) # Viewing product details.
handle_user_action(“search”) # Searching for products.
在这个优化后的版本中,我们定义了与每个用户行为相对应的函数。然后,我们创建了一个字典actions,将用户行为的字符串映射到相应的函数上。在handle_user_action函数中,我们使用get方法从字典中获取与用户行为对应的函数,并立即调用它。如果字典中没有找到对应的行为,get方法将返回unknown_action函数并执行。
这种设计模式的好处是:
-
可扩展性:如果需要添加新的行为,只需添加一个新的函数并在字典中添加一个新的映射即可。 -
可读性:每个行为的处理逻辑都封装在单独的函数中,使得主函数 handle_user_action更加简洁。 -
可维护性:如果需要修改某个行为的处理逻辑,只需修改对应的函数,而不需要更改主函数的逻辑。
使用字典和函数的方法提供了一种清晰、灵活的方式来处理多种条件分支,非常适合于复杂或不断变化的业务逻辑。
使用类的方法
上面的例子,我们建立了一个字典,并构建了action到对应函数的关系,这无可厚非。
但是,是否可以更 pythonic 呢?
由于 Python 中的
object本质上是通过字典来存储数据的,我们可以充分利用这一特性,将object本身作为存储结构,从而让代码更加简洁高效。
我们可以创建一个基类,该基类具有一个代理方法用于执行实际(动作)方法。然后,我们可以在子类中重写这些实际(动作)方法来实现具体的功能。使用hasattr和getattr,我们可以检查对象是否具有特定的动作方法,并调用它。
下面是如何实现的示例:
#! -*-conding=: UTF-8 -*-
# 2024/6/4
class ECommerceActions:
def handle_user_action(self, action):
getattr(self, f"do_{action}", self.unknown_action)()def unknown_action(self):
print(“Unknown action.”)
# 接下来,创建一个具体的动作类来实现具体的功能
class ConcreteECommerceActions(ECommerceActions):
def do_add_to_cart(self):
print(“Item added to cart.”)
def do_checkout(self):
print(“Processing checkout.”)
def do_view_product(self):
print(“Viewing product details.”)
def do_search(self):
print(“Searching for products.”)
# 使用示例
actions = ConcreteECommerceActions()
actions.handle_user_action(‘add_to_cart’) # 应输出: Item added to cart.
actions.handle_user_action(‘checkout’) # 应输出: Processing checkout.
actions.handle_user_action(‘view_product’) # 应输出: Viewing product details.
actions.handle_user_action(‘search’) # 应输出: Searching for products.
actions.handle_user_action(‘refund’) # 应输出: Unknown action.
在这个示例中,ECommerceActions是一个基类,我们定义了一个handle_user_action方法来获取对应的实际方法,如果存在,则使用getattr来调用它。如果不存在,就调用unknown_action方法。
ConcreteECommerceActions是具体的类,它继承自ECommerceActions并实现了所有可能的动作方法。
使用类和hasattr/getattr的好处是:
-
扩展性:可以轻松添加新的动作和方法,只需在子类中实现它们即可。 -
灵活性:可以在运行时动态地添加或修改动作和方法。 -
