
Java线程发展史
- 用户态线程,而非内核线程;
-
由应用层(譬如JVM或者其他Runtime)负责调度,而非OS;
彼时像 Sun Solaris 这样的系统一次只能处理一个绿色线程,虽然在用户态有多个绿色线程,但所有线程都映射到同一个OS线程中执行,所以说实际上这是一种多对一的线程模型,无法真正利用CPU的多核能力。还会带来一些副作用,譬如说:
- 系统调用会阻塞所有绿色线程
-
内核级别的Page Fault会影响所有绿色线程
因此Sun在后面的实现里就废弃了绿色线程,而改用一对一的线程模型。
线程模型(参考JDK 1.1 for Solaris Developer’s Guide):
- 多对一
即绿色线程使用的线程模型,多条用户态的绿色线程映射到同一条OS线程。
- 一对一
目前大部分语言实现采用的线程模型,用户态的线程一对一映射到内核线程上,好处是实现简单,统一由操作系统负责调度,需要注意不要创建过多的线程。
- 多对多
经典的就是Erlang的进程和Go的goroutine,M:N 的映射关系,大量(M)虚拟的线程被调度在较少数量(N)的操作系统线程上运行。用户态的运行时负责调度用户态线程,OS则只需要负责OS线程,各司其职。灵活度更高,开发者基本不用担心线程数爆炸的问题。
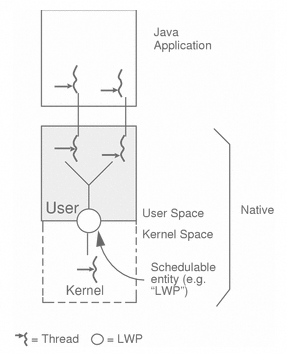
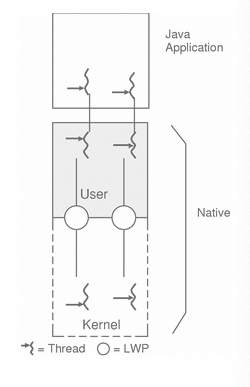
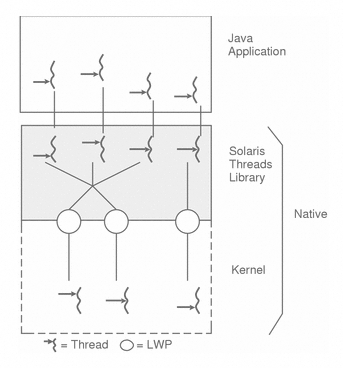
不过,需要指明的是,Java规范本身并没有规定说需要采用哪种线程模型,事实上,它特别指出:
“These semantics do not prescribe how a multithreaded program should be executed. Rather, they describe the behaviors that multithreaded programs are allowed to exhibit. Any execution strategy that generates only allowed behaviors is an acceptable execution strategy.”
与此对应的是直到今天仍有像Jikes RVM之类的虚拟机还在使用绿色线程。绿色线程并非完全一无是处,它可以在不支持多线程的平台上模拟多线程。由于映射到同一个CPU核,所有的内容都在一个系统进程里面执行,还可以带来一些好处,这些优势在后面的虚拟线程里也能看到:
-
线程的切换很快 -
分配线程的开销很低:一方面是创建和销毁很快,另一方面内存使用也更少 -
竞态条件和线程同步处理起来更简单
我猜测Java最开始使用绿色线程是响应其 “Write Once,Run Anywhere” 的slogan,因为绿色线程是用户态的,并不依赖具体OS(可能有些操作系统根本就没有提供多线程能力)。
为什么叫”绿色”线程?这个我没有找到标准答案,一种有趣的说法是:在美国,如果你不是原生的 (Native) ,那你就要有一张绿卡(Green Card)。
JDK1.2中增加了一个可以切换绿色线程和本地线程的开关,然后在JDK 1.3之后被彻底弃用,在此之后其实Java的底层线程模型就没有大的改动了,更多的是API层面的:
-
JDK 1.4引入了NIO包(java.nio),与此对应的是BIO(Blocking IO),很多Java Web容器的线程模型介绍里都能看到过这两个概念。 -
JDK 1.5算是一个里程碑版本。 J.U.C(java.util.concurrent)下新增了Executor, Semaphore, Lock、CyclicBarrier, CountDownLatch, BlockingQueue、Atomic Variables以及一系列现在我们常用的并发集合类。在这之前,程序员只能使用像synchronized、volatile、 wait()、notify()和notifyAll()这些低级并发原语来控制并发。 -
JDK 1.7 引入了ForkJoinPool和NIO2(主要是java.nio.file)。 此外还有TransferQueue, ConcurrentLinkedDeque, ThreadLocalRandom等小更新。 -
JDK 1.8的Parallel SteamAPI,CompletableFuture特性。 -
Java 9 ~ Java 18:return Optional.empty();…

为什么要有虚拟线程?
