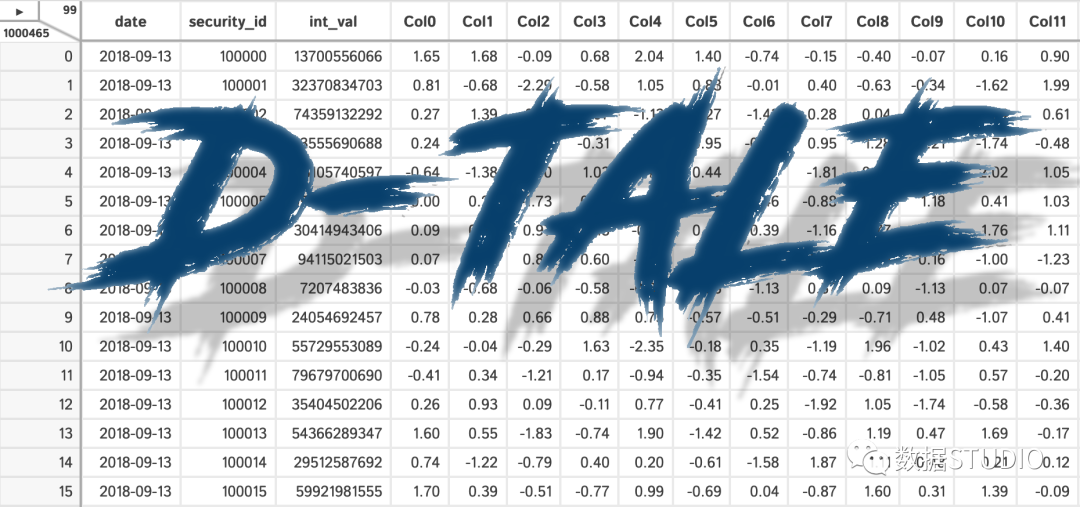
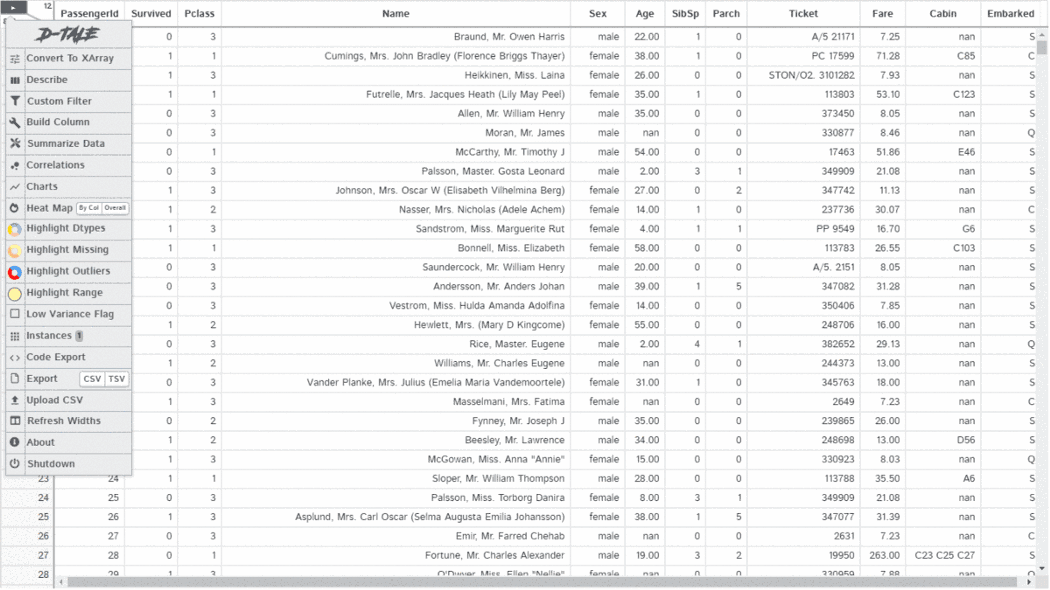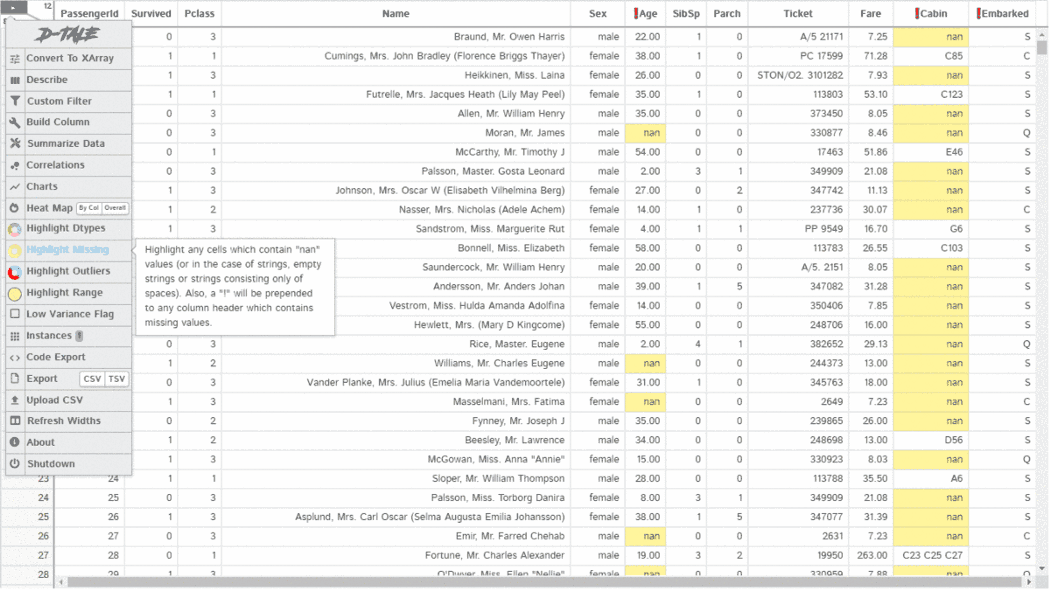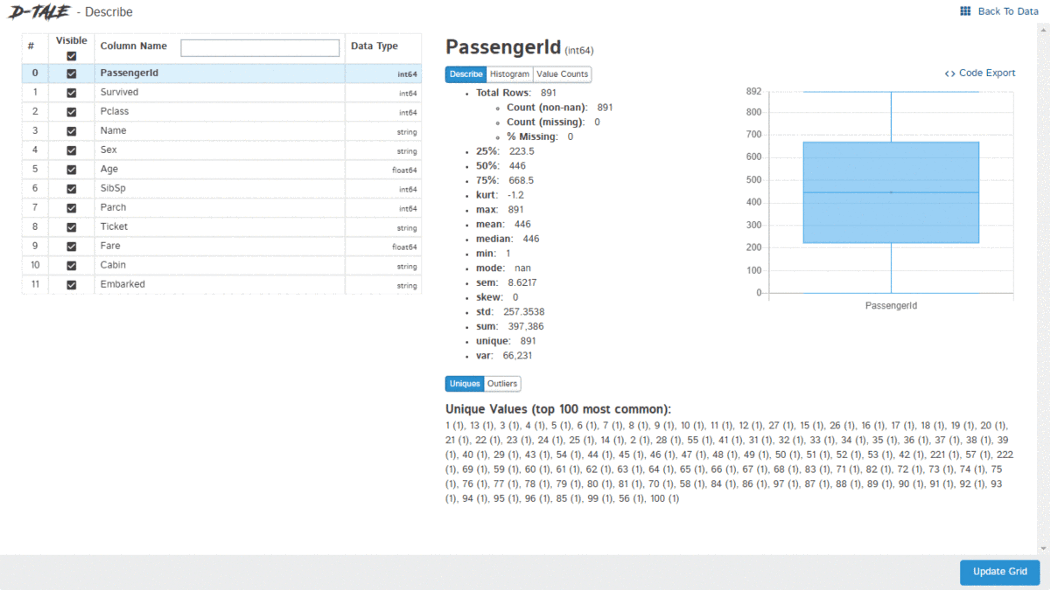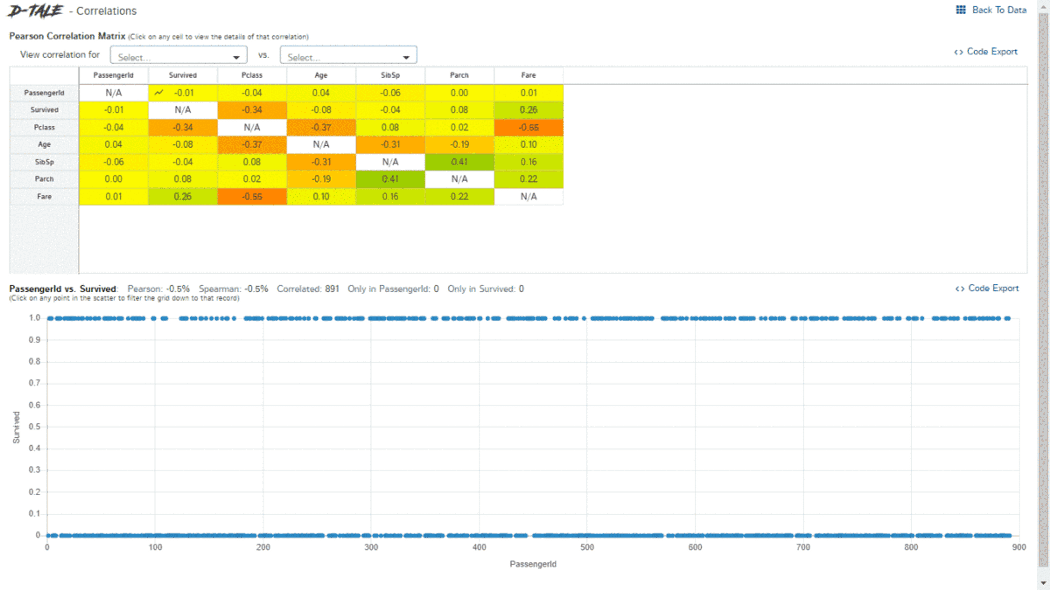
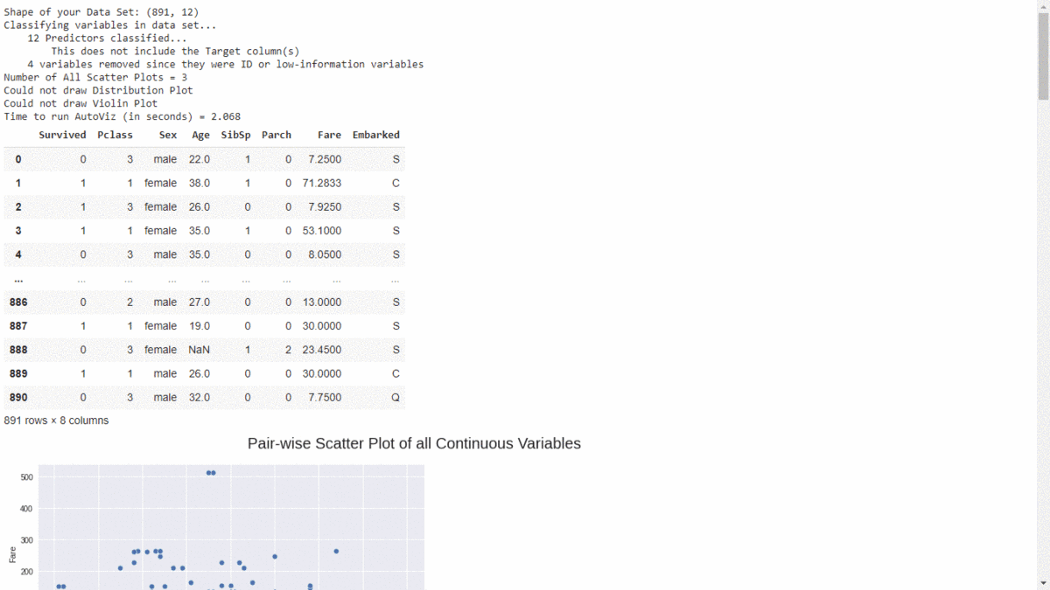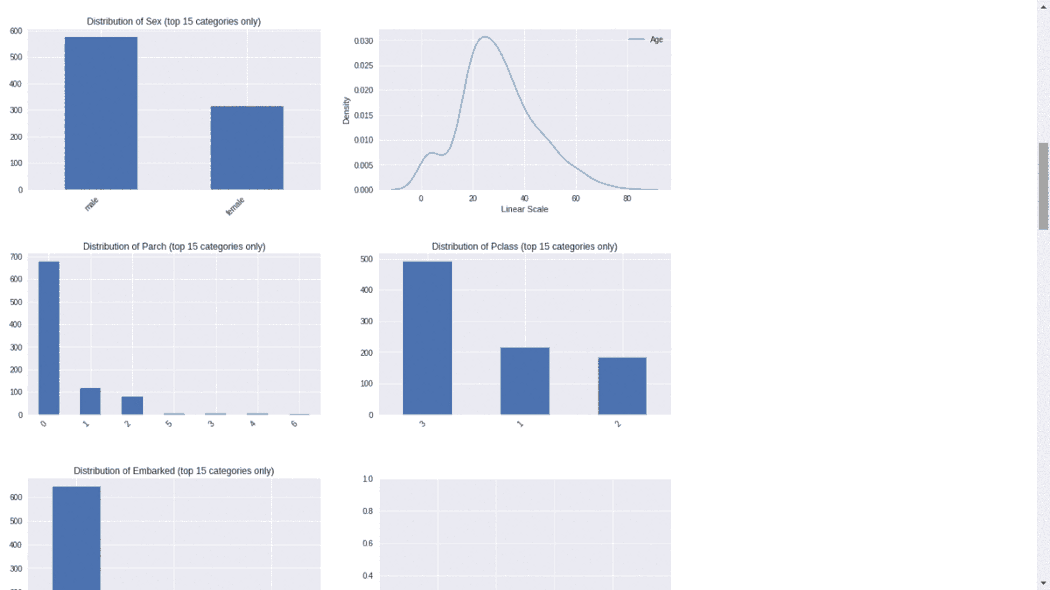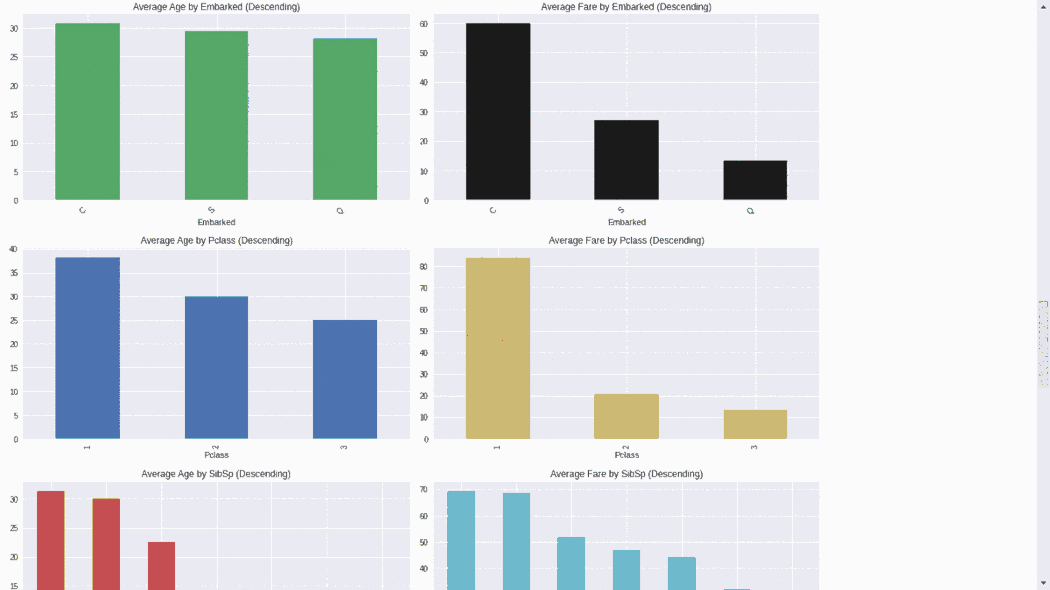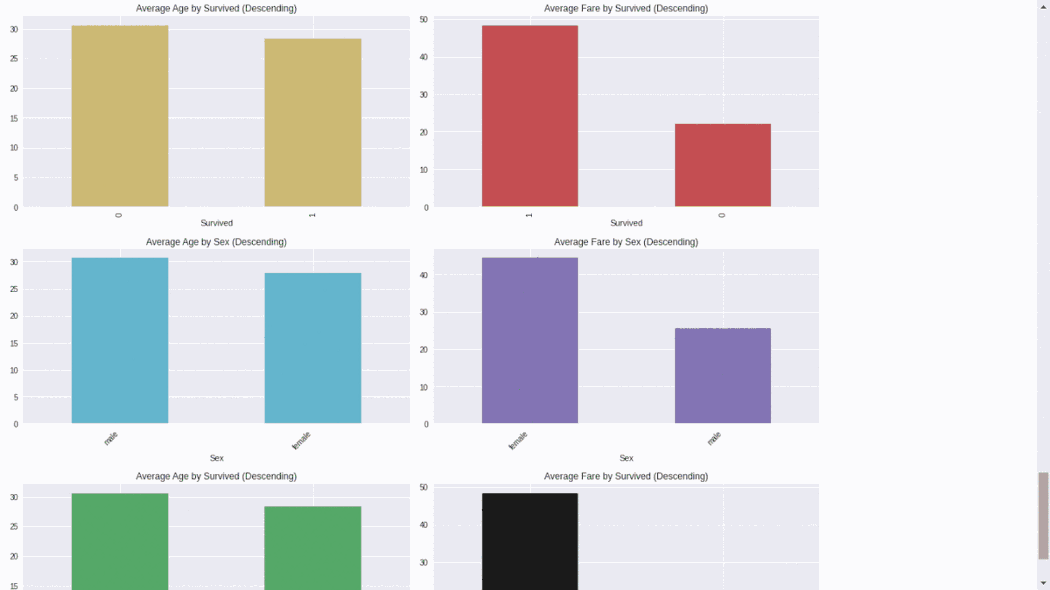
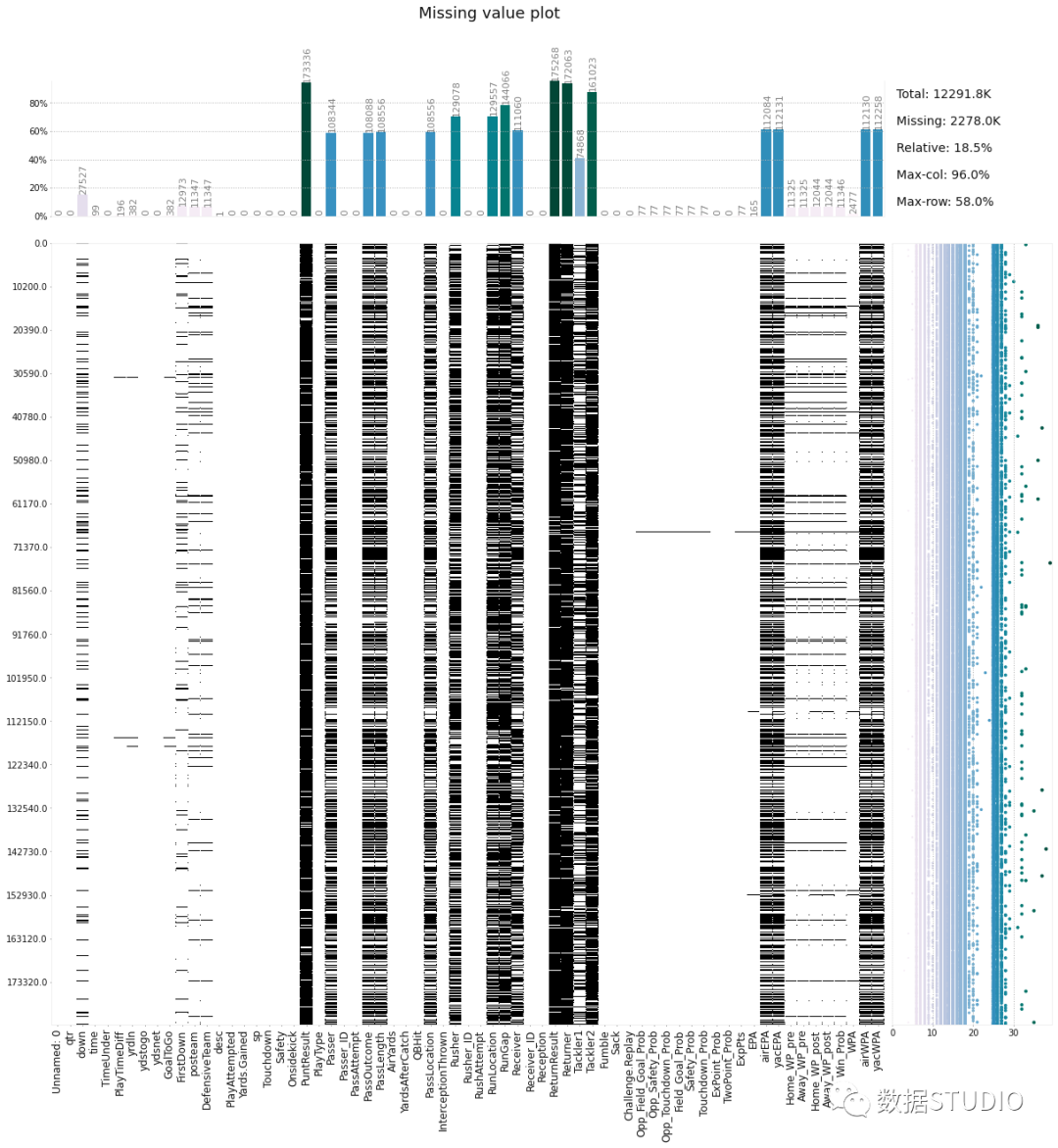