封装性:动作的实现细节被封装在子类中,隐藏了实现细节。
这种方法提高了代码的模块化和可维护性,使得添加新功能或修改现有功能变得更加容易。
这种实现的好处,一个比较典型的案例是开源项目:
ProxyPool。
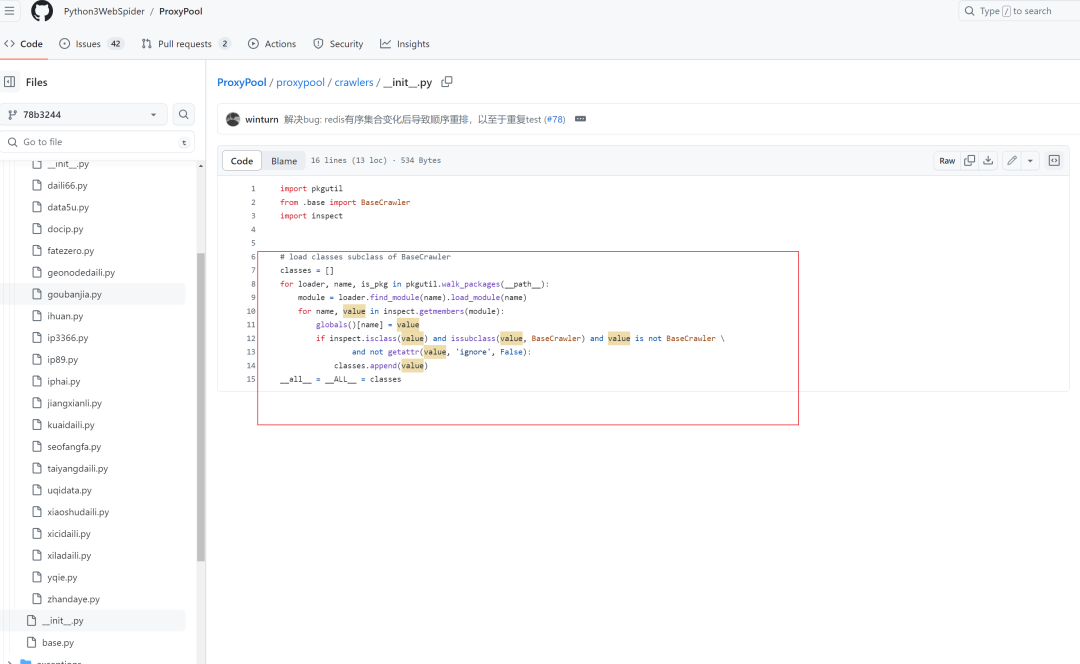
批量加载代理类,却避免了使用大量的
if statement。
使用 match 语句
在 Python 3.10 及以后的版本中,引入了一种新的结构:
match / case语法,它类似于其他编程语言中的switch或match语句。这个新特性允许我们用一种更加Pythonic的方式来表达多个条件分支,从而替代复杂的if-elif-else链。
假设我们有以下用户行为类型,并且我们想根据行为类型提供不同的优惠策略:
-
"add_to_cart": 添加商品到购物车 -
"checkout": 结账 -
"view_product": 查看商品详情 -
"search": 搜索商品
我们的目标是为不同的用户行为提供不同的优惠策略。以下是使用match语法优化的示例代码:
def apply_promotion_strategy(user_action):
match user_action:
case "add_to_cart":
return "Offer a 5% discount on the next purchase."
case "checkout":
return "Apply a 10% discount for first-time buyers."
case "view_product":
return "Recommend related products."
case "search":
return "Suggest popular products based on search history."
case _:
return "No specific promotion for this action."# 测试函数
print(apply_promotion_strategy(“add_to_cart”)) # 应输出: Offer a 5% discount on the next purchase.
print(apply_promotion_strategy(“checkout”)) # 应输出: Apply a 10% discount for first-time buyers.
print(apply_promotion_strategy(“view_product”)) # 应输出: Recommend related products.
print(apply_promotion_strategy(“search”)) # 应输出: Suggest popular products based on search history.
print(apply_promotion_strategy(“login”)) # 应输出: No specific promotion for this action.
在这个例子中,apply_promotion_strategy函数根据user_action参数的值来决定返回哪种优惠策略。每个case后面跟着一个用户行为类型,如果匹配成功,就执行相应的代码块并返回优惠信息。_作为默认的匹配模式,用于处理没有明确匹配的情况。
使用match语法的好处是:
-
提高可读性:代码结构清晰,易于理解每个行为对应的优惠策略。 -
减少错误:由于 match语法要求所有可能的情况都被显式处理(包括默认的_),因此减少了遗漏情况的可能性。 -
易于维护:随着业务的发展,添加新的用户行为和优惠策略变得非常简单,只需添加新的 case块即可。
函数式编程
函数式编程(Functional Programming, FP)是一种编程范式,它将计算视为数学函数的评估,并避免使用程序状态以及易变对象。在 Python 中,虽然不是纯粹的函数式编程语言,但支持许多函数式编程的特性,如
map、reduce、filter、any、all、partial函数等。
下面是一个使用函数式编程优化if语句的例子。
场景: 假设我们有一个电商网站的用户列表,我们想要根据用户的购买历史来决定是否向他们发送促销邮件。
原始的if-else语句:
users = [
{"name": "Alice", "purchase_history": ["laptop", "phone"]},
{"name": "Bob", "purchase_history": ["book"]},
{"name": "Charlie", "purchase_history": ["laptop", "book", "phone"]},
# 更多用户...
]for user in users:
if “laptop” in user[“purchase_history”] or “phone” in user[“purchase_history”]:
print(f”Send promo email to {user[‘name’]}“)
else:
print(f”No promo email for {user[‘name’]}“)
使用函数式编程优化后的语句:
from functools import reduceusers = [
{“name”: “Alice”, “purchase_history”: [“laptop”, “phone”]},
{“name”: “Bob”, “purchase_history”: [“book”]},
{“name”: “Charlie”, “purchase_history”: [“laptop”, “book”, “phone”]},
# 更多用户…
]
# 定义一个函数,检查用户是否购买了特定商品
def should_send_promo(_user):
return any(item in _user[“purchase_history”] for item in [“laptop”, “phone”])
# 使用filter函数过滤出需要发送促销邮件的用户
users_to_promo = list(filter(should_send_promo, users))
# 输出结果
for user in users_to_promo:
print(f”Send promo email to {user[‘name’]}“)
# Send promo email to Alice
# Send promo email to Charlie
在这个例子中,我们定义了一个should_send_promo函数,它接受一个用户字典,并返回一个布尔值,指示是否应该向该用户发送促销邮件。然后,我们使用filter函数来过滤出所有满足条件的用户。最后,我们遍历过滤后的用户列表,并打印出需要发送促销邮件的用户。
使用函数式编程的优势包括:
-
可读性:通过将逻辑封装在函数中,代码更加清晰和易于理解。 -
可重用性: should_send_promo函数可以在其他地方重用,而不需要重复相同的逻辑。 -
可测试性:独立的函数更容易进行单元测试。
使用 any() 函数的例子:
场景:检查购物车中是否有任何商品属于”电子产品”类别,如果有,则提供额外的折扣。
def apply_electronics_discount(_cart_items):
# 检查购物车中是否有任何电子产品
if any(item['category'] == '电子产品' for item in _cart_items):
print("提供电子产品额外折扣")
# 应用折扣逻辑...
else:
print("无电子产品折扣")# 示例购物车商品
cart_items = [
{‘name’: ‘智能手机’, ‘category’: ‘电子产品’, ‘price’: 2999},
{‘name’: ‘T恤’, ‘category’: ‘服装’, ‘price’: 99},
{‘name’: ‘笔记本电脑’, ‘category’: ‘电子产品’, ‘price’: 4999}
]
apply_electronics_discount(cart_items) # 提供电子产品额外折扣
使用 all() 函数的例子:
场景:确保购物车中所有商品都有库存,才允许用户结账。
def check_stock(_cart_items):
# 检查购物车中所有商品是否有库存
if all(item['stock'] > 0 for item in _cart_items):
print("所有商品有库存,可以结账")
# 执行结账逻辑...
else:
print("部分商品无库存,请调整购物车")# 示例购物车商品
cart_items = [
{‘name’: ‘智能手机’, ‘stock’: 10},
{‘name’: ‘T恤’, ‘stock’: 0}, # 无库存
{‘name’: ‘笔记本电脑’, ‘stock’: 5}
]
check_stock(cart_items) # 部分商品无库存,请调整购物车
在这两个例子中,any() 函数用于检查购物车中是否有满足特定条件(如类别为”电子产品”)的商品,而 all() 函数则用于确保购物车中的所有商品都满足另一个条件(如所有商品都有库存)。
使用 any() 和 all() 函数可以让代码更加简洁,逻辑更加清晰,并且减少错误的可能性。这些函数提供了一种优雅的方式来处理集合中的元素,而无需编写复杂的循环和条件语句。
使用 sorted() 函数的例子:
场景:电商平台需要根据商品的折扣率和价格来对用户的购物车进行排序,以便展示最优惠的商品。
def sort_cart_items(_cart_items):
# 直接使用sorted函数和lambda表达式进行排序
# 根据折扣率排序,折扣越高越靠前;折扣率相同的情况下按价格排序,价格越低越靠前
sorted_items = sorted(_cart_items, key=lambda x: (x['discount_rate'], -x['price']), reverse=True)
return sorted_items# 示例购物车
cart_items = [
{‘name’: ‘Laptop’, ‘category’: ‘electronics’, ‘price’: 1200, ‘discount_rate’: 0.15},
{‘name’: ‘Jeans’, ‘category’: ‘clothing’, ‘price’: 150, ‘discount_rate’: 0.30},
{‘name’: ‘Jeans’, ‘category’: ‘clothing’, ‘price’: 300, ‘discount_rate’: 0.30},
{‘name’: ‘Jeans’, ‘category’: ‘clothing’, ‘price’: 200, ‘discount_rate’: 0.30},