先看看虚拟线程能带来什么。虚拟线程拥有与上面所说的绿色线程的一样的优点,简而言之:虚拟线程相比普通线程更轻量,分配和切换的开销更小。所以如果你需要很多的线程,并且线程之间经常发生切换,那就可以考虑换成虚拟线程。
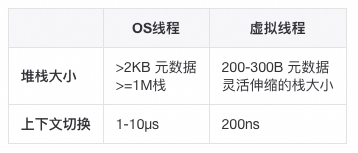
Java现有的线程实现是OS线程的一层thin wrapper,OS线程的优点是它足够通用,不管是什么语言/什么应用场景,但OS线程的问题也正是来自于此:
-
OS不知道用户态的程序会如何使用线程,它会给每条线程分配一个固定大小的堆栈,通常会比实际使用的要大很多; -
线程的上下文切换要通过内核调度进行,相对更慢; -
线程的调度算法需要做兼顾和妥协,很难做特定的优化,像web server中处理请求的线程和视频编解码的线程行为有很大的区别;
OS线程的昂贵开销限制了Java程序不能创建太多的线程。在其他资源(例如 CPU 或网络连接)耗尽之前,线程的数量往往会成为限制因素,导致硬件资源不能得到充分利用。如果没有很好的编程技巧,不小心写了会导致线程阻塞的逻辑,那就GG了。这就形成了一种尴尬的局面:我用Java写代码,还需要特别小心线程怎么使用,线程池怎么配置等等跟我业务无关的东东,我用goroutine一把梭不香吗?从这个层面讲,使用虚拟线程的好处,就像程序不用关心虚拟内存和物理内存一样,开发者可以专注于编写简单的、也许会阻塞的代码 —— 然后交由JVM负责调度到共享的OS线程,以将阻塞成本降低到接近于零。虚拟线程与虚拟内存如此相似,可能这也是为何命名从一开始的纤程(Fiber)改为”虚拟线程”的原因。
另一方面,虚拟线程不能带来什么?要意识到虚拟线程是更轻量的线程,但并不是”更快”的线程,它每秒执行的CPU指令并不会比普通线程要多。还是举之前写的例子,假设有这样一个场景,需要同时启动10000个任务做一些事情:
// 创建一个虚拟线程的Executor,该Executor每执行一个任务就会创建一个新的虚拟线程try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {IntStream.range(0, 10_000).forEach(i -> {executor.submit(() -> {doSomething();return i;});});} // executor.close() is called implicitly, and waits
-
如果doSomething()里执行的是某类IO操作,那么使用虚拟线程是非常合适的,因为虚拟线程创建和切换的代价很低,底层对应的可能只需要几个OS线程。如果没有虚拟线程,不考虑ForkJoin之类的工具,使用普通线程的话: -
Executors.newVirtualThreadPerTaskExecutor()换成Executors.newCachedThreadPool()。结果是程序会崩溃,因为大多数操作系统和硬件不支持这种规模的线程数。
-
换成Executors.newFixedThreadPool(200)或者其他自定义的线程池,那这10000个任务将会共享200个线程,许多任务将按顺序运行而不是同时运行,并且程序需要很长时间才能完成。
-
-
如果doSomething()里执行的是某类计算任务,例如给一个大数组排序,那么虚拟线程反而还可能带来多余的开销。
总结一下,虚拟线程真正擅长的是等待,等待大量阻塞操作完成。它能提供的是 scale(更高的吞吐量),而不是 speed(更低的延迟)。虚拟线程最适合的是原来需要更多线程数来处理计算无关业务的场景,典型的就是像web容器、数据库、文件操作一类的IO密集型的应用。
为什么现在才有虚拟线程?
