
探索性数据分析是数据科学模型开发和数据集研究的重要组成部分之一。在拿到一个新数据集时首先就需要花费大量时间进行EDA来研究数据集中内在的信息。自动化的EDA Python包可以用几行Python代码执行EDA。
在本文中整理了10个可以自动执行EDA并生成有关数据的见解的Python包,看看他们都有什么功能,能在多大程度上帮我们自动化解决EDA的需求。
-
DTale -
Pandas-profiling -
sweetviz -
autoviz -
dataprep -
KLib -
dabl -
speedML -
datatile -
edaviz
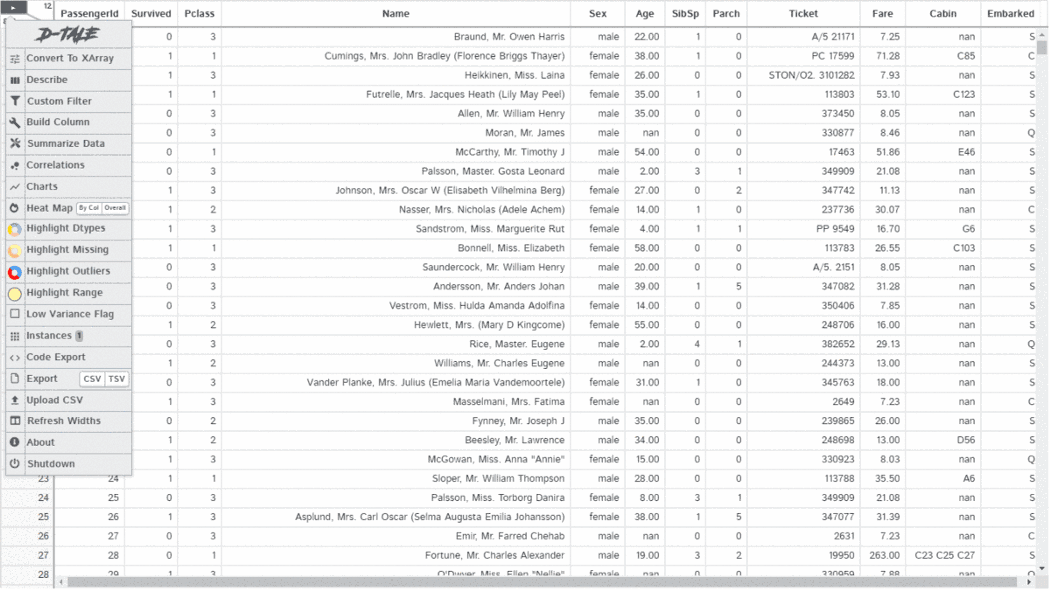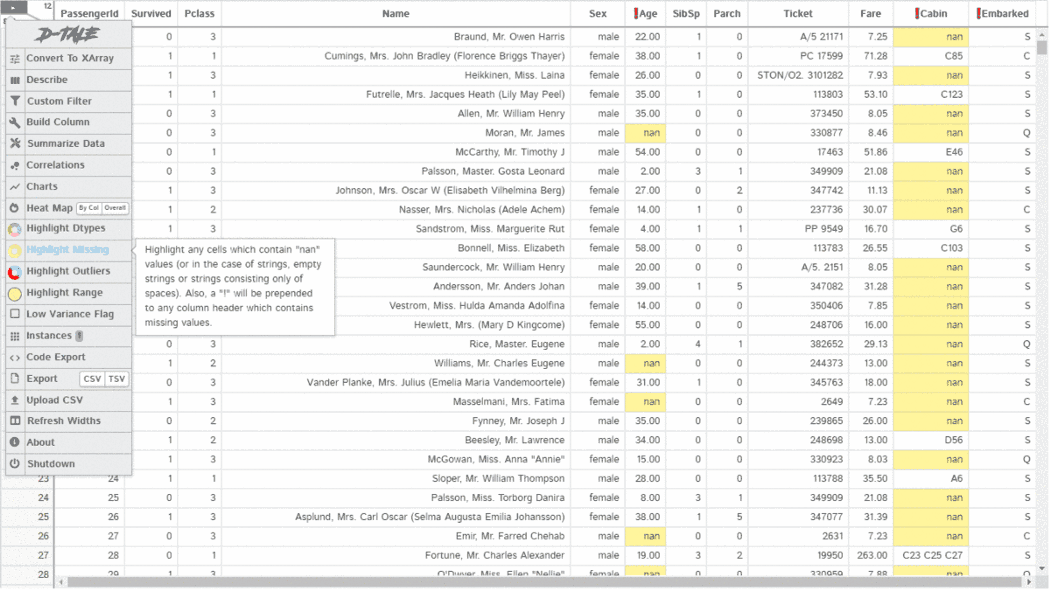