{‘name’: ‘Python Book’, ‘category’: ‘books’, ‘price’: 75, ‘discount_rate’: 0.20},
{‘name’: ‘Smartphone’, ‘category’: ‘electronics’, ‘price’: 800, ‘discount_rate’: 0.10}
]
print(sort_cart_items(cart_items))
# [{‘name’: ‘Jeans’, ‘category’: ‘clothing’, ‘price’: 150, ‘discount_rate’: 0.3},
# {‘name’: ‘Jeans’, ‘category’: ‘clothing’, ‘price’: 200, ‘discount_rate’: 0.3},
# {‘name’: ‘Jeans’, ‘category’: ‘clothing’, ‘price’: 300, ‘discount_rate’: 0.3},
# {‘name’: ‘Python Book’, ‘category’: ‘books’, ‘price’: 75, ‘discount_rate’: 0.2},
# {‘name’: ‘Laptop’, ‘category’: ‘electronics’, ‘price’: 1200, ‘discount_rate’: 0.15},
# {‘name’: ‘Smartphone’, ‘category’: ‘electronics’, ‘price’: 800, ‘discount_rate’: 0.1}]
使用sorted函数和lambda表达式的好处包括:
-
代码简化:直接在 sorted函数中使用lambda表达式,避免了额外的变量和条件判断。 -
可读性:排序逻辑直观明了,易于理解。 -
灵活性:可以轻松调整排序的依据,只需修改 lambda表达式即可。
这种优化方法使得代码更加简洁、清晰,并且易于维护和扩展。
使用 functools.partial 函数的例子:
在很多场景中,使用functools.partial(偏函数)可以优化涉及大量重复参数的函数调用。例如,考虑一个电商平台,我们需要根据不同的商品类别应用不同的折扣策略,并且这些策略可能会频繁地被使用。
首先,定义一个基础的折扣函数,它接受商品价格和折扣率作为参数:
from functools import partialdef apply_discount(price, discount_rate):
return price * discount_rate
然后,为每种商品类别创建一个偏函数,这些偏函数已经预设了特定的折扣率:
# 电子产品折扣率
electronics_discount = partial(apply_discount, discount_rate=0.95)
# 服装折扣率
clothing_discount = partial(apply_discount, discount_rate=0.9)
# 图书折扣率
books_discount = partial(apply_discount, discount_rate=0.85)
现在,我们可以在代码中直接使用这些偏函数,而不需要重复编写折扣率参数。这在处理大量订单和商品时非常有用,因为它减少了代码重复,并使得逻辑更加清晰。
假设我们有一个函数,根据用户购买的商品类别来计算折扣后的价格:
def calculate_discounted_price(cart_items, discount_func):
total_price = sum(item['price'] * item['quantity'] for item in cart_items)
return discount_func(total_price)# 示例购物车商品
cart_items = [
{‘name’: ‘Laptop’, ‘category’: ‘electronics’, ‘price’: 1200, ‘quantity’: 1},
{‘name’: ‘Jeans’, ‘category’: ‘clothing’, ‘price’: 200, ‘quantity’: 2},
{‘name’: ‘Python Book’, ‘category’: ‘books’, ‘price’: 50, ‘quantity’: 3},
]
# 根据商品类别应用折扣
discounted_price_electronics = calculate_discounted_price(
[item for item in cart_items if item[‘category’] == ‘electronics’],
electronics_discount
)
discounted_price_clothing = calculate_discounted_price(
[item for item in cart_items if item[‘category’] == ‘clothing’],
clothing_discount
)
discounted_price_books = calculate_discounted_price(
[item for item in cart_items if item[‘category’] == ‘books’],
books_discount
)
print(f”Discounted Price for Electronics: {discounted_price_electronics}“)
print(f”Discounted Price for Clothing: {discounted_price_clothing}“)
print(f”Discounted Price for Books: {discounted_price_books}“)
# Discounted Price for Electronics: 1140.0
# Discounted Price for Clothing: 360.0
# Discounted Price for Books: 127.5
在这个例子中,我们根据商品类别筛选购物车中的商品,并使用相应的偏函数来计算折扣后的价格。这种方法使得代码更加模块化,易于维护,并且减少了if语句的使用。
使用偏函数的好处包括:
-
减少代码重复:避免在多个地方重复相同的函数参数。 -
提高代码可读性:通过偏函数传递的参数更清晰地表达了代码的意图。 -
易于维护:如果折扣率发生变化,只需更新偏函数的定义,而不需要在多处修改代码。
函数式编程提供了一种不同的思考问题和编写代码的方式,可以帮助我们编写出更加简洁、清晰和可维护的代码。