为什么Java迟迟没有引入协程,而是等到今天才有了虚拟线程?我个人觉得,一方面是Java说好听点叫保守,说难听点就是有点”不思进取”,另一方面是Java现有的工具箱不是不能用,只是不够好用。Java语言本身发展到现在已经非常成熟,加上很神奇的一点是它的生态里有各种框架帮它添砖加瓦,譬如:
这么一看,确实没有什么一定要用虚拟线程才能解决的事情,而多线程开发里容易出现的各种并发问题,例如共享变量的使用,在虚拟线程中一样免不了,可以理解为什么Java在推进这个事情上动力不足了。
但是,正如这篇OpenJDK官网上的Loom提案《Project Loom: Fibers and Continuations for the Java Virtual Machine》里所说,我们使用这些异步 API ,并不是因为它们更容易理解和编写 —— 实际上它们更难;不是因为它们更容易调试或分析 —— 实际上它们甚至不会产生有意义的堆栈跟踪;不是因为它们比同步 API 编写得更好——它们编写得不那么优雅;不是因为它们更适合这门语言或是与现有代码能更好地集成——它们更不适合。归根到底,原因是线程作为 Java 中并发编程的基础单元,从占用空间和性能的角度来看是不够的。

为了最大化性能,开发者确实太难了。有没有可能”既要,又要,还要”呢?虚拟线程带来了希望之光,那就是用同步编程的方式,写出跟异步一样性能的代码。
曲线救国的实现
既然官方一直没有提供,而人民确实有需求,民间自然涌现了一些曲线救国的实现,像Quasar、Kilim、ea-async。
Quasar的项目作者Ron Pressler同样也是Project Loom的主导者之一,所以我重点看了下Quasar的实现原理。简单说其实现思路是通过字节码注入的方式在方法调用前后做堆栈的保存和恢复,其他几个库的实现原理也大体类似,大体流程如下:
-
在class被加载时,Quasar的instrumentation模块(通常是以Java agent的方式挂载,也支持AOT编译)查找其中的Suspendable方法; -
为每个Suspendable方法f做instrument,先查找对其他Suspendable方法g的调用,在调用的前后插入保存和恢复栈帧的指令,每个 fiber 有一个自己的 fiber 栈; -
记录对方法g的调用是一个可能的挂起点; -
在这个“可挂起调用链”的末尾,有一个对Fiber.park的调用。park通过抛出SuspendExecution异常来挂起 fiber; -
如果g确实阻塞,那么Fiber类将捕获SuspendExecution异常。当fiber被unpark时,将调用方法f,然后执行记录将显示是在调用g时被阻塞,因此将立即跳到f中调用g的行,并调用它; - 最后到达实际的挂起点(对park的调用处),在调用后立即恢复执行。当g返回时,插入f中的代码将从 fiber 栈中恢复f的局部变量;
这个流程看上去比较复杂,Quasar号称性能损失不会超过3%-5%。感兴趣的可以研究下源代码,注入的逻辑主要在InstrumentMethod这个类里。
从上面的流程里可以看到,关键的一点是开发者需要手动标记哪些方法是Suspendable 方法,这有几种方式:
-
方法上加了 @Suspendable 注解 -
方法抛出了SuspendExecution(这是Quasar定义的异常类型) -
在META-INF/suspendables和META-INF/suspendable-supers下指定,主要是用于无法直接修改代码的第三方库 -
其他的像是反射调用的方法,lambda调用等
Quasar默认使用一个 FiberForkJoinScheduler 来调度fiber,底层使用了ForkJoinPool。当然你也可以设置其他的线程池。
Quasar项目在18年之后就不再更新,这哥们转头就加入Oracle搞Project Loom去了。像Quasar这类工具,并没有流行起来,我觉得除去Java协程这个概念的接受度不高的因素外,工具本身的成熟度也不够,最致命的是存在侵入性,比如说Suspendable方法的声明,运行期的agent挂载。
API上手
由于虚拟线程在Java 19中还是预览特性,因此需要启用–enable-preview才能运行。如果在idea中跑,选择Jdk-19版本后,记得设置 Language Level 为 19(Preview)。
虚拟线程的API非常非常简单,在设计上与现有的Thread类完全兼容。虚拟线程创建出来后也是Thread实例,因此很多原先的代码可以无缝迁移。
可以使用Thread类的新增API直接创建虚拟线程:
