
笔者将分三篇推送该系列实践指南。本篇主要介绍系列指南的结构与第一部分简介。
在适用范围方面,本指南专注于AI系统开发阶段,特别是涉及个人数据的处理。这些指南不仅适用于公共部门,也适用于私营企业,无论其规模大小。此外,本指南的目标受众广泛,包括法律专业人士、技术专家和业务决策者。法律专业人士需要理解AI领域的数据保护法规,以便为客户提供合规建议;技术专家在开发AI系统时需要遵循数据保护的最佳实践;而业务决策者则需要了解数据保护的基本原则,以确保其业务战略和操作符合法律要求。
本指南的内容结构严谨,旨在提供一套全面的框架,帮助组织评估和提高其AI项目的数据保护合规性。本指南首先介绍了数据保护原则,如数据最小化、目的限制、透明度等,这些都是GDPR的核心原则,并解释了它们在AI背景下的应用。接着,指南提供了如何进行数据保护影响评估(DPIA)的指导,包括风险识别、评估和缓解措施的制定。此外,指南还提供了检查表、模板和工具,以帮助组织评估其AI项目的数据保护合规性。
为了确保本指南的有效实施与应用,组织需要建立持续的监控机制,以确保AI系统在整个生命周期中的合规性。这包括定期审查数据处理活动,确保它们符合最新的法规要求和技术标准。本指南还鼓励组织通过具体的案例研究和实例,展示如何在不同情境下应用数据保护原则和本指南。此外,组织应为其员工提供关于数据保护的培训和教育,以提高对AI系统合规性的认识和能力。
最后,本指南的更新与维护是一个持续的过程。技术发展的影响意味着本指南需要定期更新,以反映最新的技术趋势和法律变化。此外,本指南的制定和更新需要与国际标准和最佳实践保持一致,以促进全球范围内的数据保护合作与协调。
目的与范围:介绍实践指南旨在为AI系统开发阶段提供指导,特别是涉及个人数据的情况。
适用性:指南适用于受GDPR约束的数据处理,旨在帮助不同背景的专业人士理解和遵守数据保护规定。
指南内容:概述了实践指南将涵盖的主题,包括数据保护影响评估(DPIA)、合法性基础、数据收集和管理等。
2. 资料夹1.IA : Déterminer le régime juridique applicable
法律框架:解释了AI系统开发和部署阶段涉及的数据处理应遵守的数据保护法规。
不同情境:
情境1:如果AI系统的操作用途在开发阶段已定义,且开发和部署阶段的目的相同,则两个阶段适用相同的法律制度。
情境2:如果AI系统的操作用途在开发阶段未明确,则通常认为开发阶段受GDPR约束。
特殊情况:讨论了“警察-司法”领域和国家安全相关的数据处理可能适用的特殊法律制度。
3. 资料夹2 IA : Définir une finalité
目的的重要性:强调了根据GDPR,数据处理必须有明确、合法的目的。
定义目的的方法:
操作用途:如果AI系统的操作用途在开发阶段已明确,则开发阶段的目的应与部署阶段的目的一致。
一般用途AI系统:对于未明确操作用途的AI系统,开发阶段的目的应足够明确,提及系统类型和技术能力。
科学研究的目的:讨论了科学研究情况下目的定义的特殊性,以及可能的法律减免。
4. 资料夹3 Déterminer la qualification juridique des acteurs
角色定义:解释了根据GDPR,涉及数据处理的不同角色(负责人、共同负责人、分包商)的法律定义。
确定责任:
数据控制者:分析了决定数据处理目的和手段的个体或组织,可能是数据处理负责人。
共同数据控制者:讨论了当多个数据控制者共同决定处理目的和手段时,他们可能被视为共同负责人。
数据处理者:描述了为数据控制者处理数据的个体或组织,以及数据控制者确保数据处理者遵守GDPR的义务。
实践指导:提供了如何根据具体情况分析各方的角色和责任的指导,包括例子和案例分析。
5. 资料夹4 IA : Assurer que le traitement est licite – Défini
合法性基础:阐述了在使用个人数据构建AI训练数据集时,必须确保数据处理是合法的。
合法性基础选择:
同意:讨论了当处理基于数据主体的明确同意时,需要满足的四个条件:自由、具体、知情和明确。
合法利益:解释了在追求处理者合法利益时,如何确保数据处理的合法性,包括平衡数据主体的权利和利益。
公共利益:描述了在公共利益或执行公共任务的背景下,数据处理可能的合法性基础。
敏感数据的处理:特别强调了处理敏感数据(如种族、生物特征等)时的额外限制和要求。
6. 资料夹5 IA : Réaliser une analyse d’impact si nécessaire
影响评估的必要性:说明了在某些情况下,进行数据保护影响评估(DPIA)是法律要求的步骤。
评估过程:
风险识别:识别可能对个人权利和自由构成风险的数据处理活动。
风险评估:评估这些风险的可能性和严重性,并制定相应的缓解措施。
后续行动:根据DPIA结果,设计并实施行动计划以降低风险到可接受水平。
DPIA的迭代:强调了DPIA是一个持续的过程,需要根据数据处理活动的变化进行更新和调整。
7. 资料夹6 IA : Tenir compte de la protection des données dans la conception du système
设计阶段的数据保护:强调了在AI系统设计阶段考虑数据保护的重要性。
设计阶段的关键考虑因素:
系统目标:明确AI系统的目标,确保数据处理与目标相符。
数据处理方法:选择合适的技术方法,最小化对个人数据的依赖。
数据选择:只选择实现系统目标所必需的数据,遵循数据最小化原则。
设计与评估验证:推荐通过试点研究或伦理委员会审查等方式验证设计选择的有效性。
8.资料夹7 IA : Tenir compte de la protection des données dans la collecte et la gestion des données
数据收集与管理中的数据保护:讨论了在收集和管理AI训练数据时,如何确保遵守数据保护原则。
数据收集的合规性:
收集方法:介绍了不同的数据收集方法,包括网络抓取,并强调了收集过程中的隐私保护措施。
数据清洗与选择:讨论了数据清洗过程中的隐私保护措施,以及如何选择与任务相关的数据。
数据隐私保护:强调了在设计阶段就考虑隐私保护措施的重要性,如差分隐私和联邦学习。
数据保护措施的持续与更新:指出随着时间的推移,可能需要更新数据保护措施以反映数据收集和管理实践的变化。
实践指南涉及的活动是在构建训练数据集及其在人工智能系统开发中使用时,这些数据库全部或部分包含个人数据,可分为如下三种可能的情况:
1.无个人数据:如果数据库中确定没有个人数据存在,则不适用这些指南(尽管一些良好实践的建议可能是相关的)。