使用多态
多态是一种面向对象编程中的概念,它允许我们使用同一个接口来调用不同类的对象的方法。在电商场景中,多态可以用来优化处理不同类型商品或不同用户行为的逻辑。
假设我们有一个电商平台,需要根据用户购买的商品类型应用不同的折扣策略。我们可以为每种商品类型定义一个具体的折扣策略类,然后使用一个抽象基类来统一这些策略的接口。
定义折扣策略的抽象基类:
from abc import ABC, abstractmethodclass DiscountStrategy(ABC):
@abstractmethod
def apply_discount(self, price):
pass
为不同类型的商品实现具体的折扣策略:
class ElectronicsDiscountStrategy(DiscountStrategy):
def apply_discount(self, price):
# 假设电子产品有固定的折扣
return price * 0.9class ClothingDiscountStrategy(DiscountStrategy):
def apply_discount(self, price):
# 假设服装有基于价格的动态折扣
return max(price * 0.8, price – 50)
class BookDiscountStrategy(DiscountStrategy):
def apply_discount(self, price):
# 假设书籍有买二赠一的优惠
return price * 0.67 # 相当于买三本只付两本的钱
创建一个电商系统类来使用这些策略:
class ECommerceSystem:
def __init__(self, product_type, price):
self.product_type = product_type
self.price = price
self.discount_strategy = self.set_discount_strategy()def set_discount_strategy(self):
# 根据商品类型设置折扣策略
strategies = {
‘electronics’: ElectronicsDiscountStrategy(),
‘clothing’: ClothingDiscountStrategy(),
‘book’: BookDiscountStrategy()
}
return strategies.get(self.product_type.lower(), None)
def calculate_discounted_price(self):
if self.discount_strategy:
return self.discount_strategy.apply_discount(self.price)
else:
return self.price # 如果没有折扣策略,则返回原价
# 使用示例
product_types = [‘electronics’, ‘clothing’, ‘book’, ‘unknown’]
prices = [2000, 100, 50, 1000]
for _product_type, _price in zip(product_types, prices):
ecommerce = ECommerceSystem(_product_type, _price)
discounted_price = ecommerce.calculate_discounted_price()
print(f”The discounted price for {_product_type} is: {discounted_price}“)
# The discounted price for electronics is: 1800.0
# The discounted price for clothing is: 80.0
# The discounted price for book is: 33.5
# The discounted price for unknown is: 1000
在这个例子中,ECommerceSystem 类根据商品类型初始化相应的折扣策略。set_discount_strategy 方法根据商品类型返回正确的折扣策略对象。calculate_discounted_price 方法应用折扣策略来计算折扣后的价格。
使用多态的好处包括:
-
解耦:将折扣策略的实现从使用折扣策略的代码中解耦。 -
扩展性:可以轻松添加新的折扣策略,而不需要修改现有的代码。 -
可维护性:每种折扣策略的实现都在其对应的类中,易于管理和维护。
通过使用多态,我们可以避免复杂的 if-else 或 match-case 语句,而是通过对象的接口来统一调用,使得代码更加清晰和灵活。
使用枚举类提升代码可读性
使用枚举类(Enum)可以有效地管理固定集合的常量。
在电商应用中,如商品类别、订单状态、支付方式等。通过替代传统的字符串或数字常量,枚举类可以增强代码的可读性和健壮性,也即增加if-else语句的清晰度和可维护性。
以下是一个使用枚举类来优化if语句的电商场景例子:
定义商品类别的枚举类:
from enum import Enumclass ProductCategory(Enum):
ELECTRONICS = 1
CLOTHING = 2
BOOKS = 3
BEAUTY = 4
定义订单状态的枚举类:
class OrderStatus(Enum):
PENDING = 1
CONFIRMED = 2
SHIPPED = 3
DELIVERED = 4
CANCELED = 5
使用枚举类来处理订单:
def process_order(order):
status_actions = {
OrderStatus.PENDING: "Processing pending order.",
OrderStatus.CONFIRMED: "Order confirmed. Preparing for shipment.",
OrderStatus.SHIPPED: "Order shipped. On the way to customer.",
OrderStatus.DELIVERED: "Order delivered.",
OrderStatus.CANCELED: "Order canceled.",
}action = status_actions.get(order[‘status’], “Unknown order status.”)