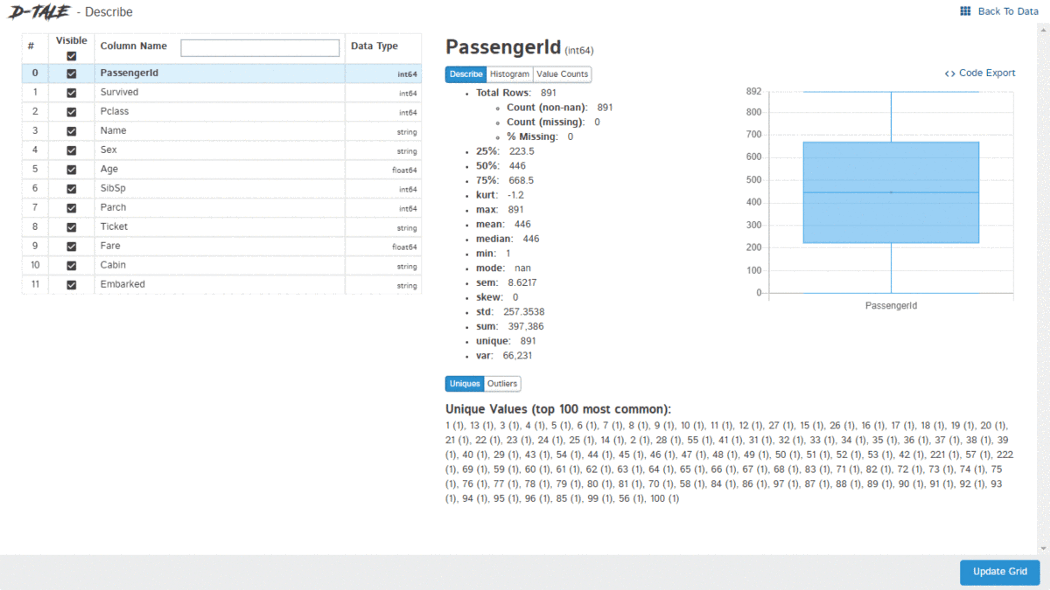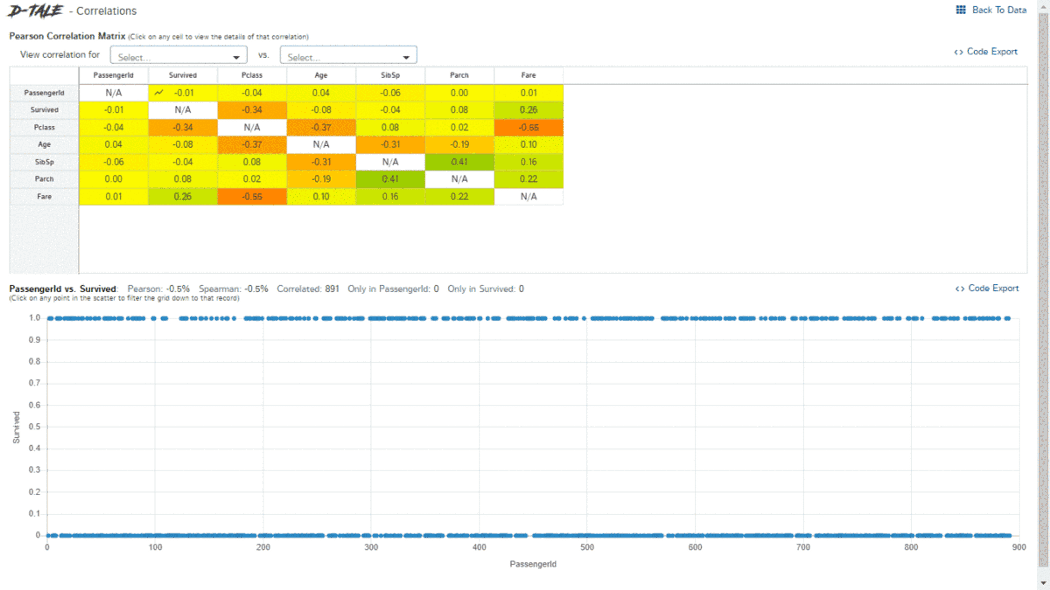
1、D-Tale
import pandas as pd
dtale.show(pd.read_csv(“titanic.csv”))
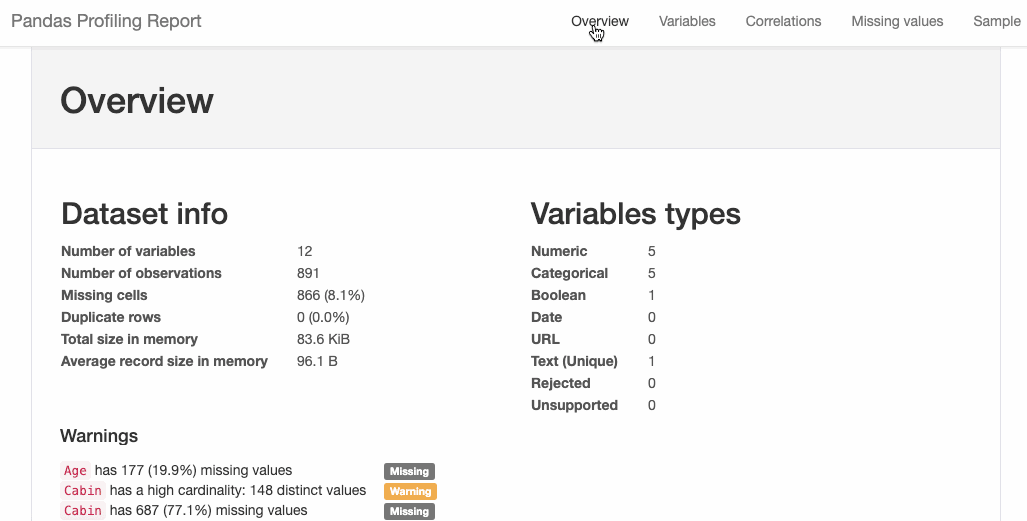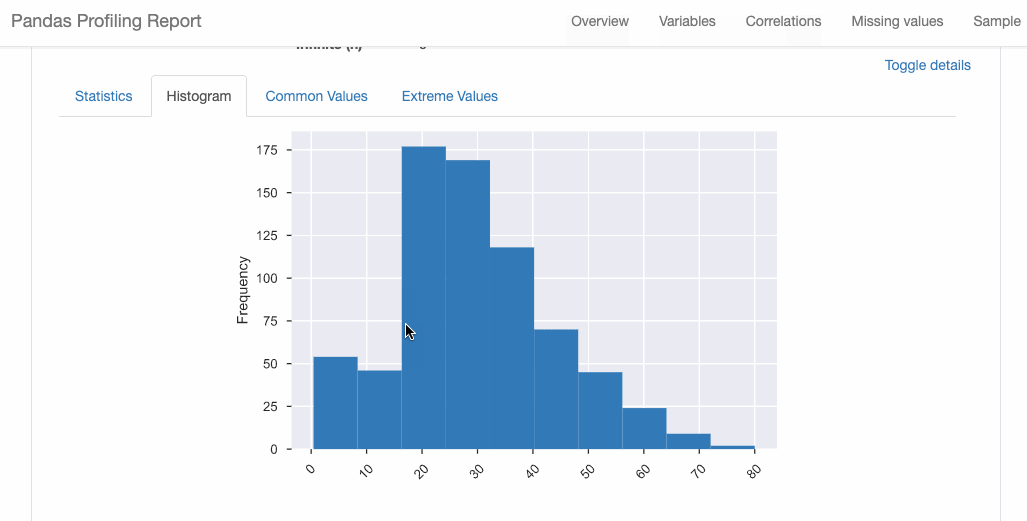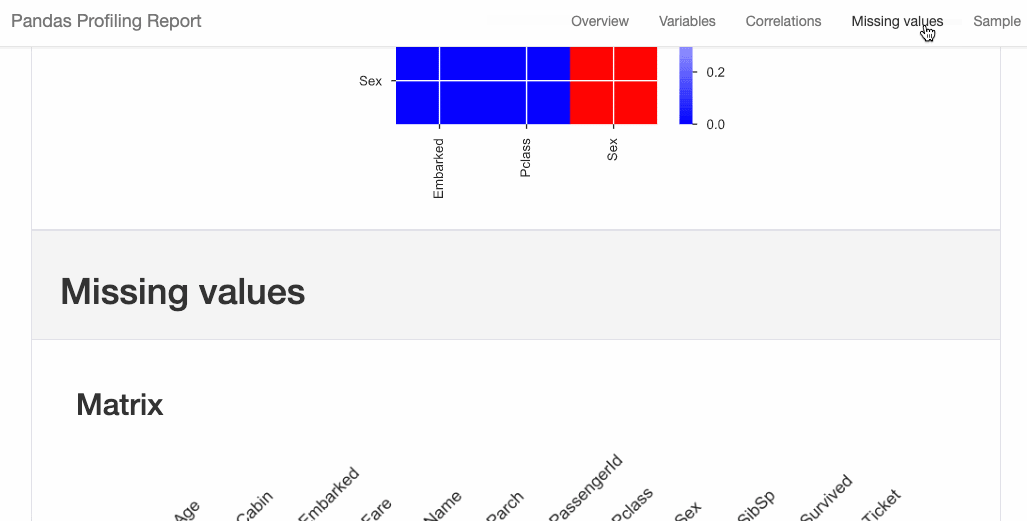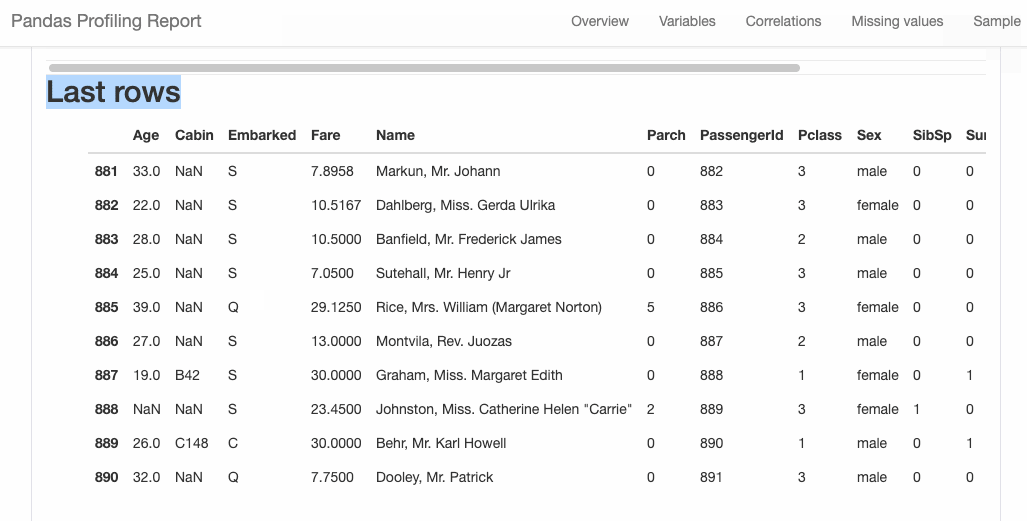
import pandas as pd
from pandas_profiling import ProfileReport