2. 有个人数据:如果数据库中确定存在个人数据,则适用这些指南。这包括从包含人物视频或图片、声音记录、结构化个人数据等开发出的人工智能系统。需要注意的是,如果个人数据和非个人数据在数据集中不可分割地混合在一起,则所谓的“混合”数据集受GDPR的管辖。
3. 可能存在个人数据:这是一个常见的情况,其中并没有明确希望收集个人数据。例如:图像中残留的人物或车牌;文本数据中的姓名、名字、地址等出现,如评论或提示等。
如果在后续的处理操作中去除了原始个人数据并进行了匿名化,那么这些数据将失去其个人性质,不再适用这些指南。可以通过手动检查(例如在数据注释时)或自动检查(例如使用图像中的人/脸检测技术,命名实体识别(NER)方法等)来确认个人数据的存在。
(二)实践指南适用于处理个人数据的人工智能系统
本指南采取的人工智能系统定义与欧盟《人工智能法》一样的定义。
在实践中,所涉及的AI系统包括基于自动学习(监督学习、非监督学习和强化学习)的系统,以及基于逻辑和知识(知识库、推理和演绎引擎、符号推理、专家系统等)的系统,以及混合方法的系统。
实践指南涵盖这些系统,无论其在开发阶段的操作使用是否已定义,或者是否为通用目的AI系统(“general purpose AI”),例如实施“基础模型”,因为它们能够被重复使用和适应于不同的应用和使用案例。
这些指南也涉及所有如上所述的AI系统,无论学习是“一次性”完成的还是在部署阶段持续进行的。对于持续学习系统的情况,当系统部署时收集的数据被用于系统迭代改进。
最后,它们涉及对现有AI模型进行训练或调整(微调/迁移学习)的处理,无论它们是否集成到一个独立的系统中,只要它们涉及个人数据。
(三)实践指南适用于人工智能系统的开发阶段
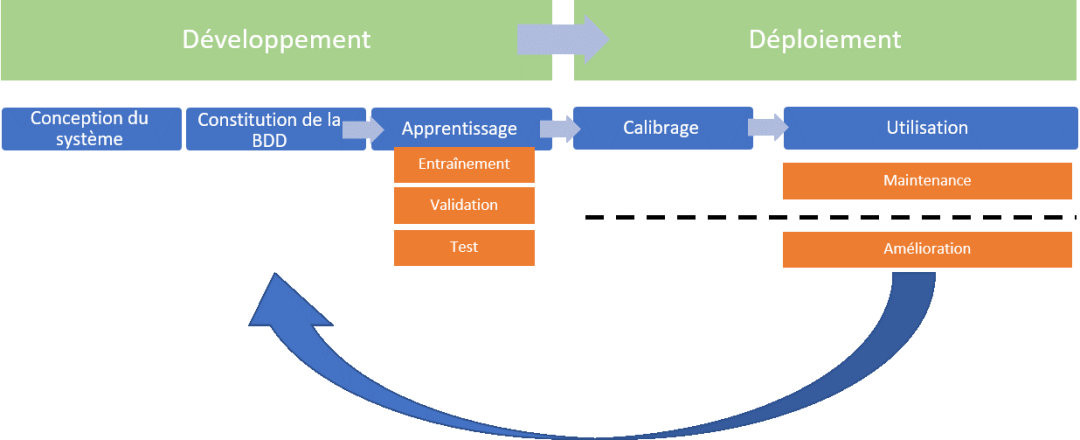
如前图所示,建立一个依赖于自动学习的人工智能系统通常需要连续经历两个不同的阶段:
1. 开发阶段:包括设计、开发和训练一个人工智能系统。
2. 部署阶段:包括将第一阶段开发的人工智能系统投入使用。
开发阶段包括人工智能系统开发直至部署(生产阶段)的所有步骤,即:
(1)系统设计:选择算法架构,包括学习的方法和可能预先训练的模型选择,识别所需数据和初步测试、试点;
(2)数据库构建:数据收集和预处理(清洗、注释、特征提取、数据分配);
(3)学习:模型训练、可能的调整或微调、超参数调整和性能测试;
(4)有时还包括集成:当开发结束时预期的最终产品是一个系统而不是模型时,将训练好的模型嵌入信息系统、连接到其他软件组件、开发用户界面、编写用户文档等。
在许多情况下,人工智能系统的开发将依赖于预训练模型的调整(“微调”)或通过迁移学习(“迁移学习”)。CNIL认为这一阶段构成了与原始模型构建阶段不同的第二阶段开发。
在持续学习的情况下,数据在模型部署和生产期间被收集,以便于未来的改进。因此,持续
训练通过反馈循环包含在这一开发阶段中。
需要注意的是,除了这两个阶段,还有一个人工智能系统停止或删除其所包含的个人数据的阶段。当前的指南没有详细说明在这一阶段需要进行的操作,这些操作也属于个人数据保护法规的范畴。
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/90446.html