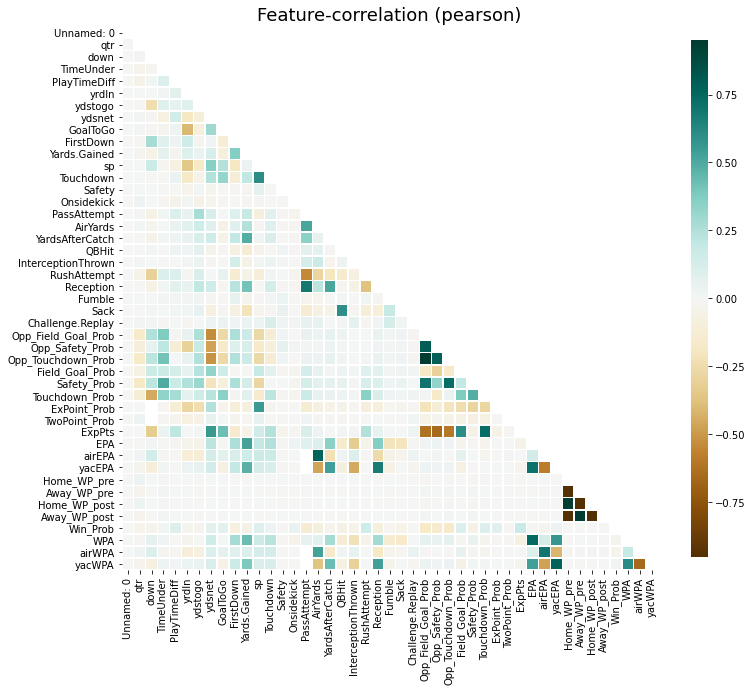
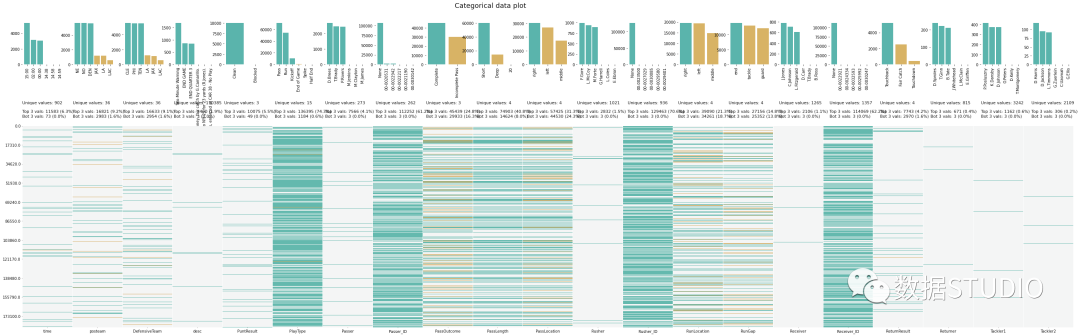
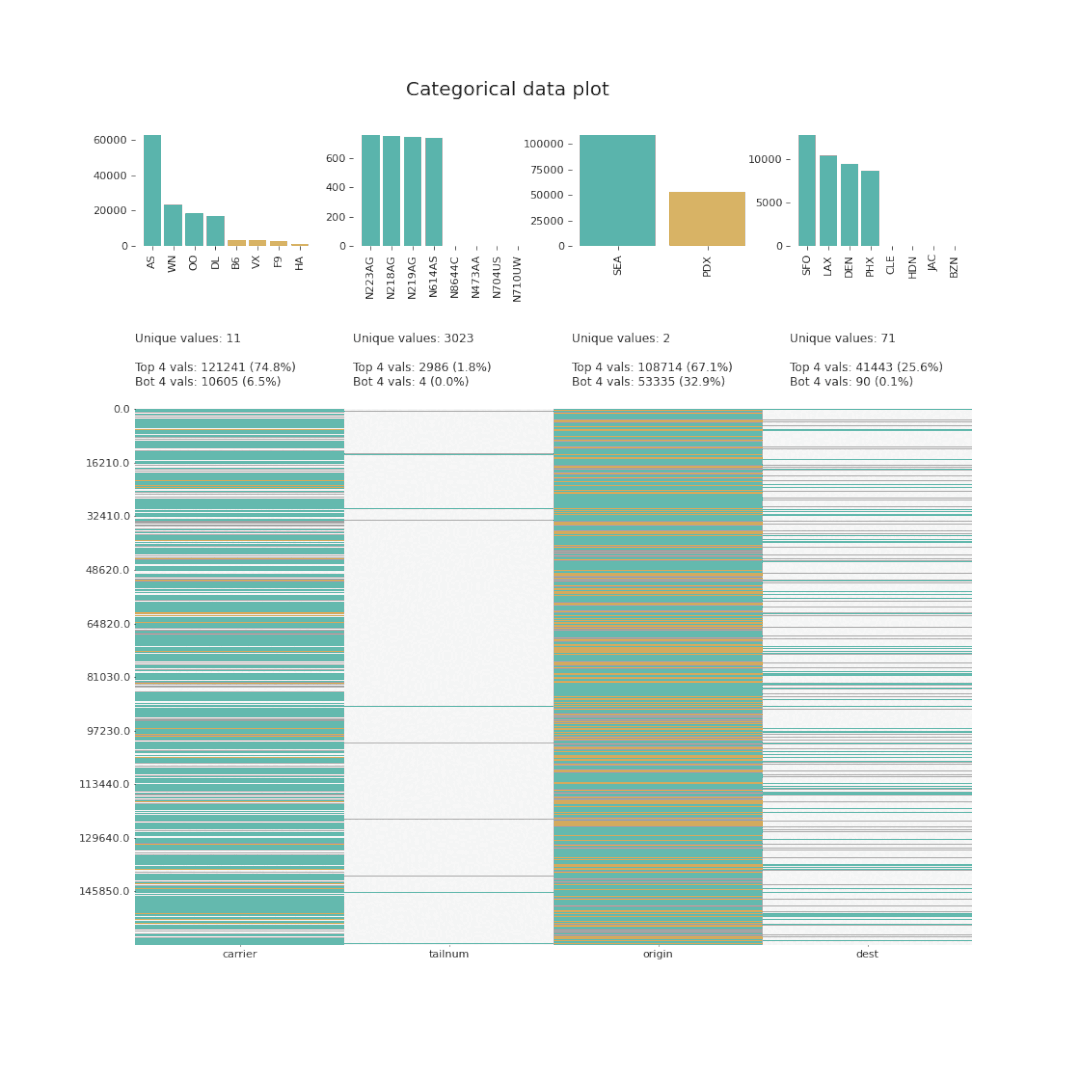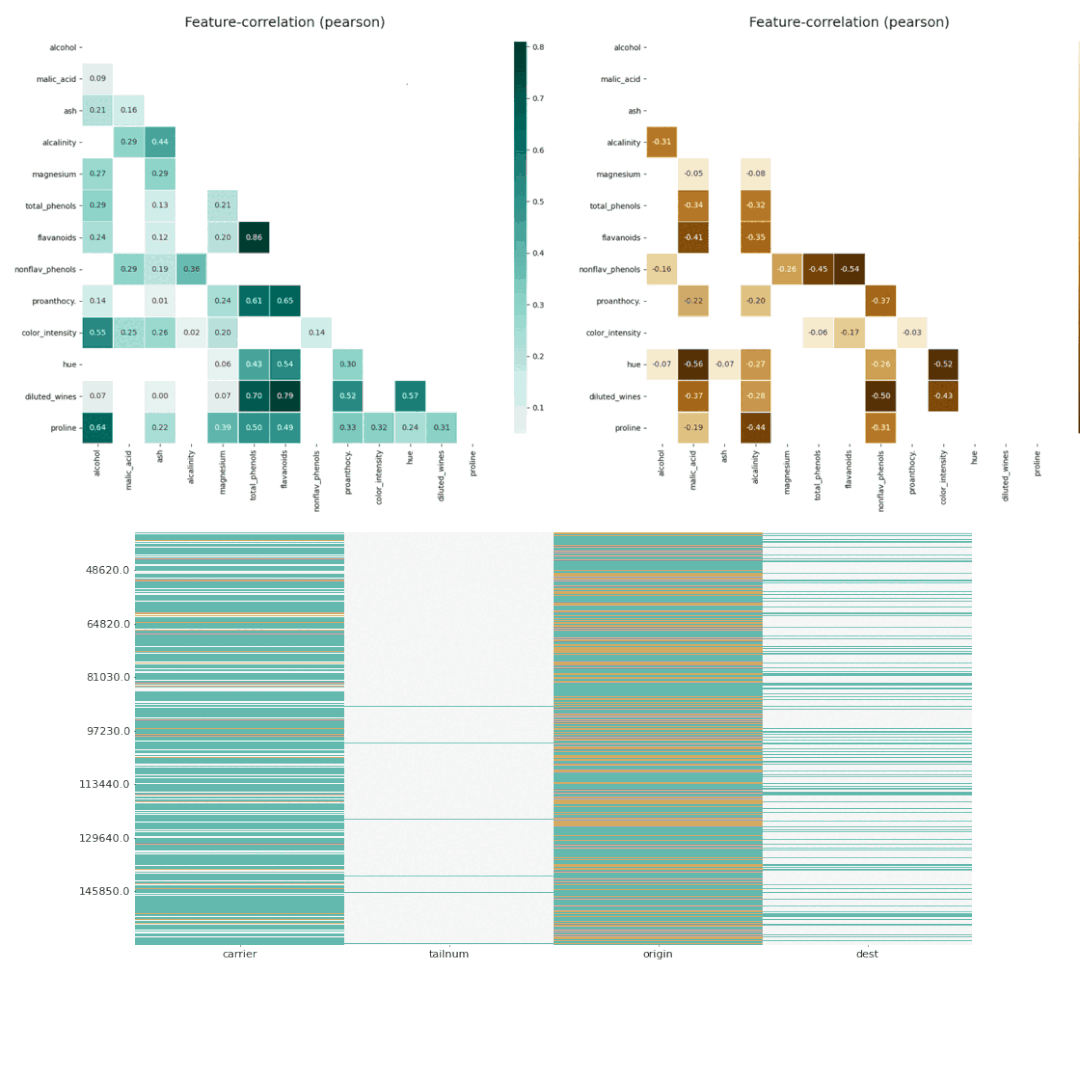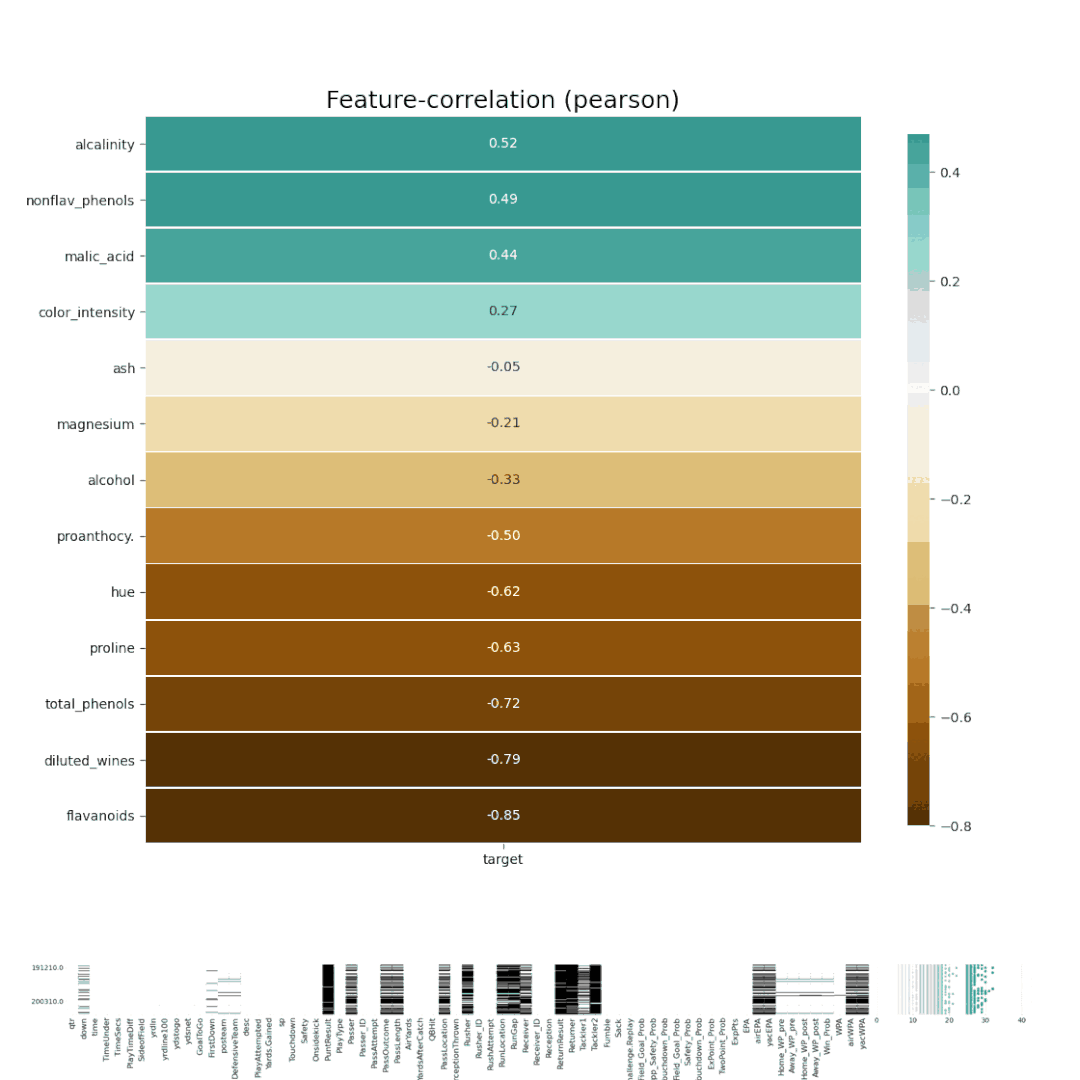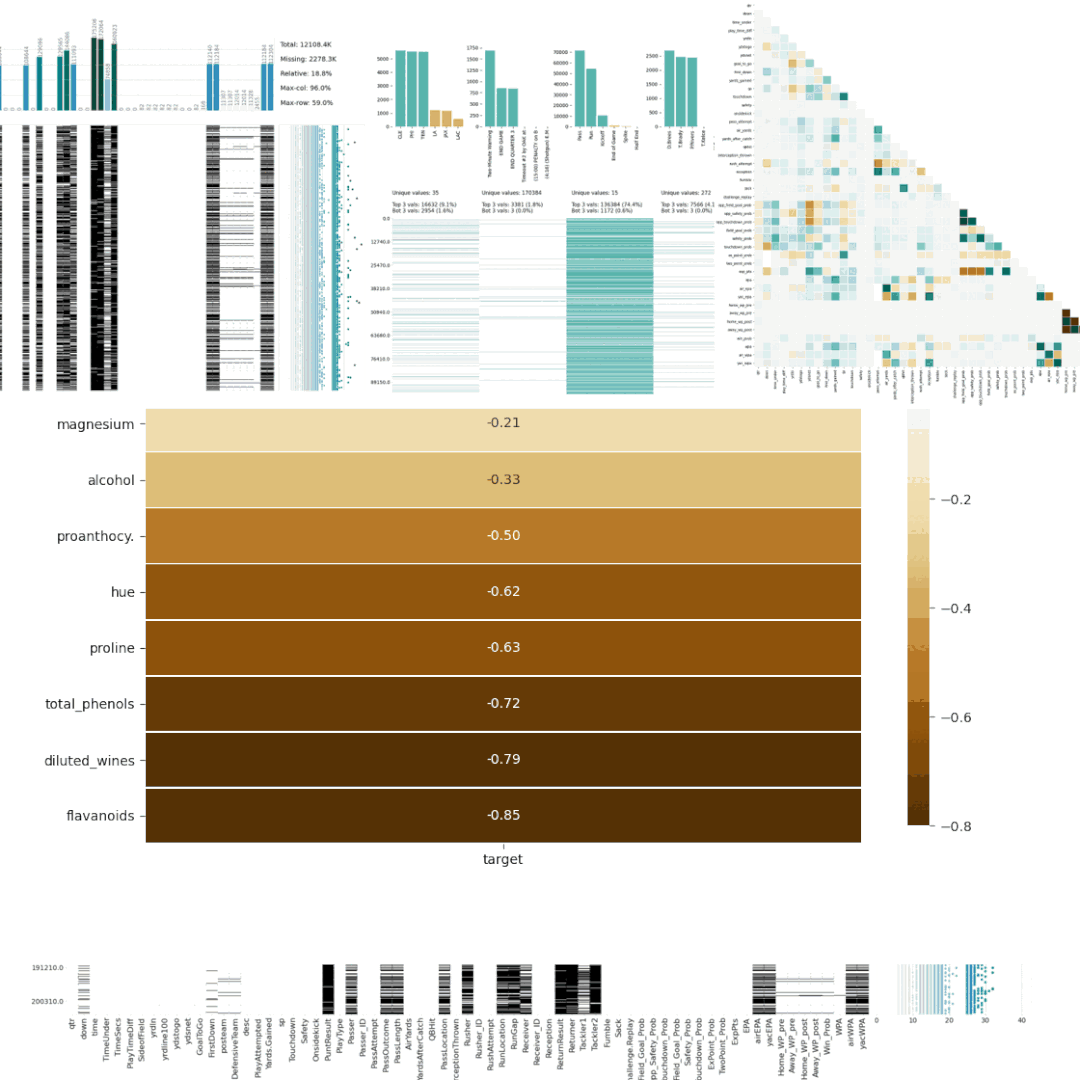
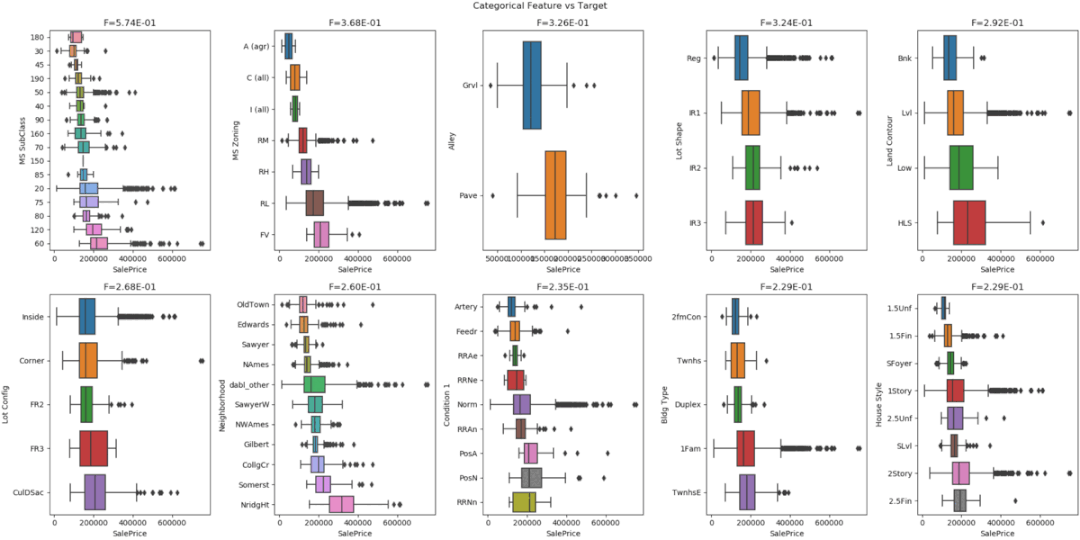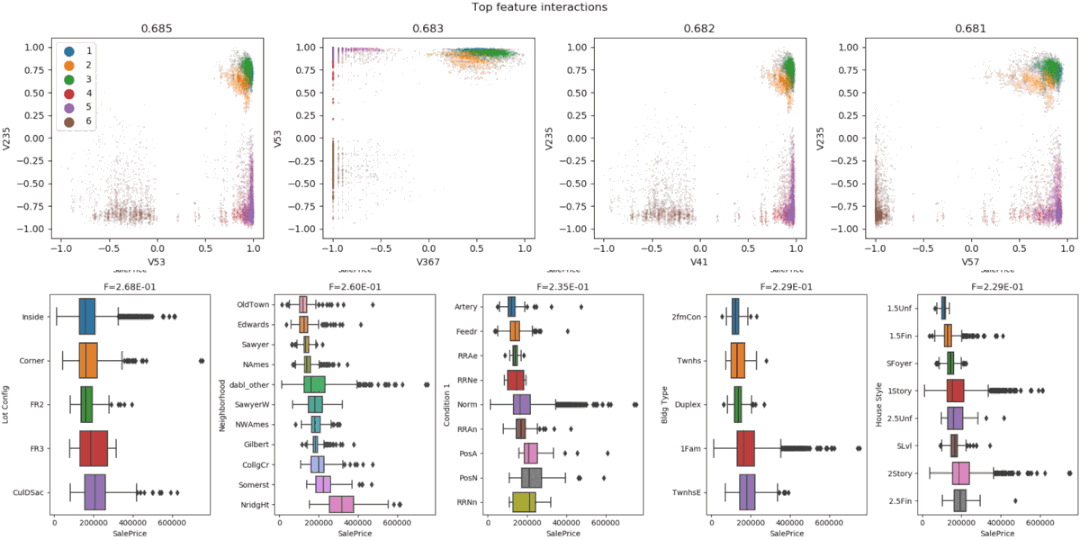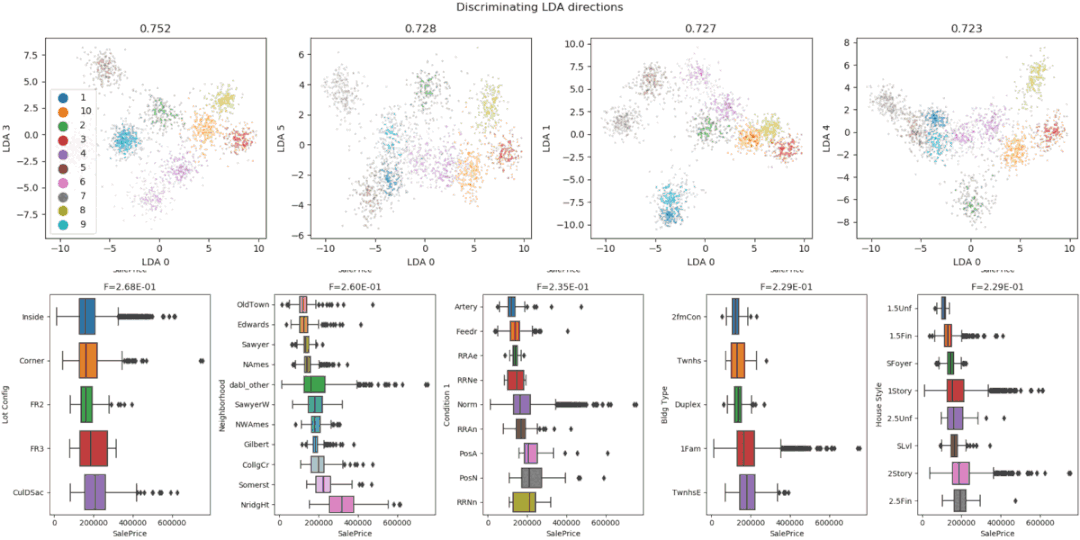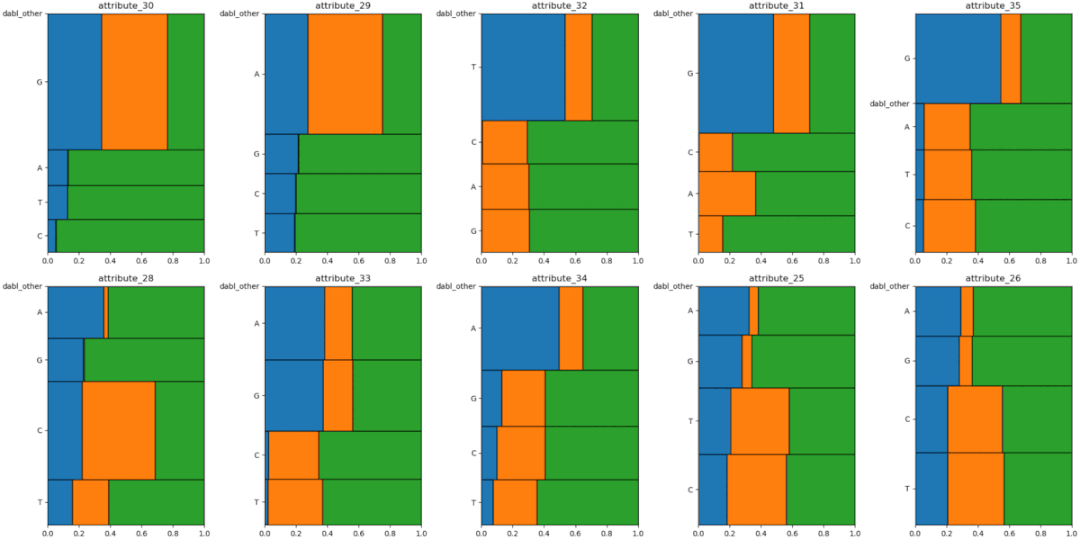
