
Vanna 是一个开源的 Python RAG(检索增强生成)框架,用于 SQL 生成和其他相关功能。它使用大型语言模型(LLM)来实现准确的文本到 SQL 生成。
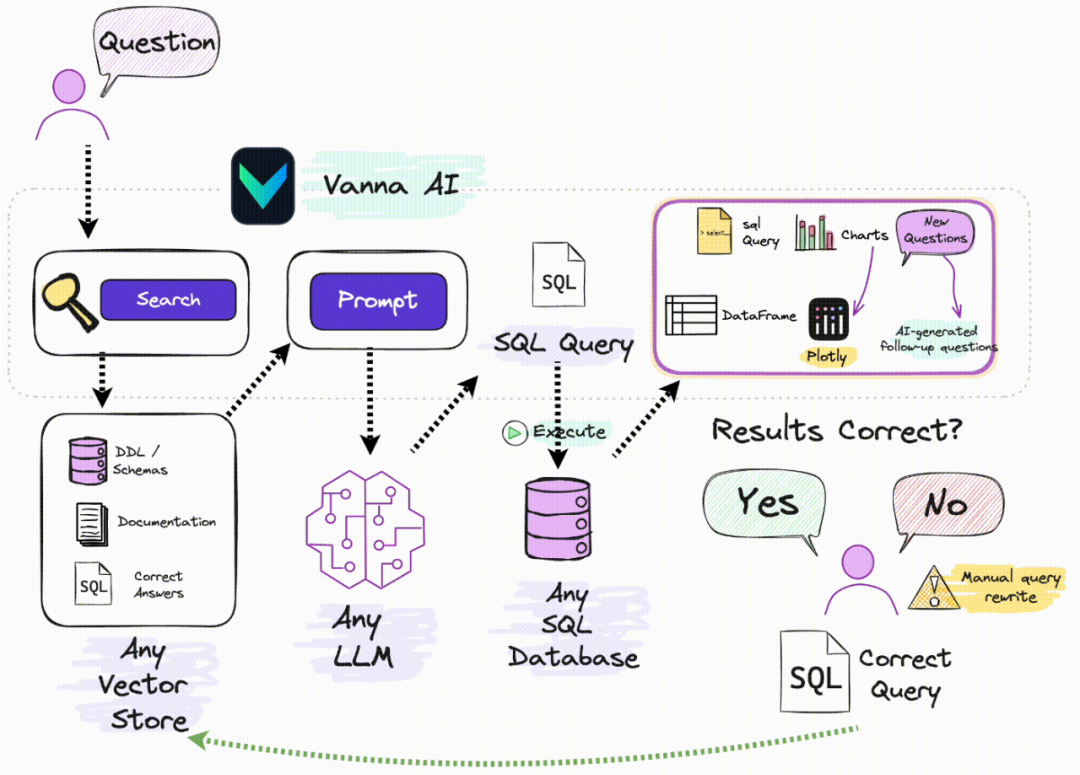
Vanna 的工作原理:
1.在你的数据上训练一个 RAG “模型”。2.提出问题,Vanna 会返回 SQL 查询,这些查询可以被设置为自动运行在你的数据库上。
用户界面:
Vanna 提供了多种用户界面,例如 Jupyter Notebook、Streamlit、Flask 和 Slack,方便你使用。
安装:
pip install vanna使用示例:
from vanna.openai.openai_chat import OpenAI_Chatfrom vanna.chromadb.chromadb_vector import ChromaDB_VectorStoreclass MyVanna(ChromaDB_VectorStore, OpenAI_Chat):def __init__(self, config=None):ChromaDB_VectorStore.__init__(self, config=config)OpenAI_Chat.__init__(self, config=config)vn = MyVanna(config={'api_key': 'sk-...', 'model': 'gpt-4-...'})
训练:
•
使用 DDL 语句进行训练,例如:
vn.train(ddl="""CREATE TABLE IF NOT EXISTS my-table (id INT PRIMARY KEY,name VARCHAR(100),age INT)""")
•
使用文档进行训练,例如:
vn.train(documentation="Our business defines XYZ as ...")•
使用 SQL 查询进行训练,例如:
vn.train(sql="SELECT name, age FROM my-table WHERE name = 'John Doe'")提问:
vn.ask("What are the top 10 customers by sales?")Vanna 的优势:
•高精度:在复杂数据集上表现出色。•安全和私密:你的数据库内容不会被发送到 LLM 或向量数据库。•自学习:可以根据成功执行的查询进行自动训练。•支持任何 SQL 数据库。•可扩展性强:可以轻松扩展到使用自定义的 LLM 或向量数据库。
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/90786.html