print(action)
# 示例订单
orders = [
{‘status’: OrderStatus.PENDING},
{‘status’: OrderStatus.CONFIRMED},
{‘status’: OrderStatus.SHIPPED},
{‘status’: OrderStatus.DELIVERED},
{‘status’: OrderStatus.CANCELED}
]
for _order in orders:
process_order(_order)
# Processing pending order.
# Order confirmed. Preparing for shipment.
# Order shipped. On the way to customer.
# Order delivered.
# Order canceled.
在这个例子中,我们定义了ProductCategory和OrderStatus两个枚举类,分别表示商品的类别和订单的状态。在process_order函数中,我们根据订单的状态来决定执行哪种处理逻辑。由于使用了枚举类,我们避免了使用大量的if-else语句,同时也使得代码更加安全(防止无效的状态值)和易于维护。
使用枚举类的好处包括:
-
类型安全:枚举类提供了固定的集合,避免了无效值的使用。 -
提高可读性:使用枚举类使得代码更易读,状态或类别的名称比数字或字符串常量更清晰。 -
减少错误:枚举类减少了拼写错误的可能性,并且可以在开发环境中提供更好的自动完成支持。 -
易于维护:当需要添加新的状态或类别时,只需在枚举类中添加新的成员即可。
通过这种方式,枚举类帮助我们编写出更清晰、更健壮的代码,同时简化了逻辑处理。
结丹期
善用策略模式
策略模式是一种行为设计模式,它定义了一系列的算法,并将每一个算法封装起来,并使它们可以相互替换。此模式让算法的变化独立于使用算法的客户。在电商场景中,策略模式可以用来根据不同的促销规则或优惠策略动态地改变行为。
假设我们有一个电商平台,需要根据不同的用户类别(如新用户、老用户、VIP用户)应用不同的折扣策略。
以下是使用策略模式来优化if语句的示例。
首先,我们定义一个折扣策略的接口(抽象基类):
from abc import ABC, abstractmethodclass DiscountStrategy(ABC):
@abstractmethod
def apply_discount(self, price):
pass
然后,我们为每种用户类别实现具体的策略:
class NewUserDiscount(DiscountStrategy):
def apply_discount(self, price):
return price * 0.95 # 新用户享受5%的折扣class RegularUserDiscount(DiscountStrategy):
def apply_discount(self, price):
return price # 普通用户无折扣
class VIPUserDiscount(DiscountStrategy):
def apply_discount(self, price):
return price * 0.85 # VIP用户享受15%的折扣
接下来,我们创建一个上下文环境,该环境根据用户类别使用不同的策略:
class DiscountContext:
def __init__(self, strategy: DiscountStrategy):
self.strategy = strategydef calculate_final_price(self, price):
return self.strategy.apply_discount(price)
最后,我们根据用户类别来设置相应的折扣策略:
# 使用字典映射来选择折扣策略
strategy_map = {
"new_user": NewUserDiscount(),
"regular_user": RegularUserDiscount(),
"vip_user": VIPUserDiscount(),
}def apply_discount_strategy(user_category, original_price):
try:
discount_strategy = strategy_map[user_category]
discount_context = DiscountContext(discount_strategy)
final_price = discount_context.calculate_final_price(original_price)
return final_price
except KeyError:
raise ValueError(“Unknown user category”)
# 测试不同的用户类别
print(apply_discount_strategy(“new_user”, 100)) # 应输出: 95.0
print(apply_discount_strategy(“regular_user”, 100)) # 应输出: 100
print(apply_discount_strategy(“vip_user”, 100)) # 应输出: 85.0
在这个例子中,DiscountStrategy是一个抽象基类,定义了一个apply_discount方法,所有的折扣策略类都必须实现这个方法。NewUserDiscount、RegularUserDiscount和VIPUserDiscount是具体的策略类,它们实现了不同的折扣逻辑。
DiscountContext是一个上下文环境类,它持有一个DiscountStrategy对象,并使用这个策略对象来计算最终价格。
apply_discount_strategy函数根据用户类别创建相应的DiscountContext实例,并计算出应用折扣后的价格。
使用装饰器改进策略模式
from abc import ABC, abstractmethod
from functools import wrapsclass DiscountStrategy(ABC):
@abstractmethod
def apply_discount(self, price):
pass
class NewUserDiscount(DiscountStrategy):
def apply_discount(self, price):
return price * 0.95
class RegularUserDiscount(DiscountStrategy):