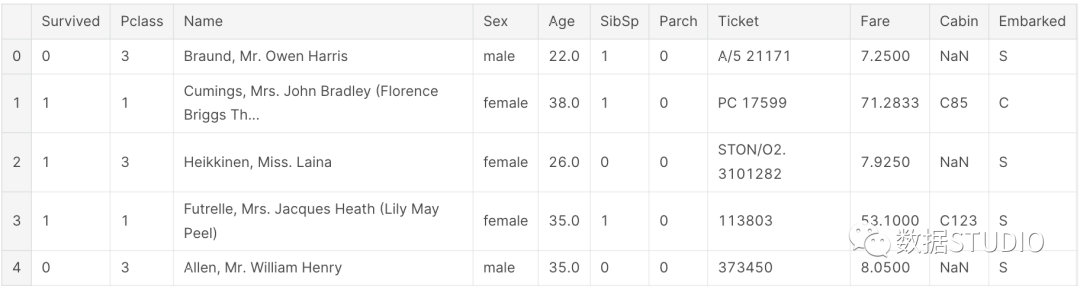
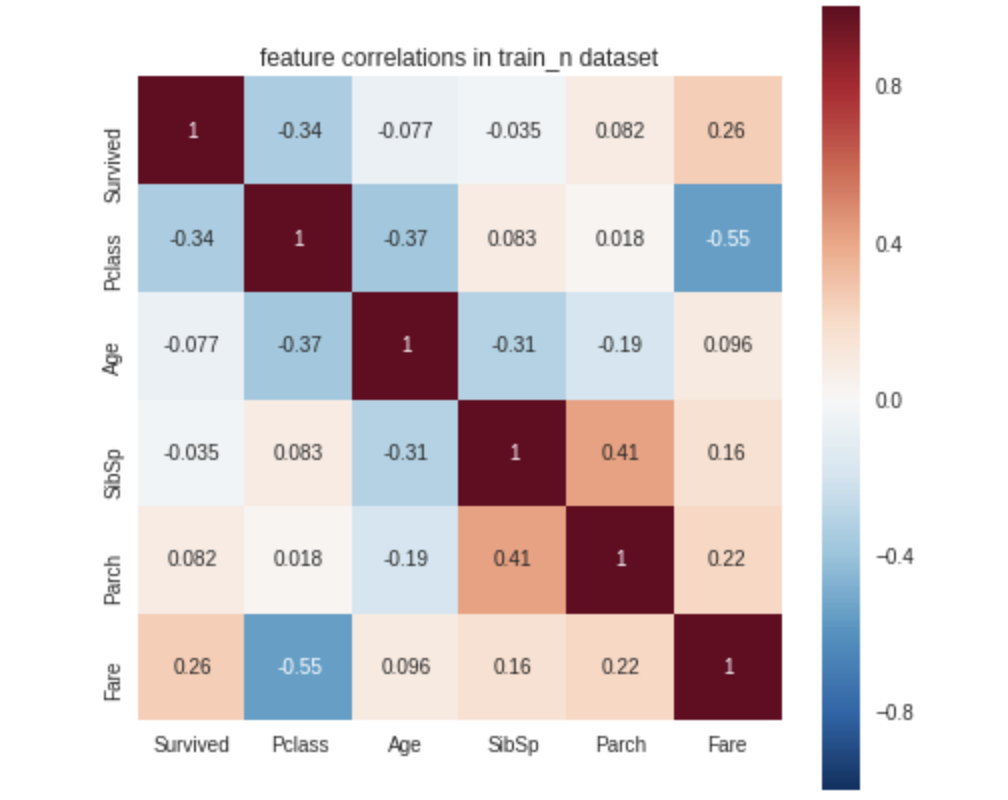
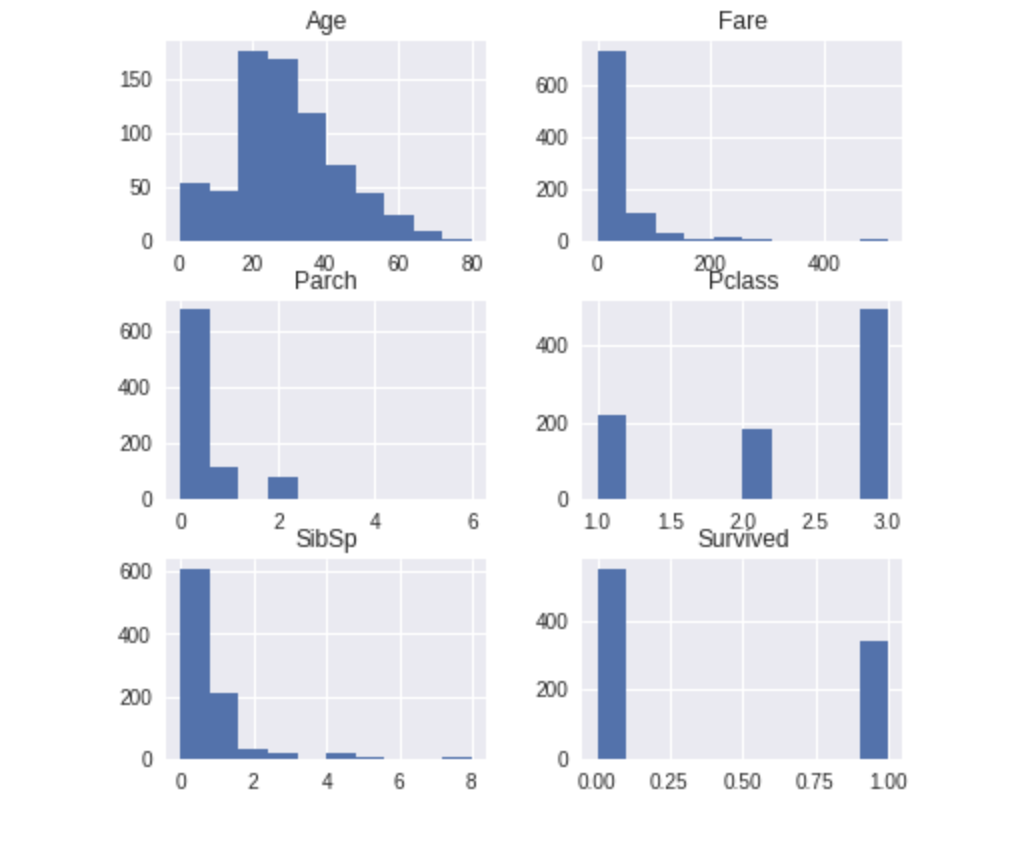
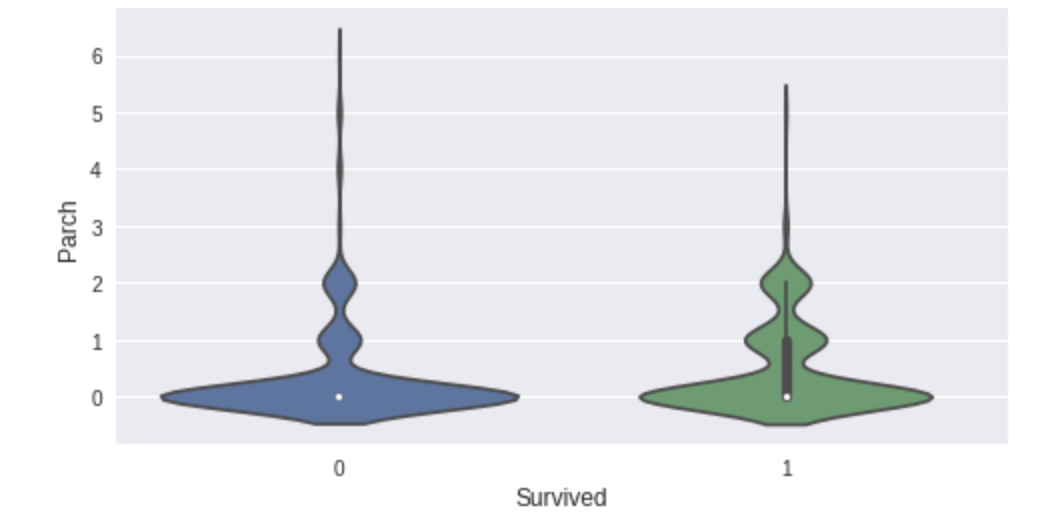
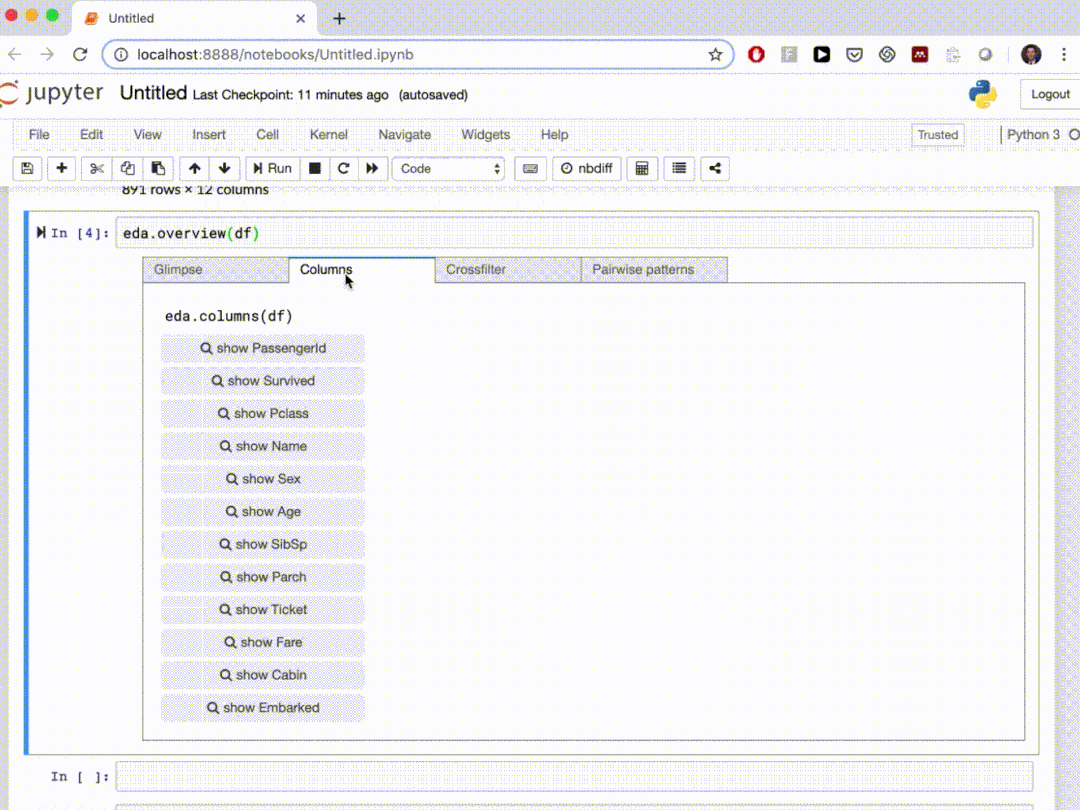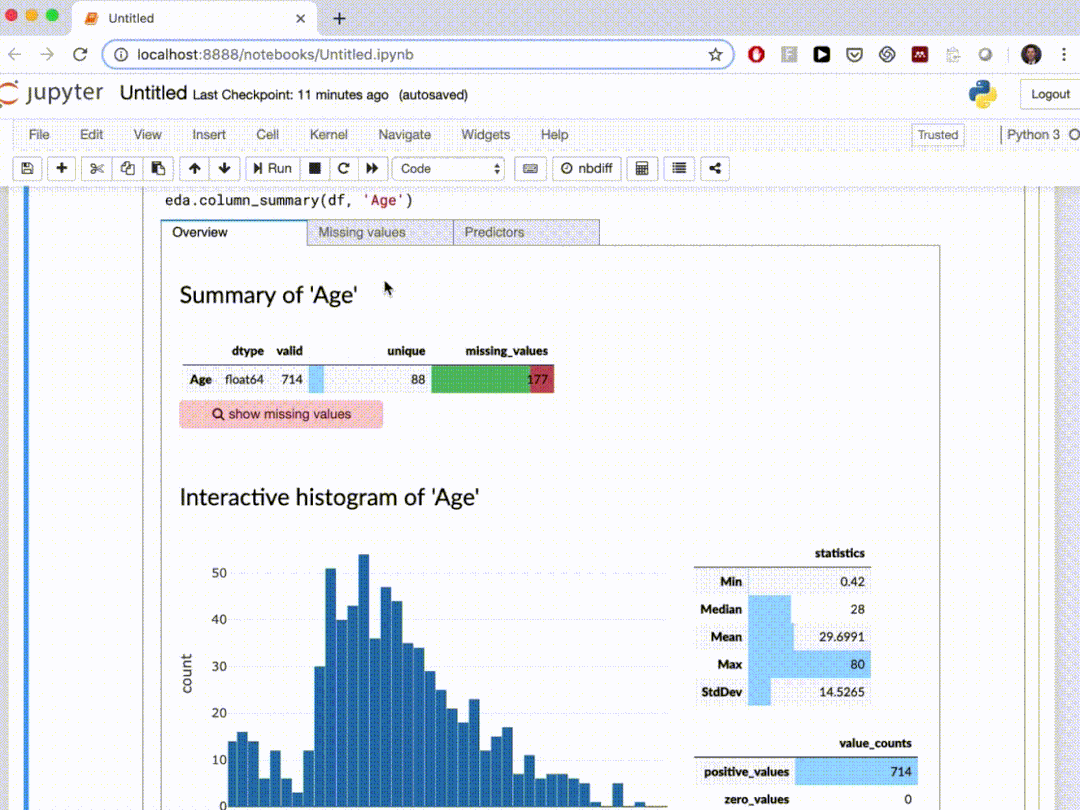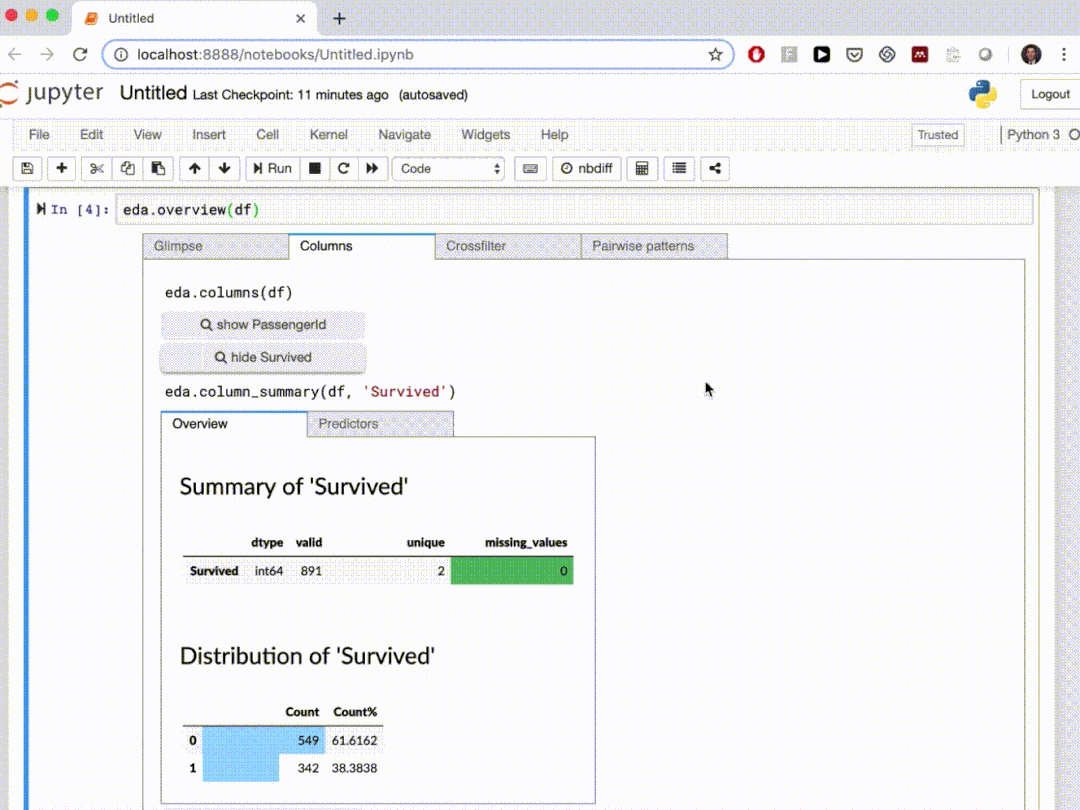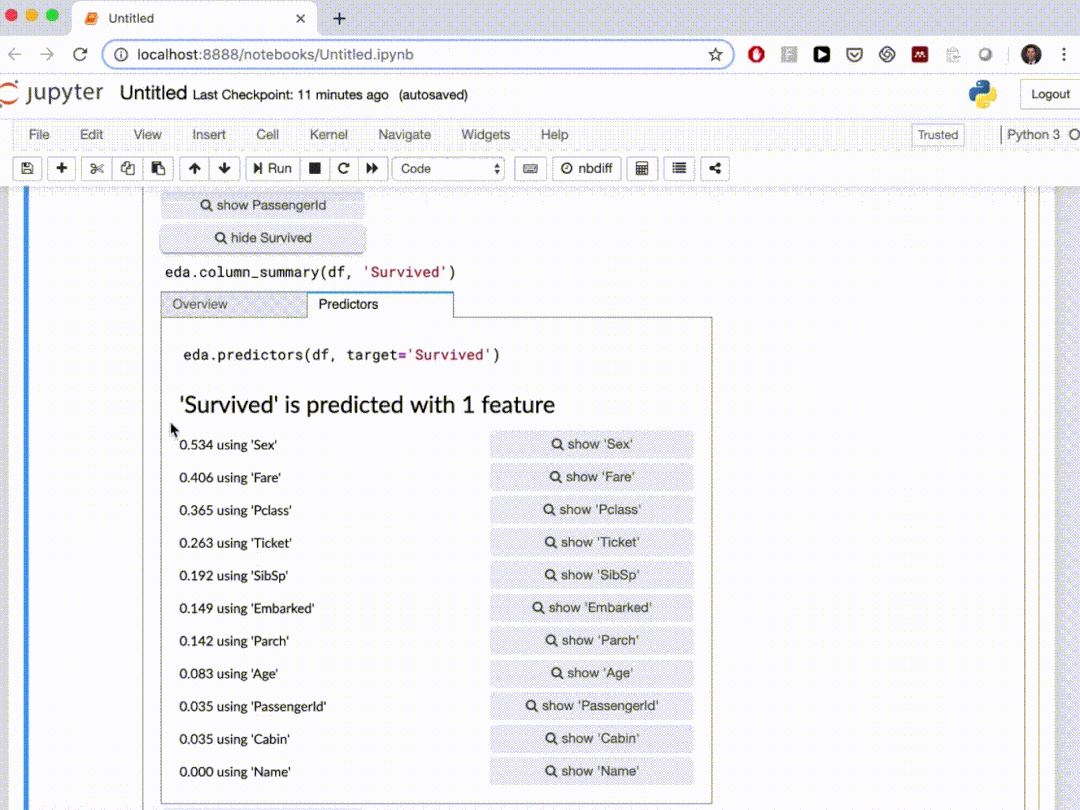
D-Tale使用Flask作为后端、React前端并且可以与ipython notebook和终端无缝集成。