Runnable runnable = () -> {...};// 直接启动一个虚拟线程Thread.startVirtualThread(runnable);// 使用新的builder API创建一个命名虚拟线程var builder = Thread.ofVirtual().name("VT-1").uncaughtExceptionHandler((t, e) -> {// do something}).allowSetThreadLocals(false);builder.start(runnable);// 创建虚拟线程的ThreadFactoryThreadFactory factory = Thread.ofVirtual().factory();// 判断当前Thread是否虚拟线程thread.isVirtual();
或是使用虚拟线程的Executor来代替线程池:
// ExecutorService现在可以自动伸缩,需要用try-with-resource包裹try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {var future1 = executor.submit(() -> doSomeThing1());var future2 = executor.submit(() -> doSomeThing2());var result = future1.get() + future2.get();} catch (ExecutionException | InterruptedException e) {// handle exception}
性能对比
先来个简单的对比,我的机器是19款i7+16GB的Macbook pro。
public void tryCreateInfiniteThreads() {var adder = new LongAdder();Runnable job = () -> {adder.increment();System.out.println("Thread count = " + adder.longValue());LockSupport.park();};// 启动普通线程startThreads(() -> new Thread(job));// 或是启动虚拟线程startThreads(() -> Thread.ofVirtual().unstarted(job));}public void startThreads(Supplier<Thread> threadSupplier) {while (true) {Thread thread = threadSupplier.get();thread.start();}}
普通线程:创建到4064个线程后程序报OOM错误崩溃。
.......Thread count = 4063Thread count = 4064[0.927s][warning][os,thread] Failed to start thread "Unknown thread" - pthread_create failed (EAGAIN) for attributes: stacksize: 1024k, guardsize: 4k, detached.[0.927s][warning][os,thread] Failed to start the native thread for java.lang.Thread "Thread-4064"Exception in thread "main" java.lang.OutOfMemoryError: unable to create native thread: possibly out of memory or process/resource limits reachedat java.base/java.lang.Thread.start0(Native Method)at java.base/java.lang.Thread.start(Thread.java:1535)at com.rhino.vt.VtExample.startThread(VtExample.java:24)at com.rhino.vt.VtExample.main(VtExample.java:13)
虚拟线程:创建了超过360万个虚拟线程后被挂起,但没有崩溃,虚拟线程的计数一直在缓慢增长,这是因为被 park 的虚拟线程会被垃圾回收,然后 JVM 能够创建更多的虚拟线程并将其分配给底层的平台线程。
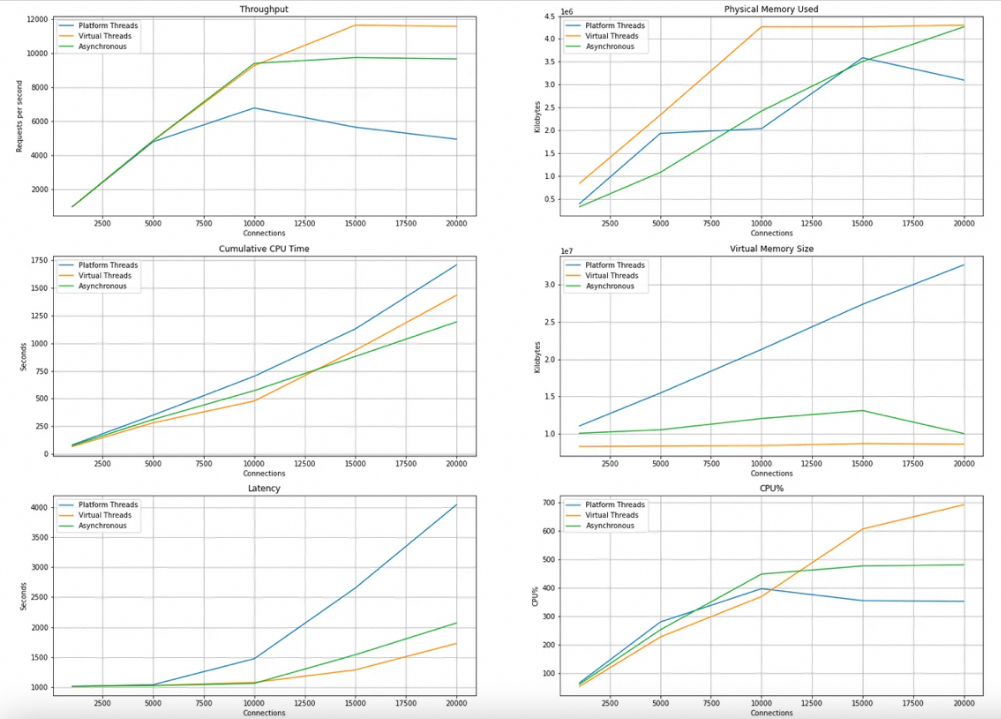
Github上有位老哥做了个更接近真实场景的测试,模拟远程服务请求数据,比较了使用普通线程阻塞式请求、CompletableFeature异步请求、虚拟线程的三种方式的差异,结果显示在连接数少的时候三者差别不大,连接数上去后虚拟线程在吞吐量、内存占用、延迟、CPU占用率方面都有比较大的优势,如下图:
可能这么对比还是不够公平,毕竟一般我们不会直接用这么简单的异步编程,还是会通过各种框架轮子搞。Oracle 的Helidon Níma 号称是第一个采用了虚拟线程的微服务框架,主要的卖点也是性能,可以参考其QPS性能测试数据:
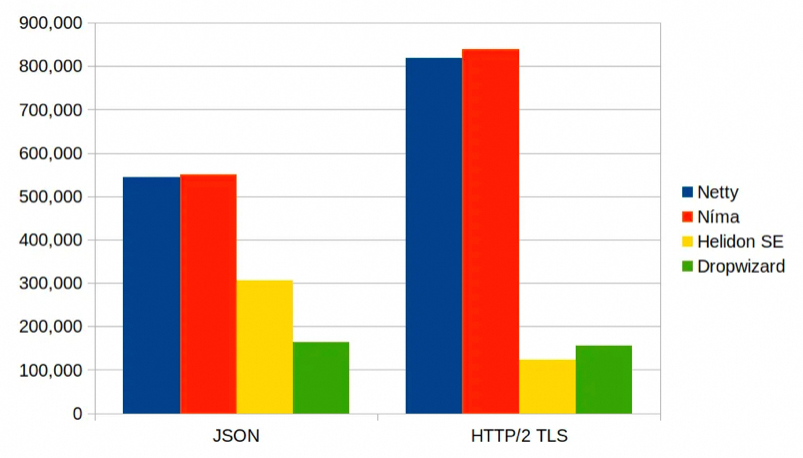