def apply_discount(self, price):
return price
class VIPUserDiscount(DiscountStrategy):
def apply_discount(self, price):
return price * 0.85
# 折扣策略实例映射
strategy_map = {
“new_user”: NewUserDiscount(),
“regular_user”: RegularUserDiscount(),
“vip_user”: VIPUserDiscount(),
}
# 装饰器工厂,根据用户类别应用折扣
def apply_discount(strategy):
def decorator(func):
@wraps(func)
def wrapper(price, *args, **kwargs):
# 应用折扣策略
discounted_price = strategy.apply_discount(price)
return func(discounted_price, *args, **kwargs)
return wrapper
return decorator
# 提前创建装饰器字典
discount_decorators = {
user_category: apply_discount(strategy) for user_category, strategy in strategy_map.items()
}
# 单一的调用入口函数
def display_price_for_user(user_category, original_price):
# 获取并应用相应的折扣装饰器
decorated_func = discount_decorators.get(user_category)
if not decorated_func:
raise ValueError(“Unknown user category”)
@decorated_func
def price_after_discount(price):
return price # 这里实际不需要做任何操作,只是装饰器会应用折扣
# 调用装饰器包装的函数来获取折扣后的价格
final_price = price_after_discount(original_price)
return f”Price for {user_category} user: ${final_price:.2f}“
# 测试不同的用户类别
print(display_price_for_user(“new_user”, 100)) # 应输出: Price for new_user user: $95.0
print(display_price_for_user(“regular_user”, 100)) # 应输出: Price for regular_user user: $100.0
print(display_price_for_user(“vip_user”, 100)) # 应输出: Price for vip_user user: $85.0
使用策略模式的好处包括:
-
开闭原则:对扩展开放,对修改封闭。可以轻松添加新的折扣策略,而不需要修改现有的代码。 -
解耦决策和执行:将使用策略的对象与策略的具体实现解耦。 -
易于切换策略:可以在运行时根据不同的条件切换策略。
这种模式使得代码更加模块化,易于管理和扩展,特别是在业务逻辑复杂且经常变化的情况下。
在
CPython中,这种设计模式已被采用,尤其是在cmd.Cmd类中,它通过定义特定的do_前缀方法来实现命令行界面的命令功能。例如,广为人知的Python调试器pdb,正是通过实现这些do_方法来处理用户命令的。
使用发布订阅者模式
发布订阅者模式(也称为观察者模式)是一种设计模式,它定义了对象之间的一对多依赖关系,当一个对象改变状态时,所有依赖于它的对象都会得到通知。在电商场景中,这种模式可以用于优化涉及多个条件分支的
if语句,尤其是当系统中有多个组件需要对某些事件做出响应时。
场景:假设我们有一个电商平台,根据用户的行为(如添加商品到购物车、商品库存不足等事件),不同的部分(如优惠系统、通知系统、库存管理系统)需要做出响应。
原生代码硬撸
我们通常会在事件发生的地方直接编写处理逻辑,这往往会导致代码中出现大量的if语句。
class ProductAddedEvent:
pass # 可以添加更多与产品添加相关的属性class InventoryLowEvent:
pass # 可以添加更多与库存不足相关的属性
# 优惠系统
def apply_discount_rules(product_id):
print(f”Applying discount rules for product ID {product_id}.”)
# 通知系统
def send_low_inventory_notification(product_id):
print(f”Sending low inventory notification for product ID {product_id}.”)
# 库存管理系统
def trigger_restocking_process(product_id):
print(f”Triggering restocking process for product ID {product_id}.”)
# 事件处理函数
def handle_event(event, product_id):
if isinstance(event, ProductAddedEvent):
apply_discount_rules(product_id)
elif isinstance(event, InventoryLowEvent):
send_low_inventory_notification(product_id)
trigger_restocking_process(product_id)
# 模拟事件处理
product_added_event = ProductAddedEvent()
inventory_low_event = InventoryLowEvent()
handle_event(product_added_event, 123) # 应输出: Applying discount rules for product ID 123.
handle_event(inventory_low_event, 456) # 应输出: Sending low inventory notification for product ID 456.