D-Tale可以支持Pandas的DataFrame, Series, MultiIndex, DatetimeIndex和RangeIndex。import dtale
import pandas as pd
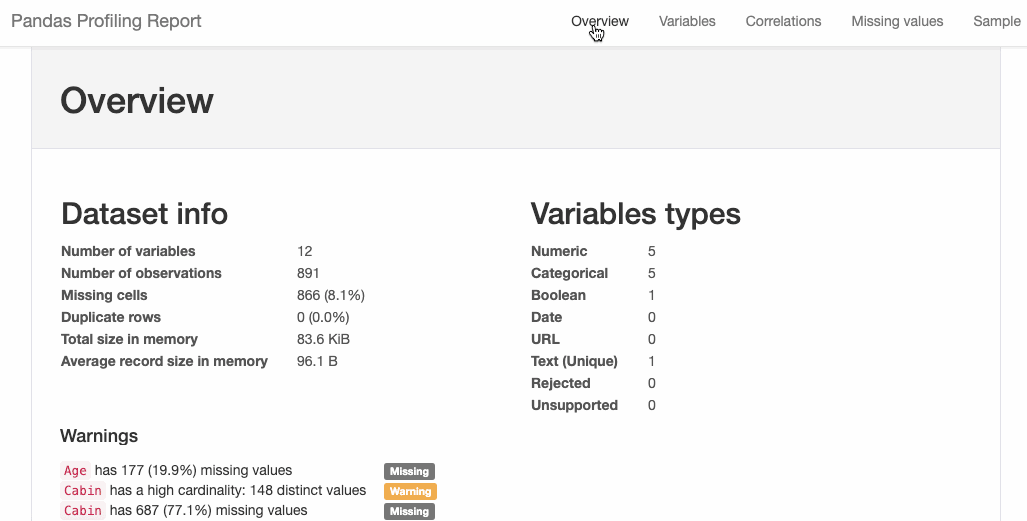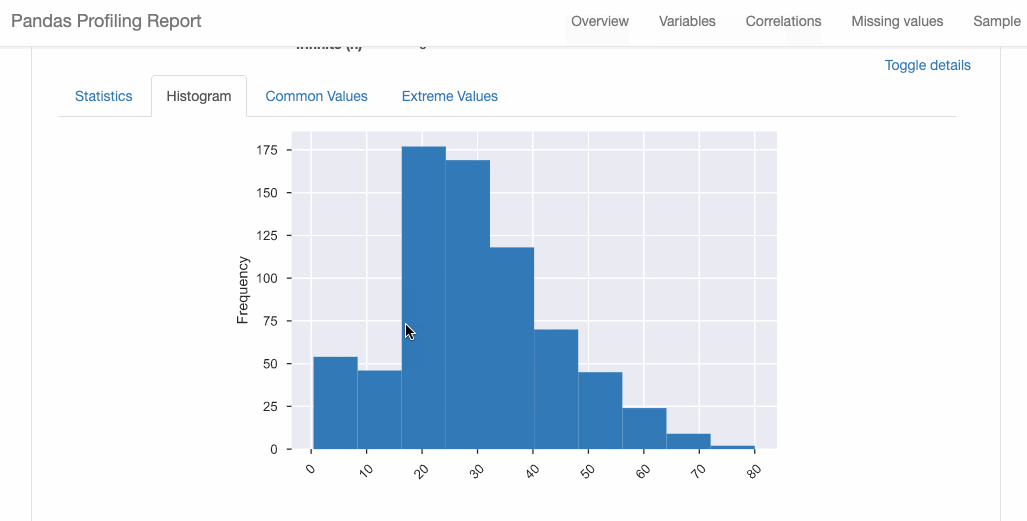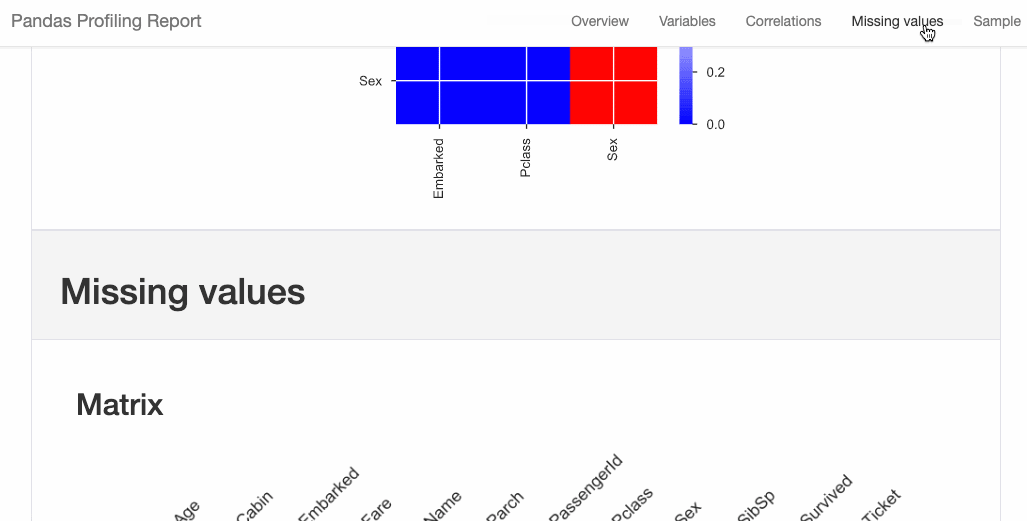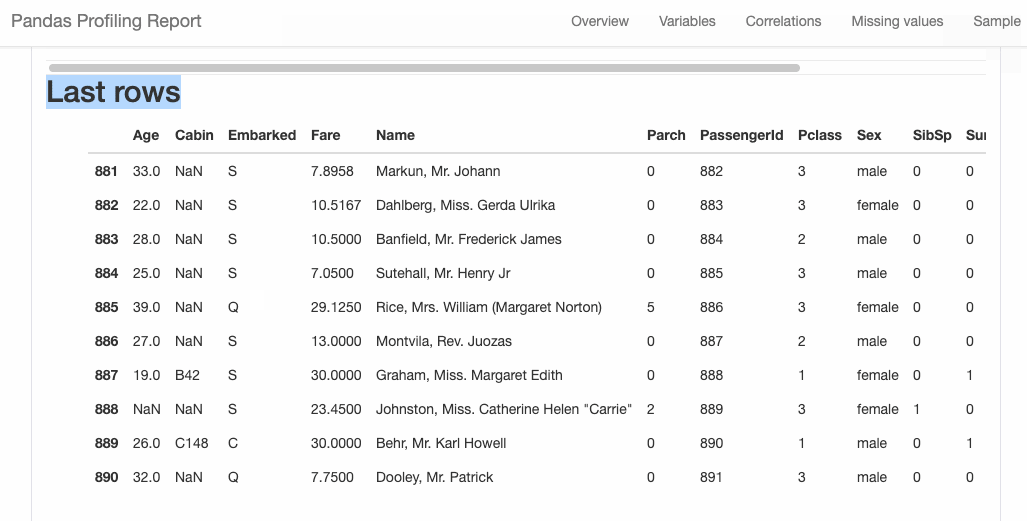
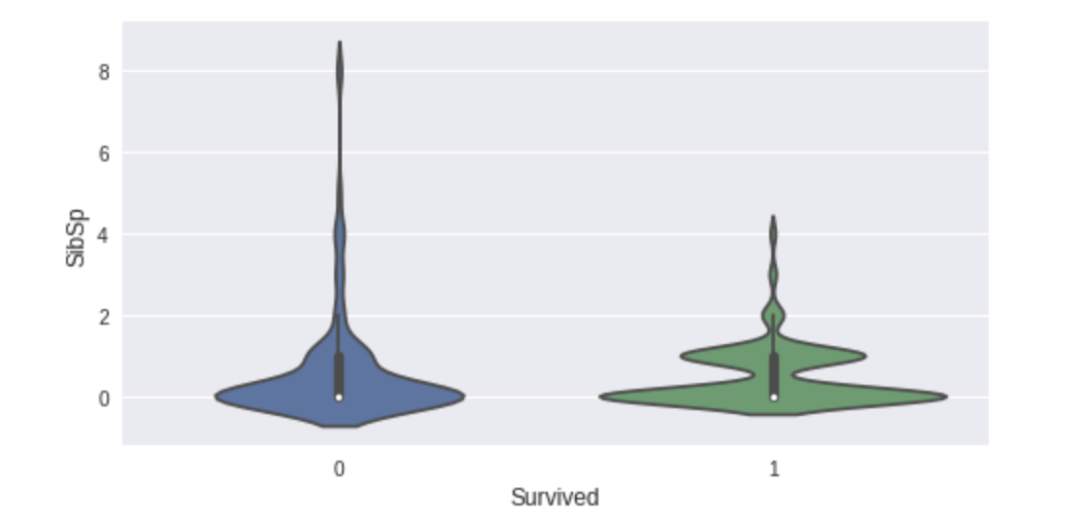
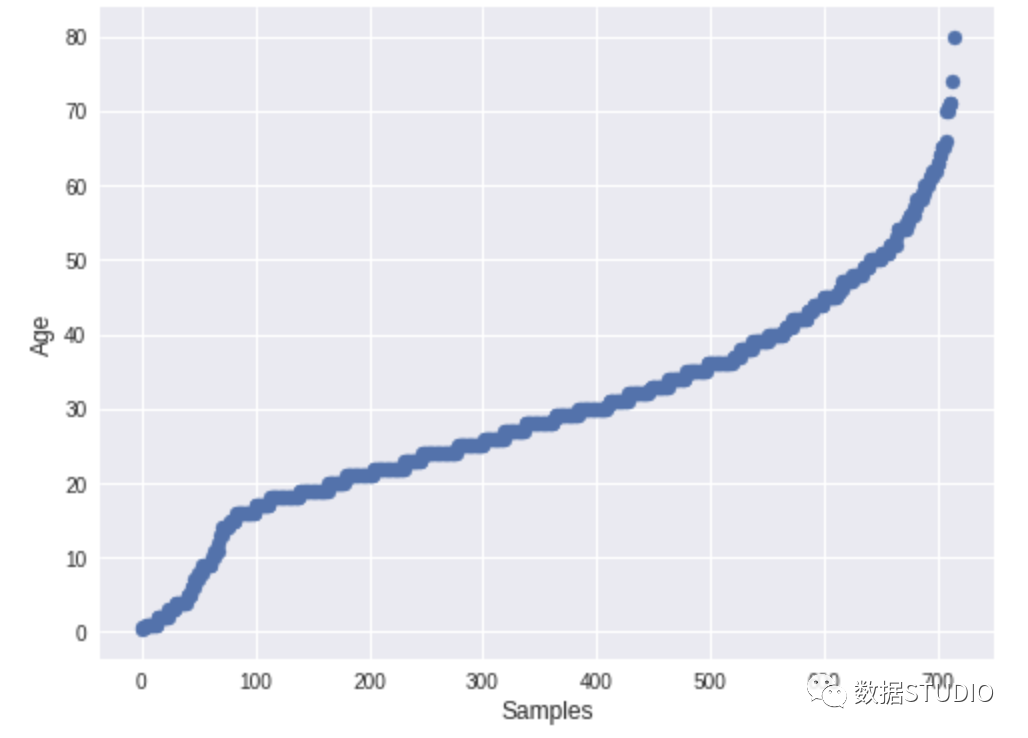
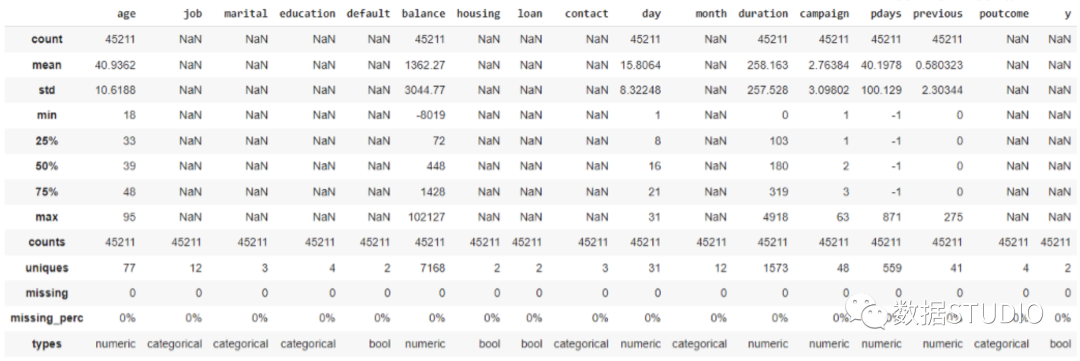