#EDA using pandas-profiling
profile = ProfileReport(pd.read_csv(‘titanic.csv’), explorative=True)
#Saving results to a HTML file
profile.to_file(“output.html”)

import sweetviz as sv
#EDA using Autoviz
sweet_report = sv.analyze(pd.read_csv(“titanic.csv”))
#Saving results to HTML file
sweet_report.show_html(‘sweet_report.html’)

from autoviz.AutoViz_Class import AutoViz_Class
#EDA using Autoviz
autoviz = AutoViz_Class().AutoViz(‘train.csv’)
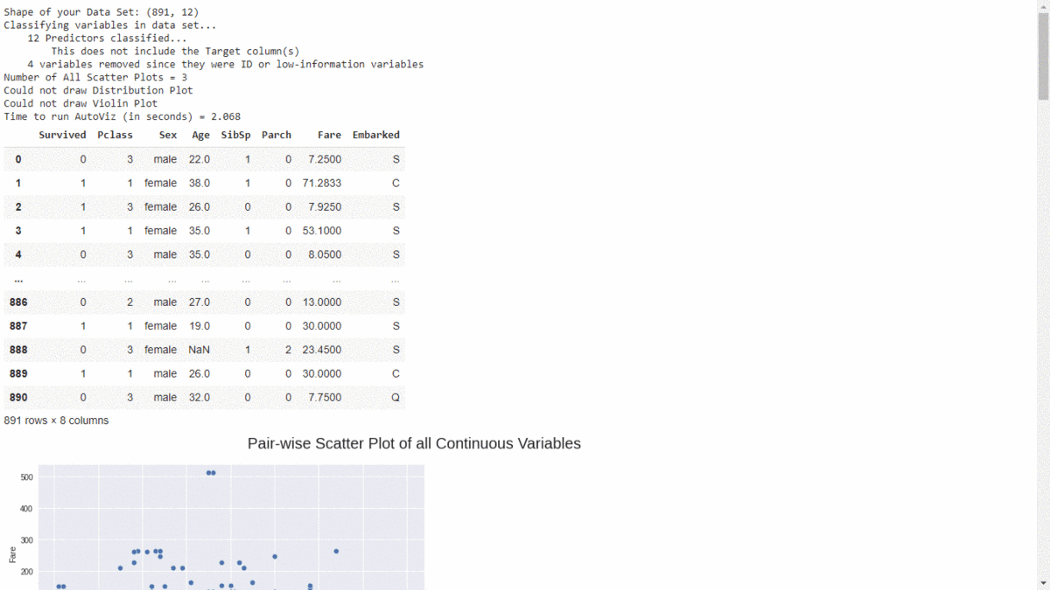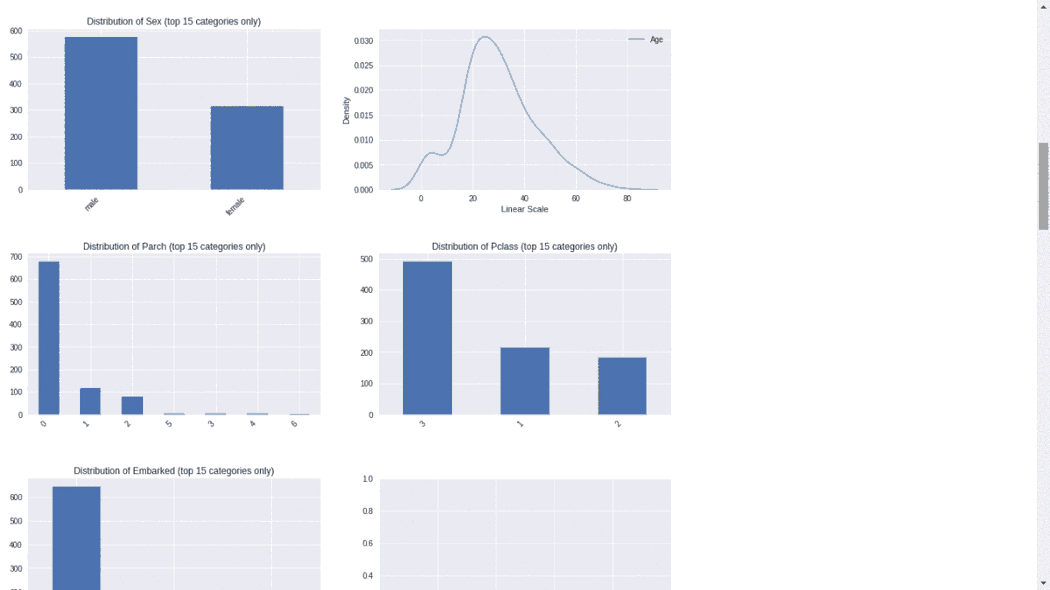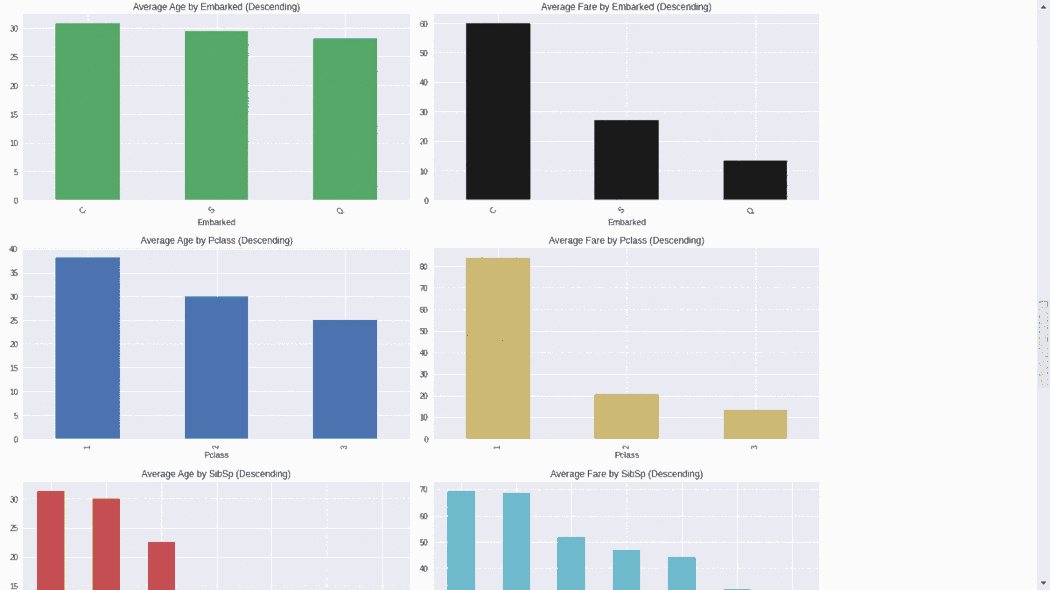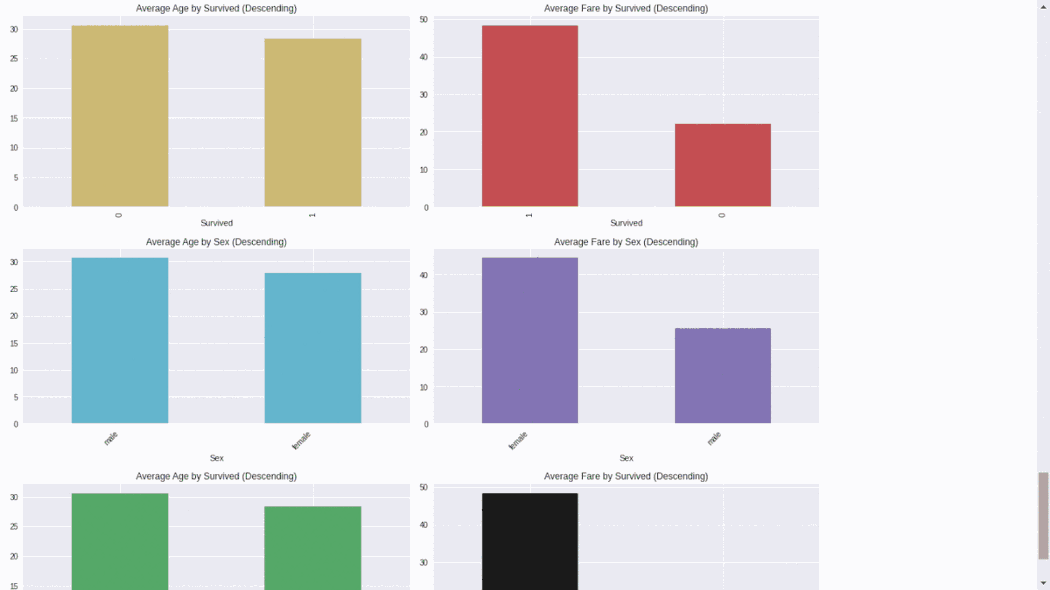

from dataprep.eda import create_report
df = load_dataset(“titanic.csv”)
create_report(df).show_browser()
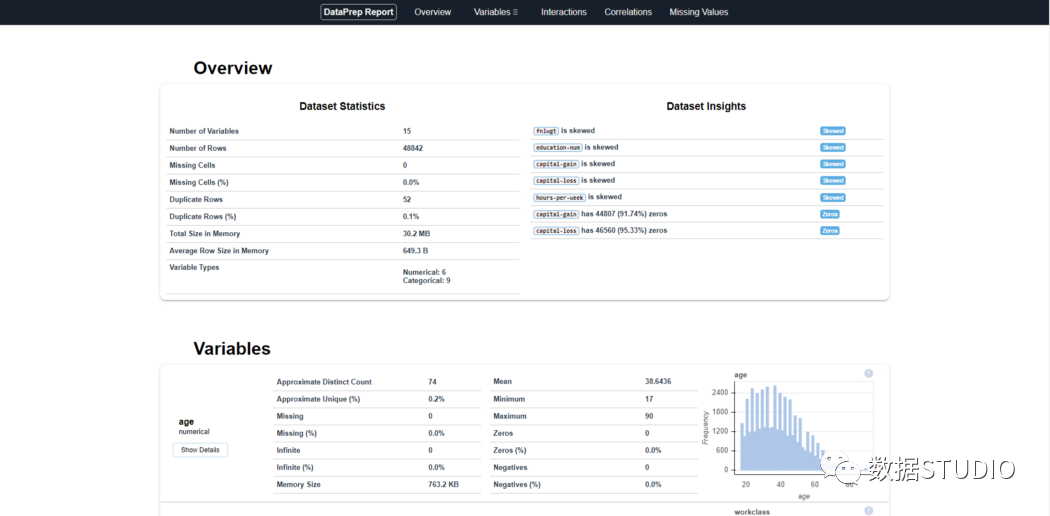