# 然后输出: Triggering restocking process for product ID 456.
在这个原生实现中:
-
我们定义了 ProductAddedEvent和InventoryLowEvent类来表示不同的事件。 -
我们为每种响应定义了单独的函数: apply_discount_rules、send_low_inventory_notification和trigger_restocking_process。 -
handle_event函数根据事件类型直接调用相应的处理函数。
使用原生实现方式的缺点包括:
-
代码重复:随着事件类型的增加,可能需要在多个地方编写相似的逻辑。 -
紧耦合:事件处理逻辑与事件触发逻辑紧密耦合,使得代码难以维护和扩展。 -
可维护性差:当新增事件类型或处理逻辑时,需要修改多个地方的代码。
发布订阅模式
首先,我们定义一个事件发布者和事件订阅者的基本结构:
class Event:
def __init__(self, type, data):
self.type = type
self.data = dataclass EventPublisher:
def __init__(self):
self._subscribers = []
def subscribe(self, subscriber):
self._subscribers.append(subscriber)
def unsubscribe(self, subscriber):
self._subscribers.remove(subscriber)
def notify(self, event):
for subscriber in self._subscribers:
subscriber.update(event)
class EventSubscriber:
def update(self, event):
raise NotImplementedError(“Subclasses should implement this!”)
然后,我们定义具体的事件和订阅者:
class ProductAddedEvent(Event):
pass # 可以添加更多与产品添加相关的属性class InventoryLowEvent(Event):
pass # 可以添加更多与库存不足相关的属性
class DiscountSystem(EventSubscriber):
def update(self, event):
if isinstance(event, ProductAddedEvent):
print(f”Applying discount rules for added product ID {event.data[‘product_id’]}.”)
class NotificationSystem(EventSubscriber):
def update(self, event):
if isinstance(event, InventoryLowEvent):
print(f”Sending low inventory notification for product ID {event.data[‘product_id’]}.”)
class InventoryManagementSystem(EventSubscriber):
def update(self, event):
if isinstance(event, InventoryLowEvent):
print(f”Triggering restocking process for product ID {event.data[‘product_id’]}.”)
最后,我们创建一个系统来管理事件发布和订阅逻辑:
def main():
# 创建事件发布者
event_publisher = EventPublisher()# 创建订阅者并注册到发布者
discount_system = DiscountSystem()
notification_system = NotificationSystem()
inventory_management_system = InventoryManagementSystem()
event_publisher.subscribe(discount_system)
event_publisher.subscribe(notification_system)
event_publisher.subscribe(inventory_management_system)
# 模拟事件
product_added_event = ProductAddedEvent(type=“PRODUCT_ADDED”, data={“product_id”: 123})
inventory_low_event = InventoryLowEvent(type=“INVENTORY_LOW”, data={“product_id”: 456})
# 发布事件
event_publisher.notify(product_added_event) # 优惠系统将响应
event_publisher.notify(inventory_low_event) # 通知系统和库存管理系统将响应
if __name__ == “__main__”:
main()
# Applying discount rules for added product ID 123.
# Sending low inventory notification for product ID 456.
# Triggering restocking process for product ID 456.
在这个例子中:
-
EventPublisher是事件发布者,它维护了一个订阅者列表,并在发生事件时通知他们。 -
EventSubscriber是事件订阅者的基类,具体的订阅者类(如DiscountSystem、NotificationSystem和InventoryManagementSystem)实现了update方法来响应特定的事件。 -
在 main函数中,我们创建了发布者和订阅者,将订阅者注册到发布者上,并模拟了两个事件来展示系统如何响应。
使用发布订阅者模式的好处包括:
-
解耦:事件发布者和订阅者之间的耦合度降低,系统更加灵活。 -
扩展性:添加新的事件类型或新的订阅者变得更加简单,不需要修改现有的代码。 -
可维护性:每个订阅者负责处理特定的逻辑,使得代码更加模块化,易于理解和维护。
通过这种方式,我们可以避免使用复杂的if语句来处理多种条件,而是让事件驱动系统的不同部分协同工作。
blinker库便应用了这一机制,感兴趣的可以当做案例自行研究。
小结
在Python编程中,“减少”或优化if statement的使用对提高代码的可读性和可维护性非常重要。
-
利用 Python的内置特性,例如in、and / or、真值测试、字典推导、条件表达式和异常处理,可以简化代码。 -
函数式编程技术,包括 filter()、map()、reduce()、lambda表达式和高阶函数,进一步推动了声明式编程,减少了逻辑判断的需求。 -
面向对象的设计原则,如多态性、策略模式和枚举类,有效减少了条件分支,提高了代码的清晰度。 -
实践表明,采用策略模式和字典映射可以显著优化条件逻辑,并增强其扩展性。
总的来说,恰当应用设计模式不仅减轻了对if语句的依赖,还显著提升了代码质量,促进了持续改进的编程思维。

原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/90108.html