可以看到使用了虚拟线程的web服务器性能很好,与用Netty的差距很小,这也符合预期。相比起来虚拟线程使用起来更简单。
“最佳”实践
总结一下”最佳”实践(为啥带引号?因为预览特性在正式发布前可能变化很大):
-
虚拟线程的开销很低,因此不需要像普通线程池一样被池化,可以为单个RPC请求或者JDBC查询创建一个虚拟线程。另外,如果之前有用线程池来控制并发任务的数目,建议改成信号量的方式。
// WITH THREAD POOLprivate static final ExecutorServiceDB_POOL = Executors.newFixedThreadPool(16);public <T> Future<T> queryDatabase(Callable<T> query) {// pool limits to 16 concurrent queriesreturn DB_POOL.submit(query);}// WITH SEMAPHOREprivate static final SemaphoreDB_SEMAPHORE = new Semaphore(16);public <T> T queryDatabase(Callable<T> query) throws Exception {// semaphore limits to 16 concurrent queriesDB_SEMAPHORE.acquire();try {return query.call();} finally {DB_SEMAPHORE.release();}}
-
虚拟线程支持ThreadLocal和InheritableThreadLocal,就像普通线程一样。但要注意虚拟线程的数目可能很多,需要慎用。 -
可以使用与普通线程一样的同步机制进行并发编程,但要注意有两种特定情况会导致虚拟线程阻塞平台线程:
- 在synchronized同步块中
-
执行本地方法或外部函数时
因此碰到这类代码要小心,考虑将其替换为ReentrantLock机制:
// with synchronization (pinning 👎🏾):// synchronized guarantees sequential accesspublic synchronized String accessResource() {return access();}// with ReentrantLock (not pinning 👍🏾):private static final ReentrantLockLOCK = new ReentrantLock();public String accessResource() {// lock guarantees sequential accessLOCK.lock();try {return access();} finally {LOCK.unlock();}}
PS. JEP里说,在未来的版本里这些限制可能会得到解决。
- 可以通过JFR实时分析和监控虚拟线程,也可以通过jcmd命令执行线程转储。注意虚拟线程对操作系统是不可见的,因此像top -H一类的命令只能看到Java进程使用的普通线程。
thread = continuation + scheduler
回过头来讨论下:到底什么是**”线程”**?简单的定义是,”线程”是顺序执行的一系列计算机指令。由于我们处理的操作可能不仅涉及计算,还涉及 IO、定时暂停和同步等,线程会有包括运行、阻塞、等待在内的各种状态,并在状态之间调度流转。当一个线程阻塞或等待时,它应该腾出计算资源(CPU内核),并允许另一个线程运行,然后在等待的事件发生时恢复执行。这其中涉及到两个概念:
-
continuation(这个词实在不知道怎么翻译才恰当):一系列顺序执行的指令序列,可能会暂停或阻塞,然后恢复执行; -
scheduler:顾名思义,负责协调调度线程的机制;
两者是独立的,因此我们可以选择不同的实现。之前的普通线程,在VM层面仅仅是对OS线程的一层简单封装,continuation和scheduler都是交给OS管理,而虚拟线程实现则是在VM里完成这两件事情,当然底层还是需要有相应的OS线程作为载体线程(CarrierThread),并且这个对应并不是固定不变的,在虚拟线程恢复后,完全可能被调度到另一个载体线程。
| 组合 | scheduler-OS | scheduler-Runtime |
|---|---|---|
| continuation-OS | Java现在的Thread | 谷歌对Linux内核修改的User-Level Threads |
| continuation-Runtime | 糟糕的选择? | 虚拟线程 |
- 挂载(mount):挂载虚拟线程意味着将所需的栈帧从堆中临时复制到载体线程的堆栈中,并在挂载时借用载体堆栈执行。
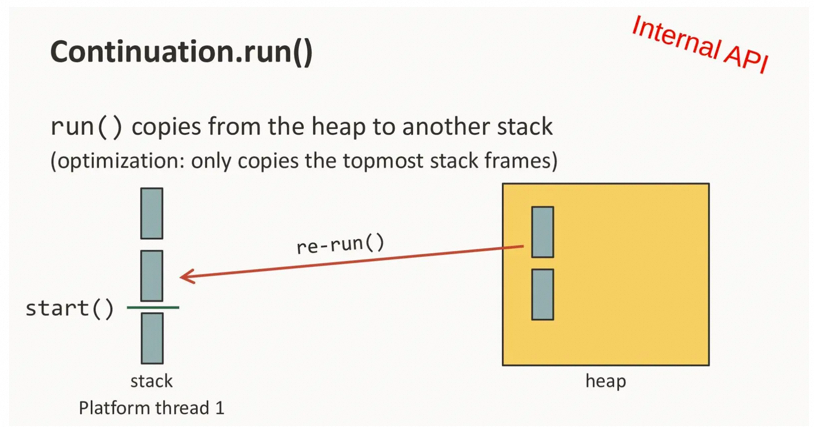