dtale.show(pd.read_csv(“titanic.csv”))D-Tale库用一行代码就可以生成一个报告,其中包含数据集、相关性、图表和热图的总体总结,并突出显示缺失的值等。D-Tale还可以为报告中的每个图表进行分析,上面截图中我们可以看到图表是可以进行交互操作的。2、Pandas-ProfilingPandas-Profiling可以生成Pandas DataFrame的概要报告。panda-profiling扩展了pandas DataFrame df.profile_report(),并且在大型数据集上工作得非常好,它可以在几秒钟内创建报告。#Install the below libaries before importing
import pandas as pd
from pandas_profiling import ProfileReport
#EDA using pandas-profiling profile = ProfileReport(pd.read_csv(‘titanic.csv’), explorative=True)
#Saving results to a HTML file profile.to_file(“output.html”)
3、SweetvizSweetviz是一个开源的Python库,只需要两行Python代码就可以生成漂亮的可视化图,将EDA(探索性数据分析)作为一个HTML应用程序启动。Sweetviz包是围绕快速可视化目标值和比较数据集构建的。import pandas as pd import sweetviz as sv
#EDA using Autoviz sweet_report = sv.analyze(pd.read_csv(“titanic.csv”))
#Saving results to HTML file sweet_report.show_html(‘sweet_report.html’)
Sweetviz库生成的报告包含数据集、相关性、分类和数字特征关联等的总体总结。4、AutoVizAutoviz包可以用一行代码自动可视化任何大小的数据集,并自动生成HTML、bokeh等报告。用户可以与AutoViz包生成的HTML报告进行交互。import pandas as pd from autoviz.AutoViz_Class import AutoViz_Class
#EDA using Autoviz autoviz = AutoViz_Class().AutoViz(‘train.csv’)
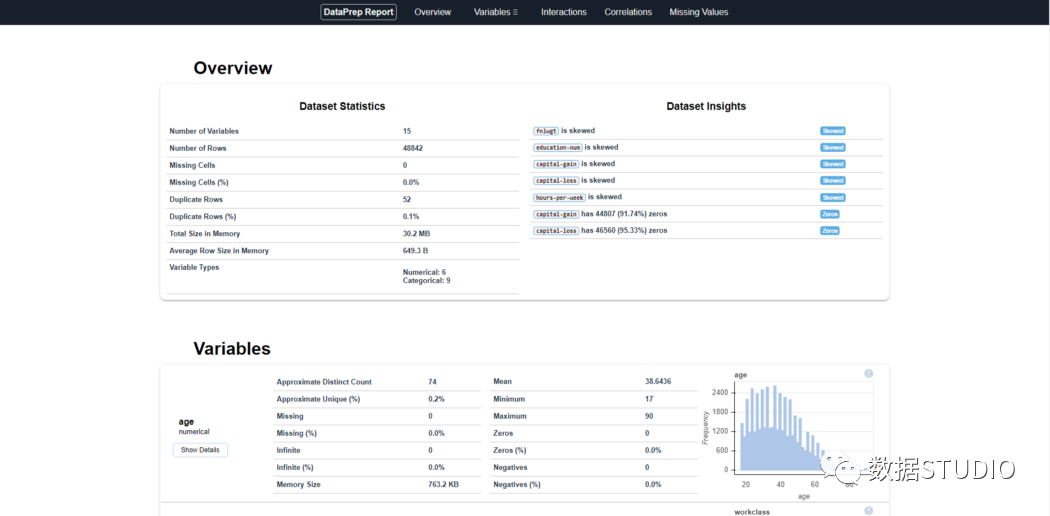