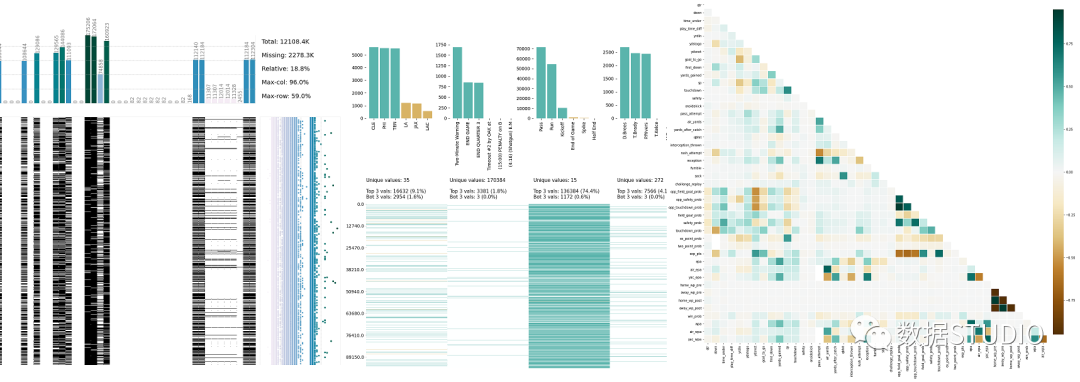
import pandas as pd
df = pd.read_csv(‘DATASET.csv’)
klib.missingval_plot(df)
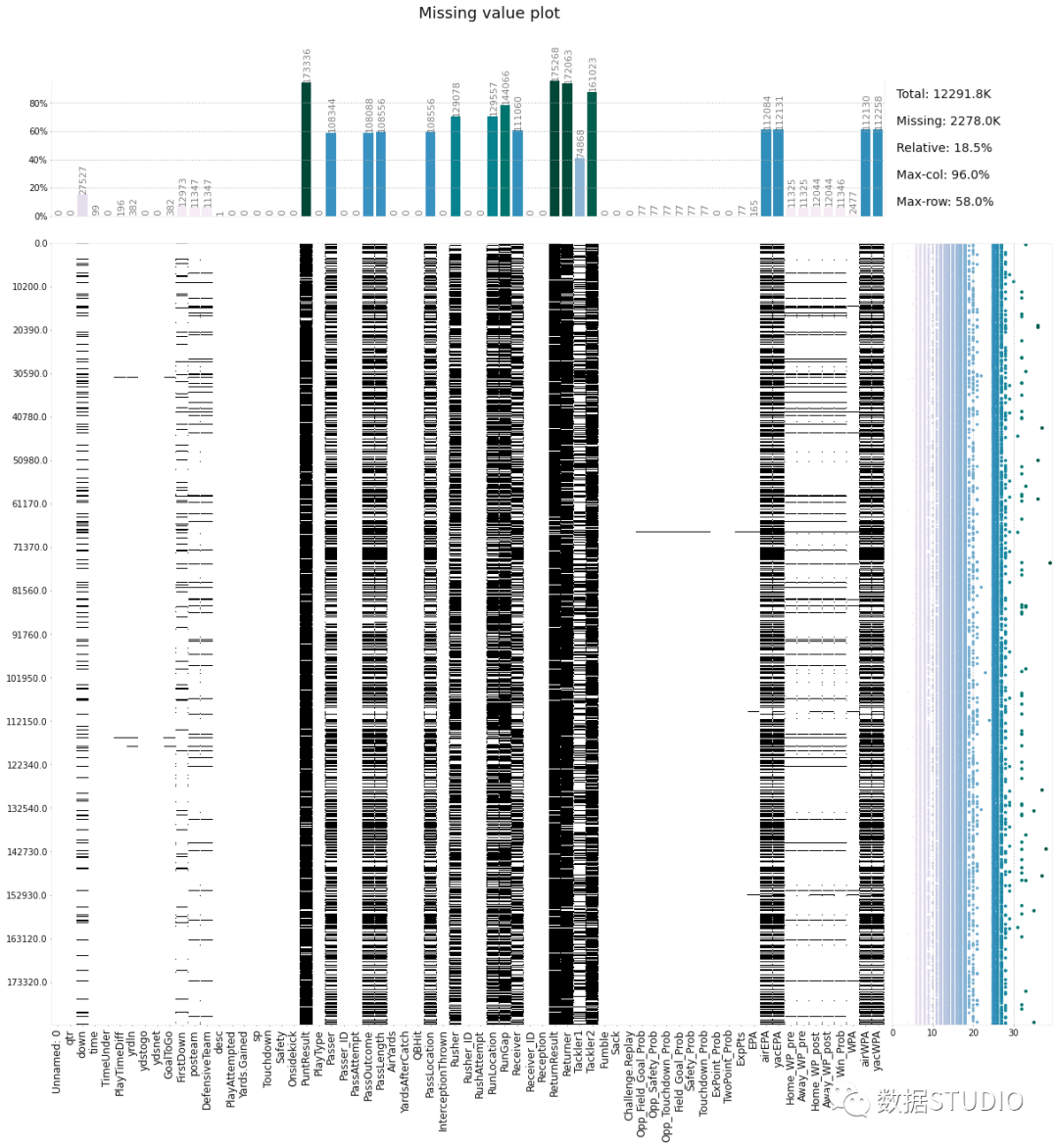
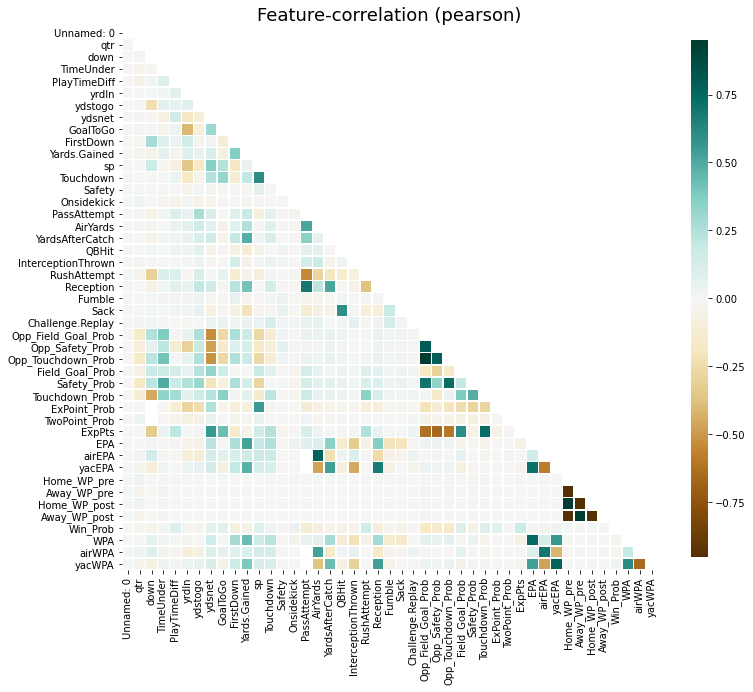

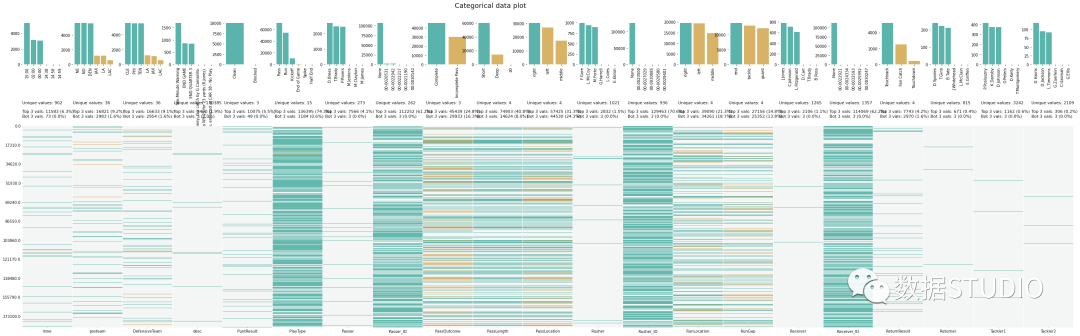
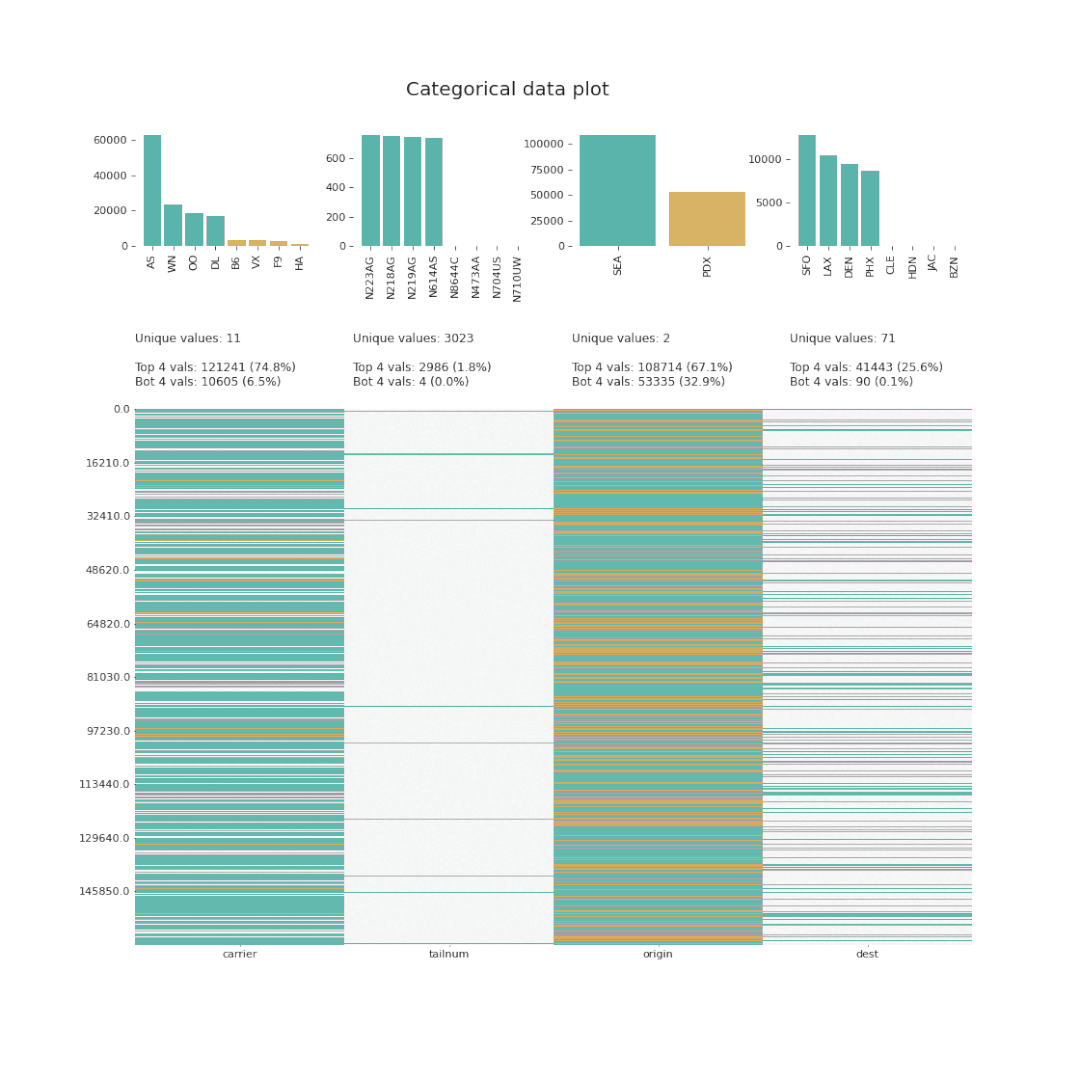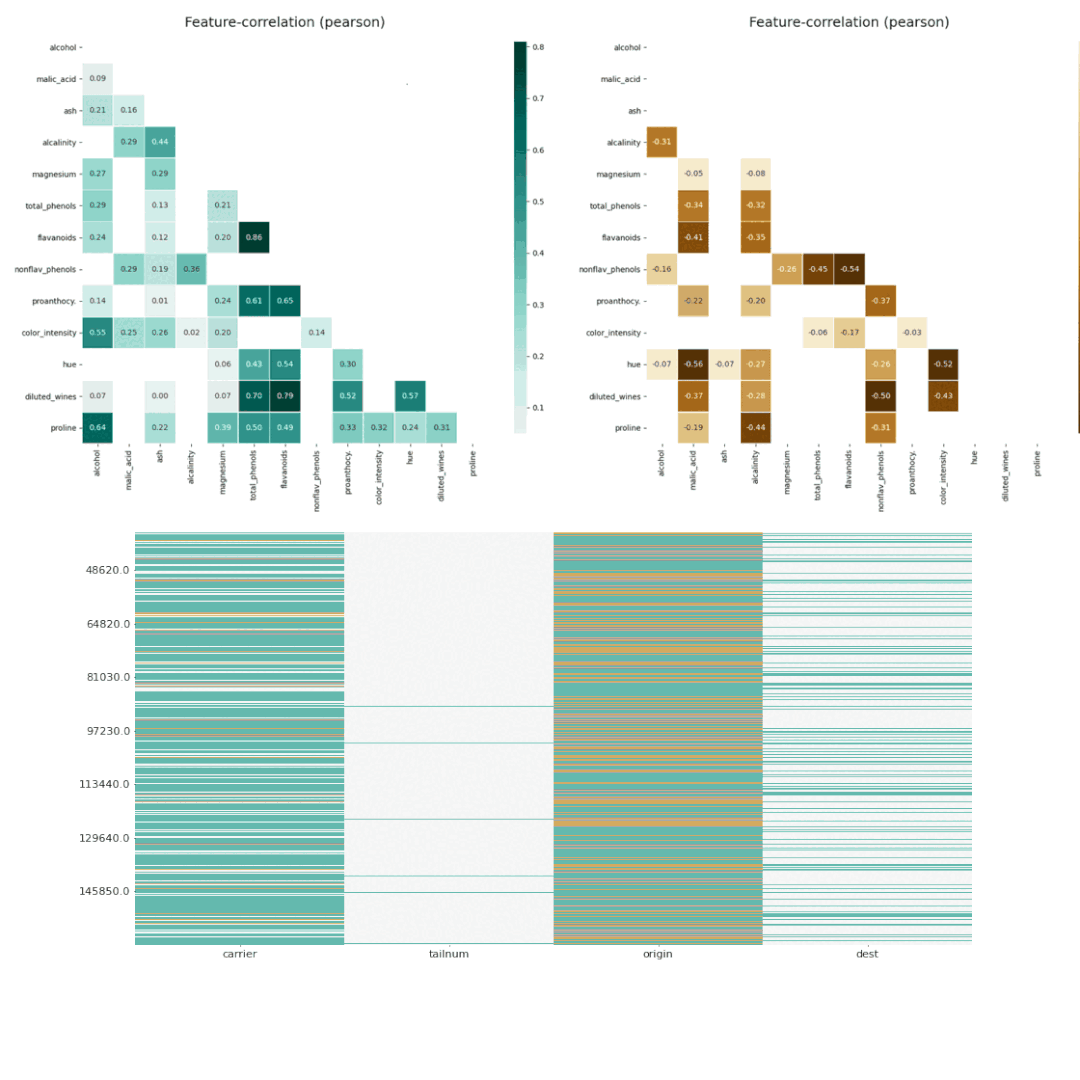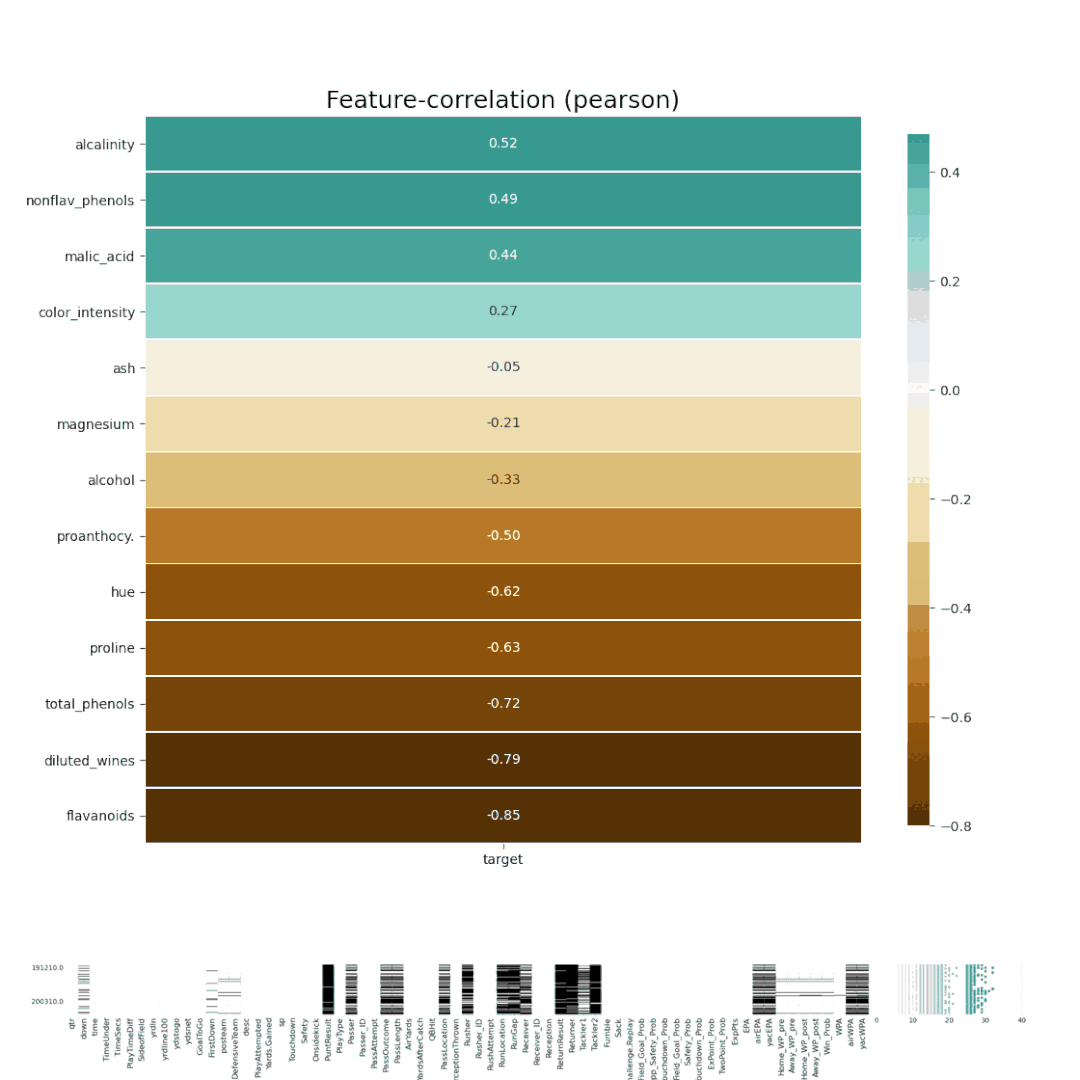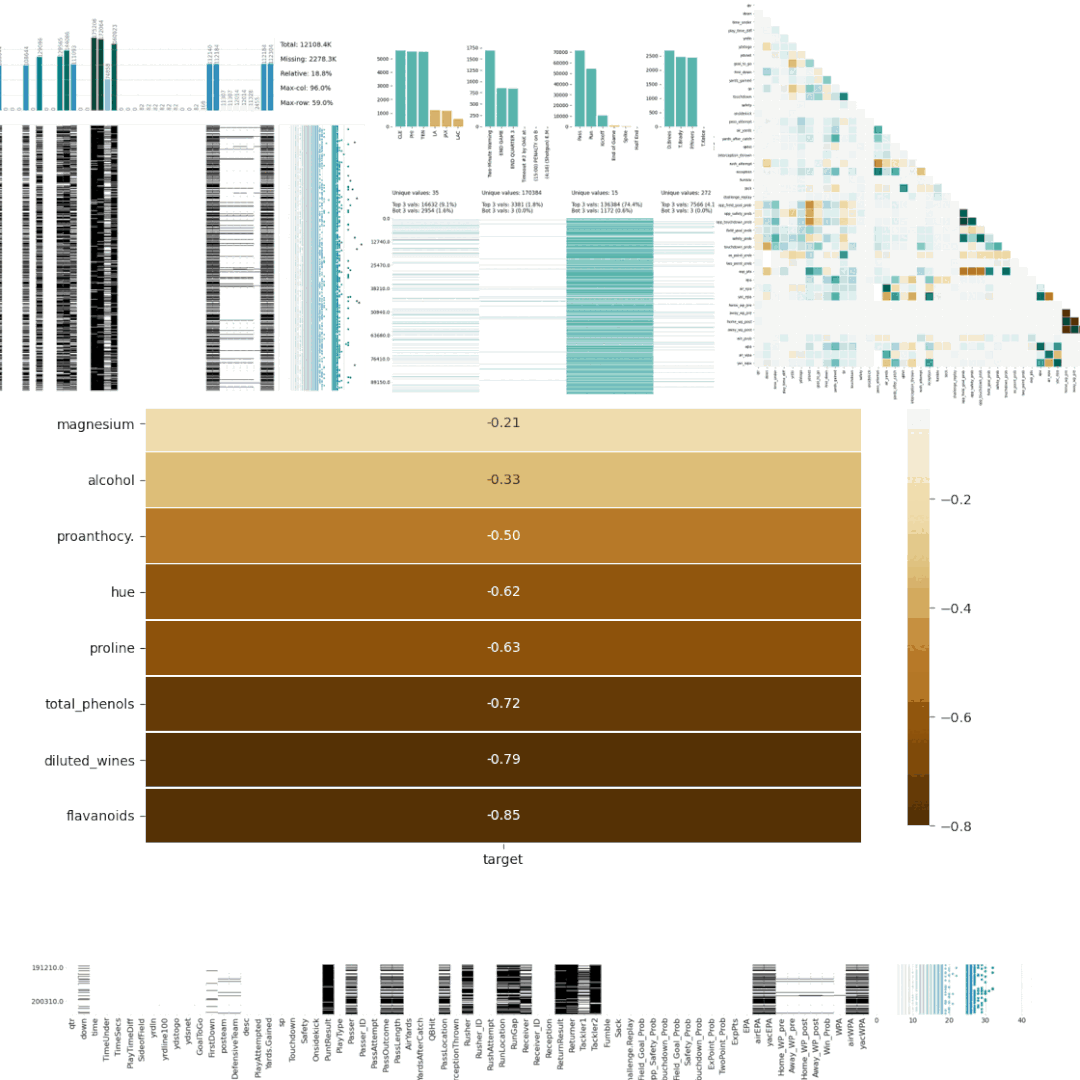