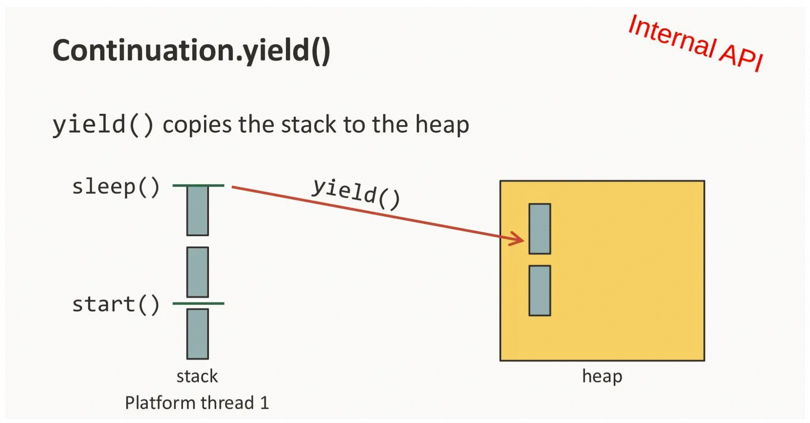
- 卸载(unmount):当在虚拟线程中运行的代码因为 IO、锁等原因阻塞后,它可以从载体线程中卸载,然后将修改的栈帧复制回堆中,从而释放载体线程以进行其他操作(例如运行另一个虚拟线程)。对应的,JDK 中几乎所有的阻塞点都已经过调整,因此当在虚拟线程上遇到阻塞操作时,虚拟线程会从其载体上卸载而不是阻塞。
关于scheduler就比较简单了,因为JDK中有现成的ForkJoinPool可以用。work-stealing + FIFO,性能很好。scheduler的并行性是可用于调度虚拟线程的OS线程数。默认情况下,它等于可用CPU核数,也可以使用系统属性jdk.virtualThreadScheduler.parallelism进行调整。
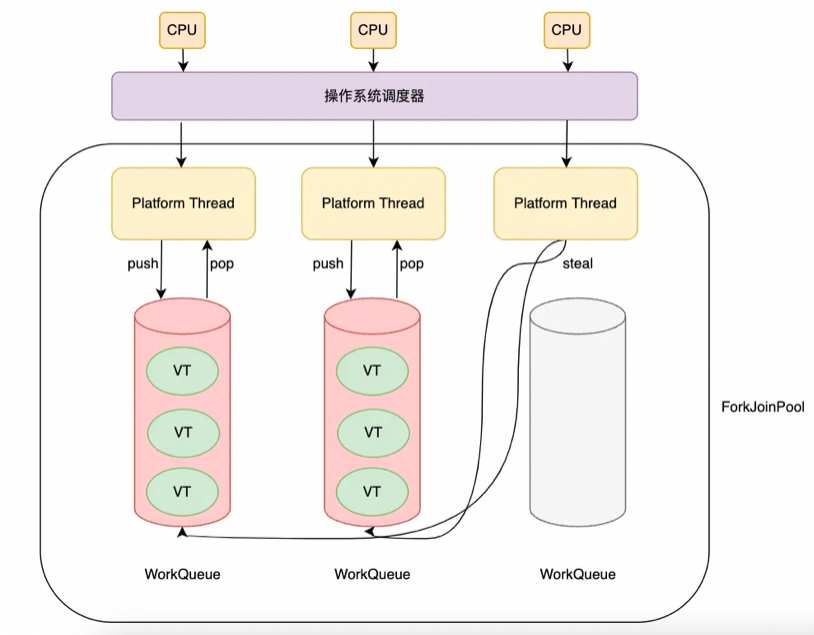
需要注意的是,JDK中的绝大多数阻塞操作将卸载虚拟线程,释放其载体线程来承担新的工作。但是,JDK中的一些阻塞操作不会卸载虚拟线程,因此会阻塞其载体线程。这是因为操作系统级别(例如,许多文件系统操作)或JDK级别(例如,Object.wait())的限制。这些阻塞操作的解决方式是,通过临时扩展scheduler的并行性来补偿操作系统线程的捕获。因此,scheduler的ForkJoinPool中的平台线程数量可能暂时超过CPU核数。scheduler可用的最大平台线程数可以使用系统属性:
jdk.virtualThreadScheduler.maxPoolSize进行调整。
源码一窥
试着写一个使用虚拟线程进行网络IO的例子,来窥视下虚拟线程底层的魔法。
下面代码使用了基于虚拟线程的ExecutorService来获取一组URL的响应。每个URL任务会启动一个虚拟线程进行处理。
// record是JDK 14中引入的,这里作为简单的数据类,保存url和响应record URLData (URL url, byte[] response) { }public List<URLData> retrieveURLs(URL... urls) throws Exception {try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {var tasks = Arrays.stream(urls).map(url -> (Callable<URLData>)() -> getURL(url)).toList();return executor.invokeAll(tasks).stream().filter(Future::isDone).map(this::getFutureResult).toList();}}
获取响应的逻辑在getURL中实现,使用同步的URLConnectionAPI来读取数据。
URLData getURL(URL url) throws IOException {try (InputStream in = url.openStream()) {return new URLData(url, in.readAllBytes());}}
这里我模拟了两个HTTP接口,其中一个响应很慢,因此在运行后不会马上完成。
// test1接口sleep 1s返回,test2接口则sleep 100sexample.retrieveURLs(new URL("http://localhost:7001/test1"), new URL("http://localhost:7001/test2"));
jcmd `jps | grep VtExample | awk '{print $1}'` Thread.dump_to_file -format=json thread_dump.json
{"container": "java.util.concurrent.ThreadPerTaskExecutor@5d5a133a","parent": "<root>","owner": null,"threads": [{"tid": "24","name": "","stack": ["java.base/jdk.internal.vm.Continuation.yield(Continuation.java:357)","java.base/java.lang.VirtualThread.yieldContinuation(VirtualThread.java:370)","java.base/java.lang.VirtualThread.park(VirtualThread.java:499)","java.base/java.lang.System$2.parkVirtualThread(System.java:2596)","java.base/jdk.internal.misc.VirtualThreads.park(VirtualThreads.java:54)","java.base/java