5、DataprepDataprep是一个用于分析、准备和处理数据的开源Python包。DataPrep构建在Pandas和Dask DataFrame之上,可以很容易地与其他Python库集成。DataPrep的运行速度这10个包中最快的,他在几秒钟内就可以为Pandas/Dask DataFrame生成报告。from dataprep.datasets import load_dataset from dataprep.eda import create_report
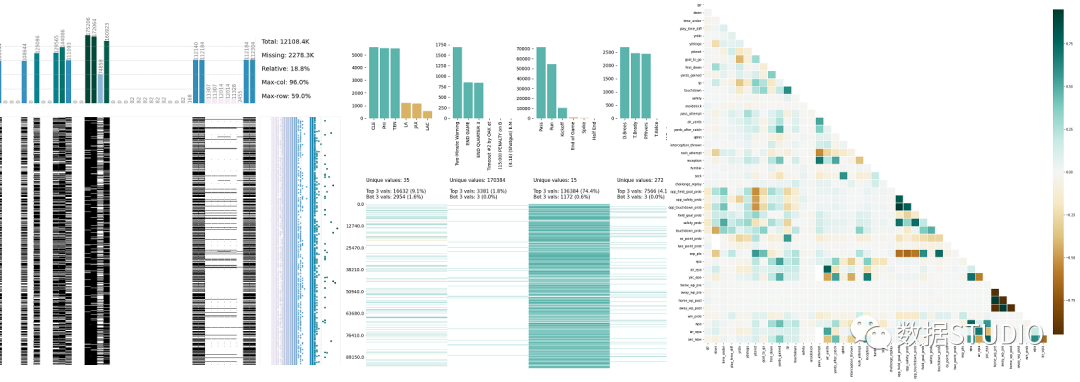
DataTile(以前称为Pandas-Summary)是一个开源的Python软件包,负责管理,汇总和可视化数据。DataTile基本上是PANDAS DataFrame describe()函数的扩展。import pandas as pd
from datatile.summary.df import DataFrameSummary