7、Dabl
-
目标分布图 -
散点图 -
线性判别分析
import dabl
df = pd.read_csv(“titanic.csv”)
dabl.plot(df, target_col=”Survived”)
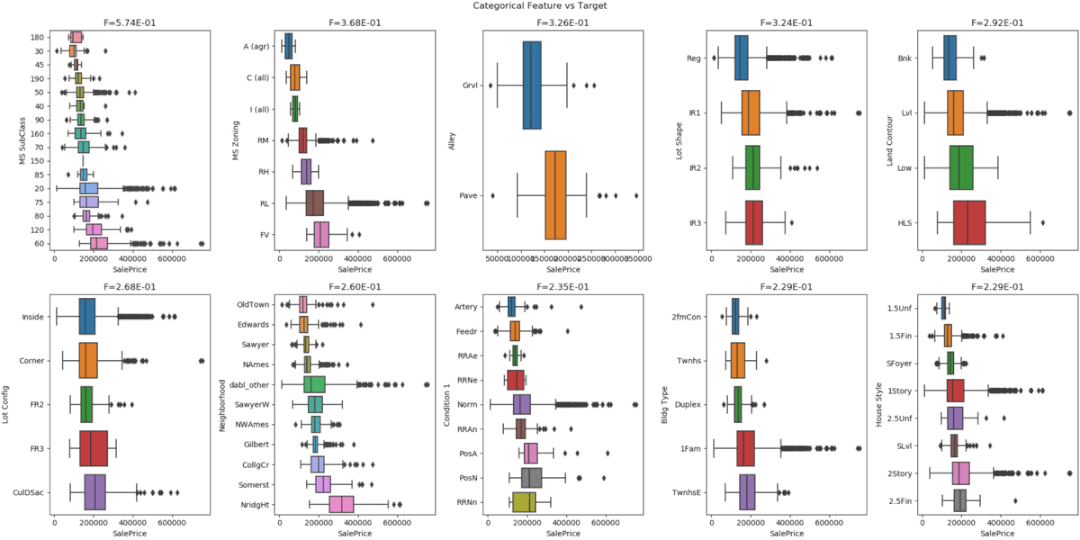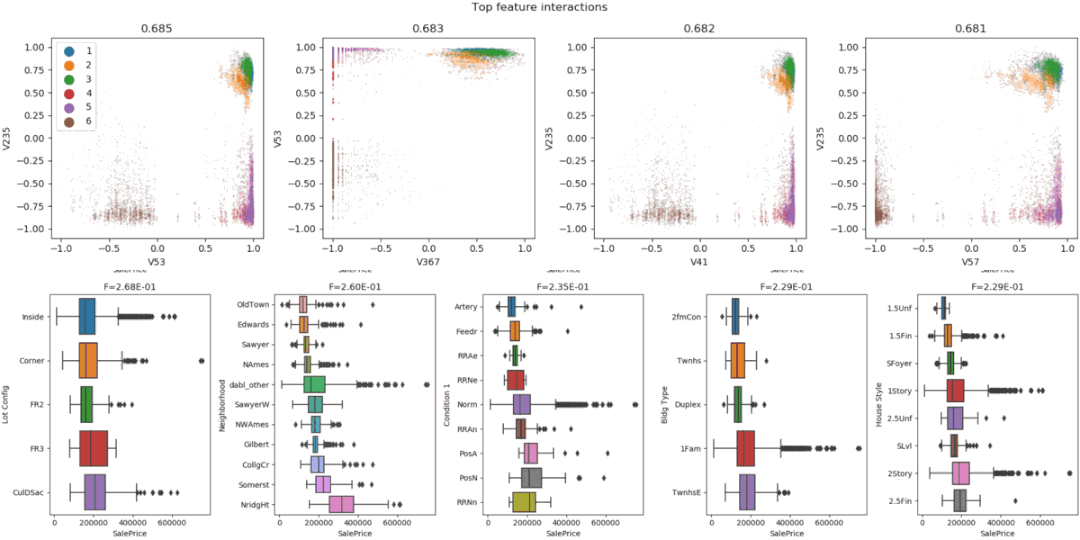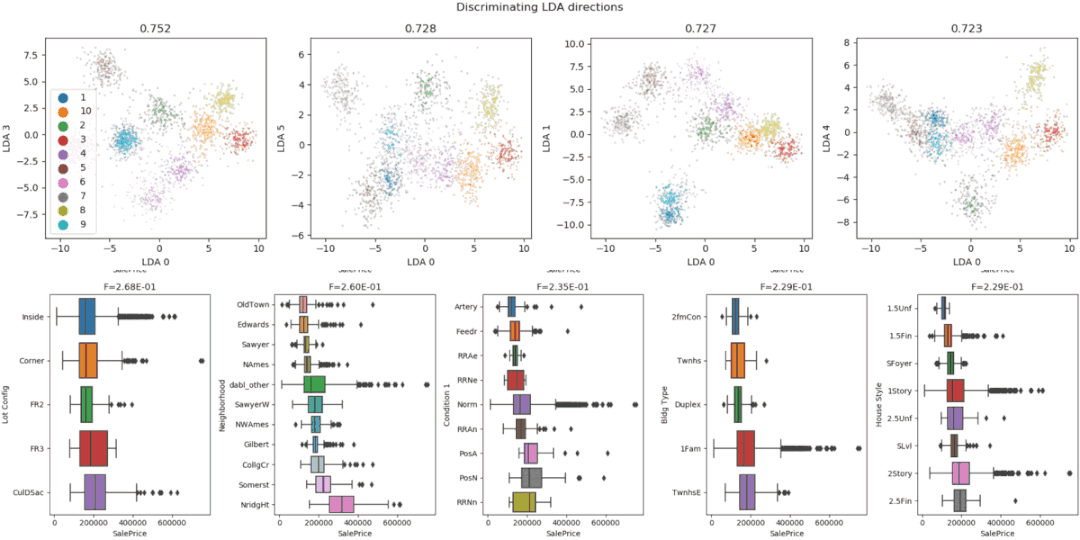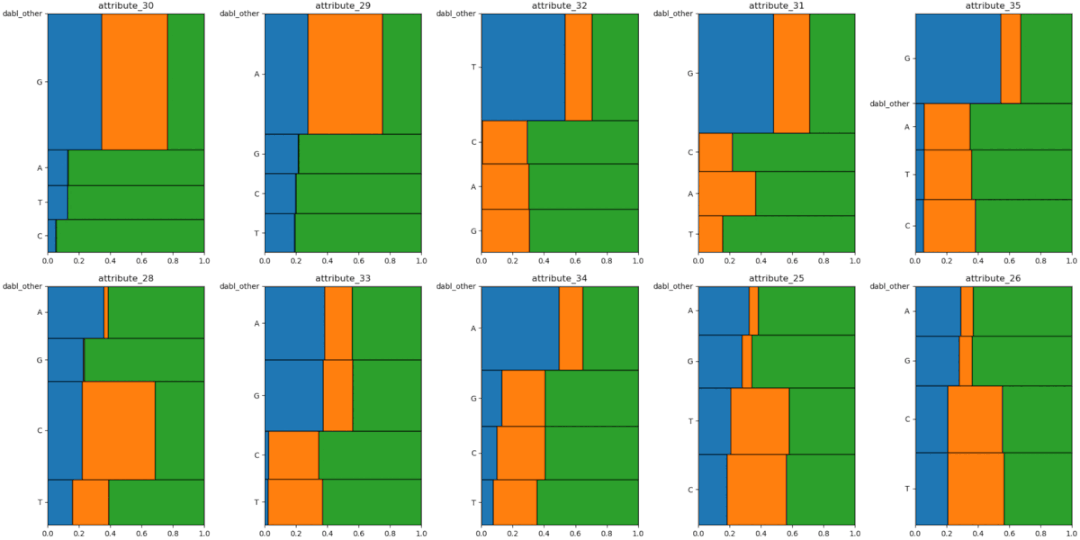
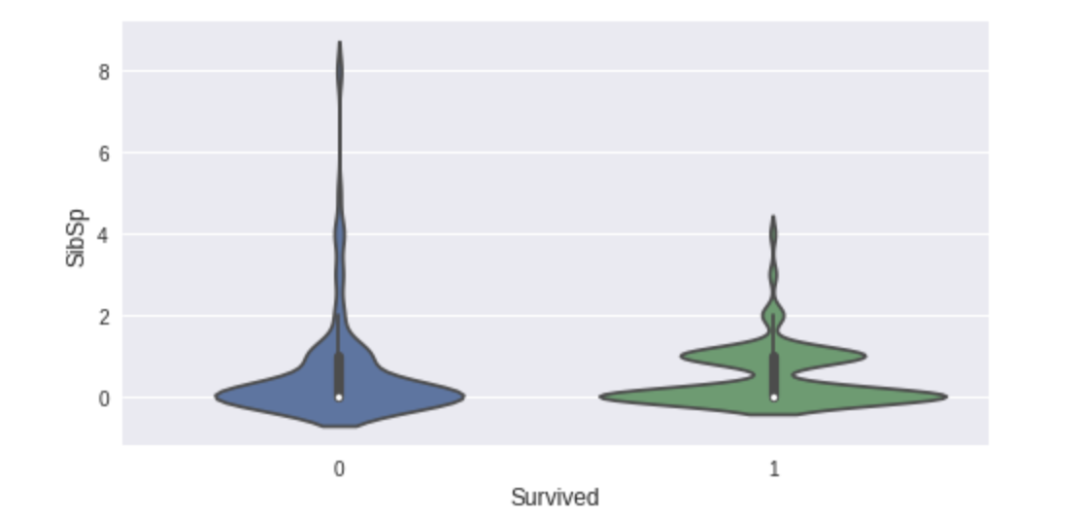
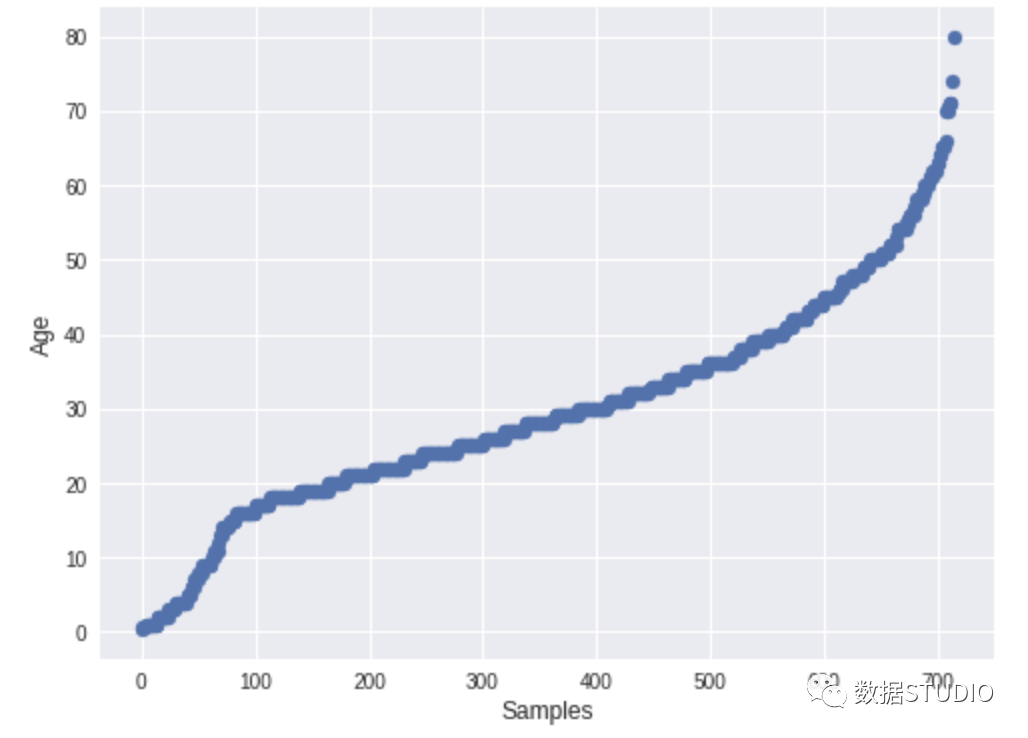
8、Speedml
sml = Speedml(‘../input/train.csv’, ‘../input/test.csv’,
target = ‘Survived’, uid = ‘PassengerId’)
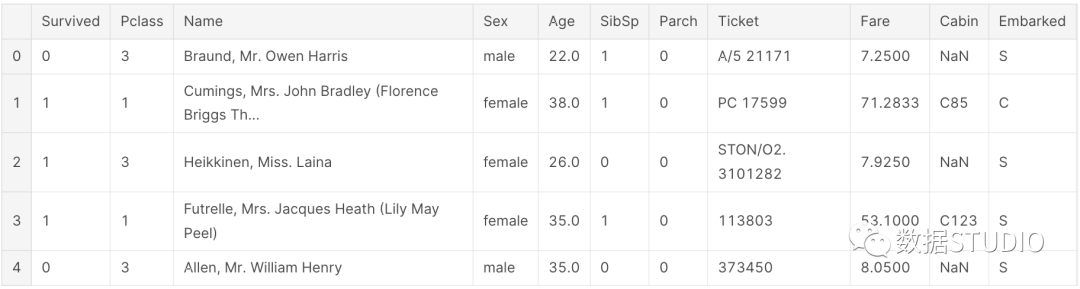
sml.train.head()
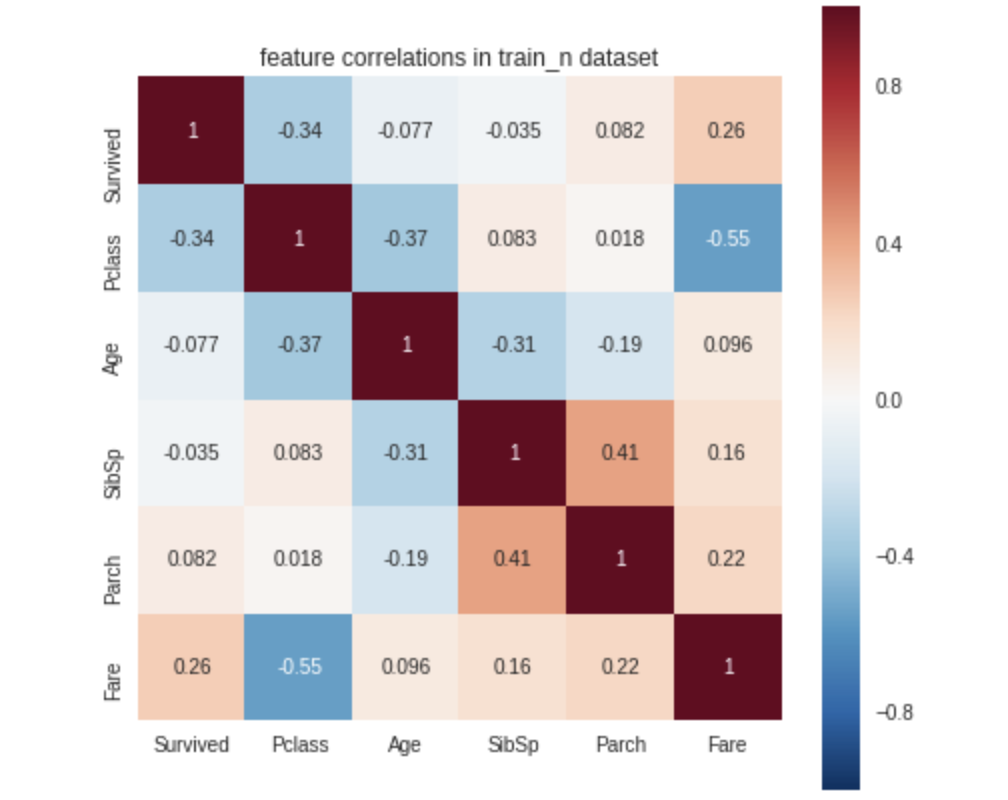
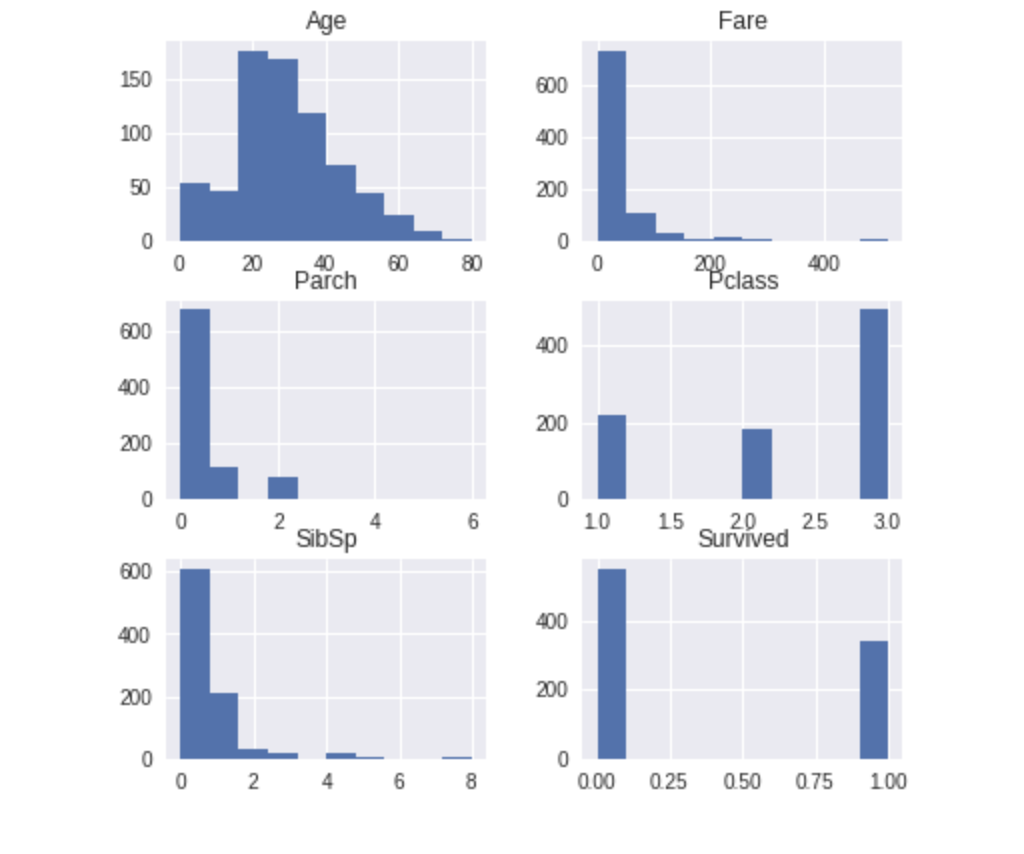
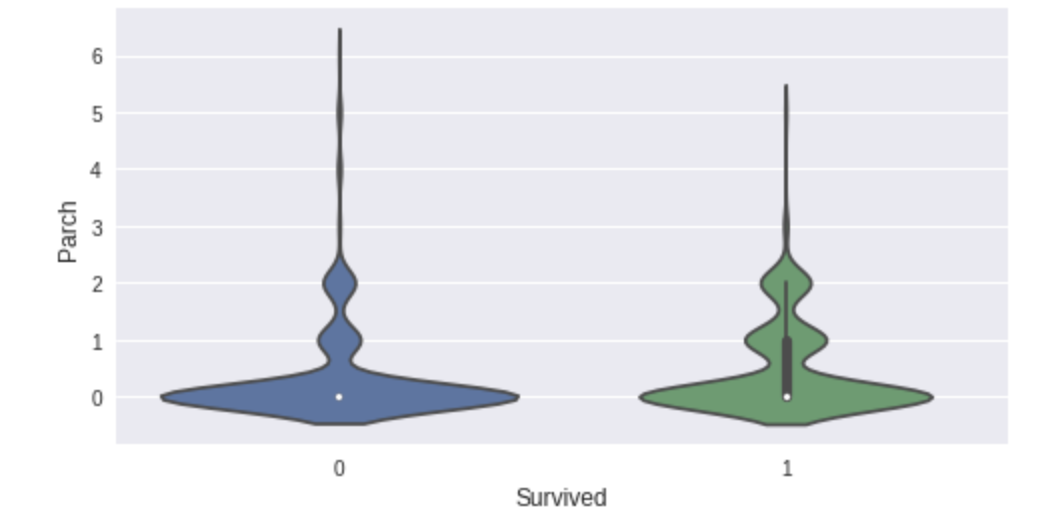
9、DataTile
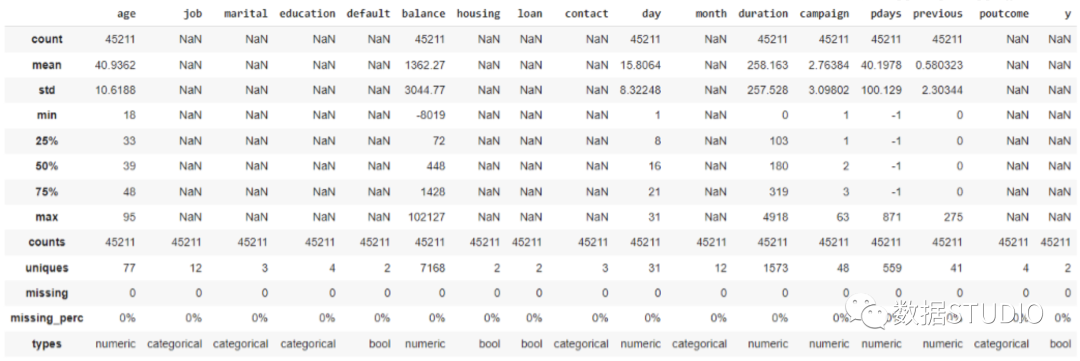
from datatile.summary.df import DataFrameSummary
df = pd.read_csv(‘titanic.csv’)
dfs = DataFrameSummary(df)
dfs.summary()
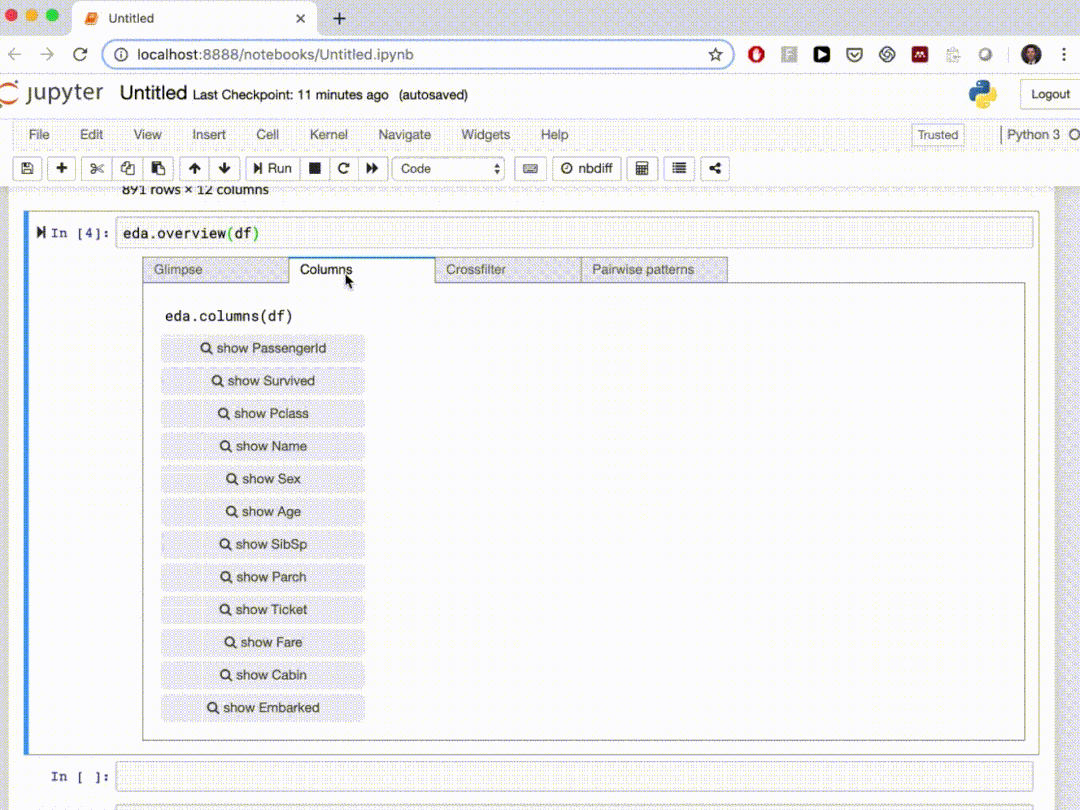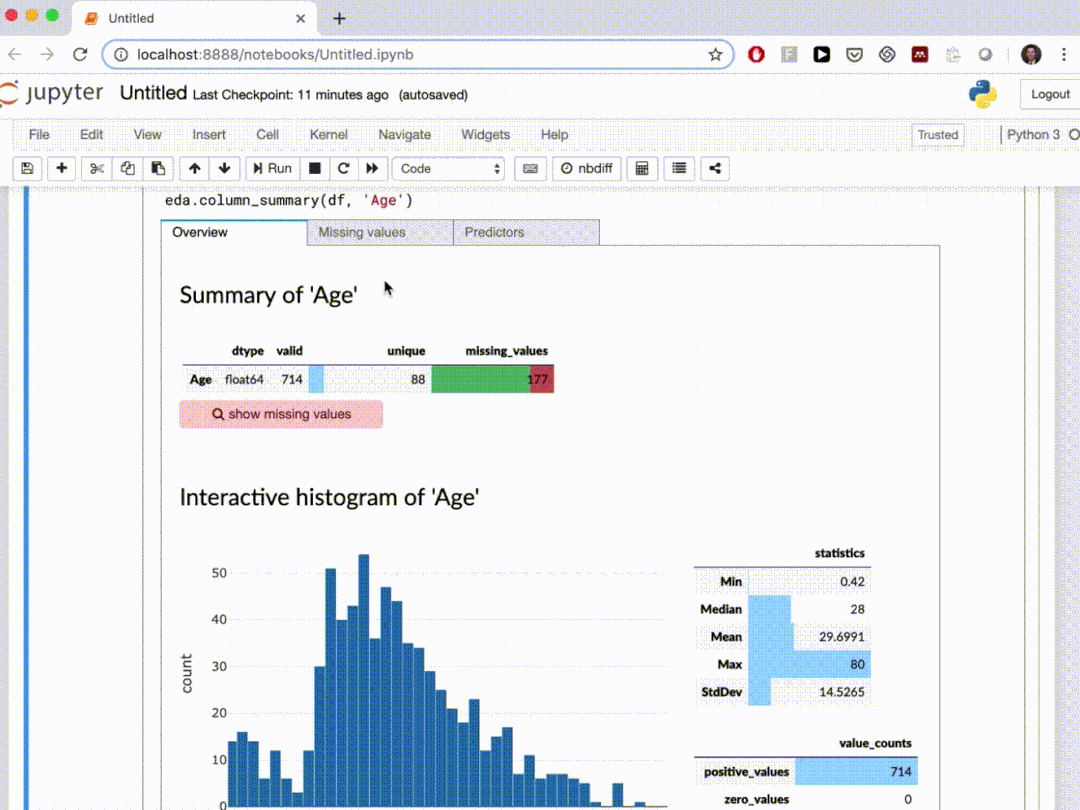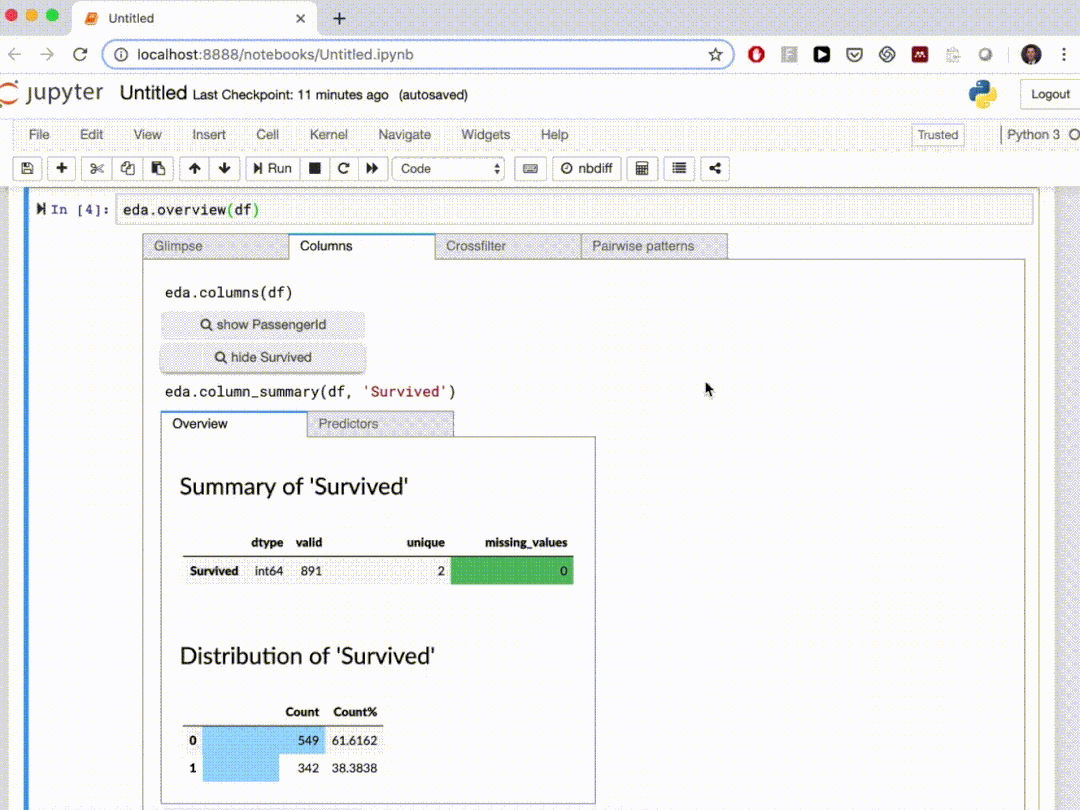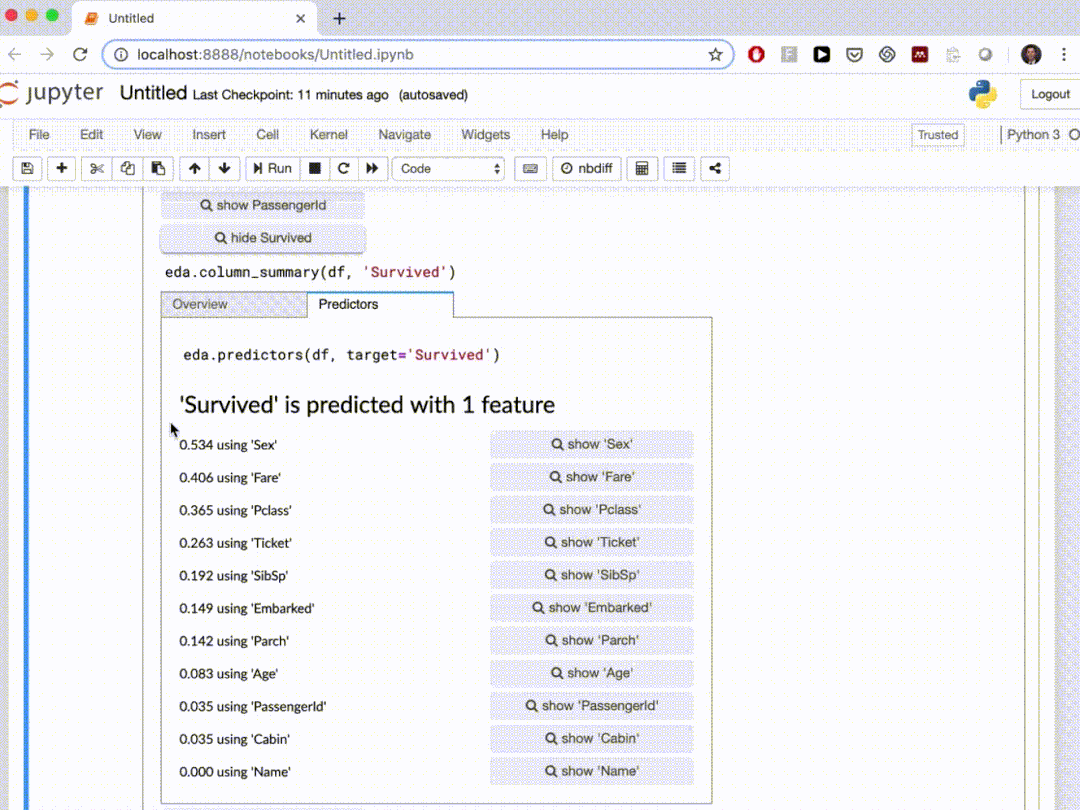
10、edaviz
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/90537.html