.util.concurrent.locks.LockSupport.park(LockSupport.java:369)","java.base/sun.nio.ch.Poller.poll2(Poller.java:139)","java.base/sun.nio.ch.Poller.poll(Poller.java:102)","java.base/sun.nio.ch.Poller.poll(Poller.java:87)","java.base/sun.nio.ch.NioSocketImpl.park(NioSocketImpl.java:175)","java.base/sun.nio.ch.NioSocketImpl.park(NioSocketImpl.java:196)","java.base/sun.nio.ch.NioSocketImpl.implRead(NioSocketImpl.java:304)","java.base/sun.nio.ch.NioSocketImpl.read(NioSocketImpl.java:340)","java.base/sun.nio.ch.NioSocketImpl$1.read(NioSocketImpl.java:789)","java.base/java.net.Socket$SocketInputStream.read(Socket.java:1025)","java.base/java.io.BufferedInputStream.fill(BufferedInputStream.java:255)","java.base/java.io.BufferedInputStream.read1(BufferedInputStream.java:310)","java.base/java.io.BufferedInputStream.implRead(BufferedInputStream.java:382)","java.base/java.io.BufferedInputStream.read(BufferedInputStream.java:361)","java.base/sun.net.www.http.HttpClient.parseHTTPHeader(HttpClient.java:827)","java.base/sun.net.www.http.HttpClient.parseHTTP(HttpClient.java:759)","java.base/sun.net.www.protocol.http.HttpURLConnection.getInputStream0(HttpURLConnection.java:1684)","java.base/sun.net.www.protocol.http.HttpURLConnection.getInputStream(HttpURLConnection.java:1585)","java.base/java.net.URL.openStream(URL.java:1162)","com.rhino.vt.VtExample.getURL(VtExample.java:59)","com.rhino.vt.VtExample.lambda$retrieveURLs$0(VtExample.java:40)","java.base/java.util.concurrent.ThreadPerTaskExecutor$ThreadBoundFuture.run(ThreadPerTaskExecutor.java:352)","java.base/java.lang.VirtualThread.run(VirtualThread.java:287)","java.base/java.lang.VirtualThread$VThreadContinuation.lambda$new$0(VirtualThread.java:174)","java.base/jdk.internal.vm.Continuation.enter0(Continuation.java:327)","java.base/jdk.internal.vm.Continuation.enter(Continuation.java:320)"]}],"threadCount": "1"}
作为对比,把代码中的executor改成Executors.newCachedThreadPool(),再dump出直接使用普通线程的堆栈:
{"tid": "23","name": "pool-1-thread-2","stack": ["java.base/sun.nio.ch.SocketDispatcher.read0(Native Method)","java.base/sun.nio.ch.SocketDispatcher.read(SocketDispatcher.java:47)","java.base/sun.nio.ch.NioSocketImpl.tryRead(NioSocketImpl.java:251)","java.base/sun.nio.ch.NioSocketImpl.implRead(NioSocketImpl.java:302)","java.base/sun.nio.ch.NioSocketImpl.read(NioSocketImpl.java:340)","java.base/sun.nio.ch.NioSocketImpl$1.read(NioSocketImpl.java:789)","java.base/java.net.Socket$SocketInputStream.read(Socket.java:1025)","java.base/java.io.BufferedInputStream.fill(BufferedInputStream.java:255)","java.base/java.io.BufferedInputStream.read1(BufferedInputStream.java:310)","java.base/java.io.BufferedInputStream.implRead(BufferedInputStream.java:382)","java.base/java.io.BufferedInputStream.read(BufferedInputStream.java:361)","java.base/sun.net.www.http.HttpClient.parseHTTPHeader(HttpClient.java:827)","java.base/sun.net.www.http.HttpClient.parseHTTP(HttpClient.java:759)","java.base/sun.net.www.protocol.http.HttpURLConnection.getInputStream0(HttpURLConnection.java:1684)","java.base/sun.net.www.protocol.http.HttpURLConnection.getInputStream(HttpURLConnection.java:1585)","java.base/java.net.URL.openStream(URL.java:1162)","com.rhino.vt.VtExample.getURL(VtExample.java:59)","com.rhino.vt.VtExample.lambda$retrieveURLs$0(VtExample.java:40)","java.base/java.util.concurrent.FutureTask.run(FutureTask.java:317)","java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1144)","java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:642)","java.base/java.lang.Thread.run(Thread.java:1589)"]}
两个堆栈对比一下会发现,除了中间执行的业务逻辑部分是一致的,有两点不同:
1、普通线程的入口是Thread.run,而虚拟线程的入口是Continuation,这个类是虚拟线程的核心类,是VM内部对上面所说的continuation的抽象。Continuation有两个关键方法:yield()和run()。
可以试着跑一下这段代码看看输出结果:
public void testContinuation() {var scope = new ContinuationScope("test");var continuation = new Continuation(scope, () -> {System.out.println("C1");Continuation.yield(scope);System.out.println("C2");Continuation.yield(scope);System.out.println("C3");Continuation.yield(scope);});System.out.println("start");continuation.run();System.out.println("came back");continuation.run();System.out.println("back again");continuation.run();System.out.println("back again again");continuation.run();}// Output:startC1came backC2back againC3back again again
--add-opens java.base/jdk.internal.vm=ALL-UNNAMED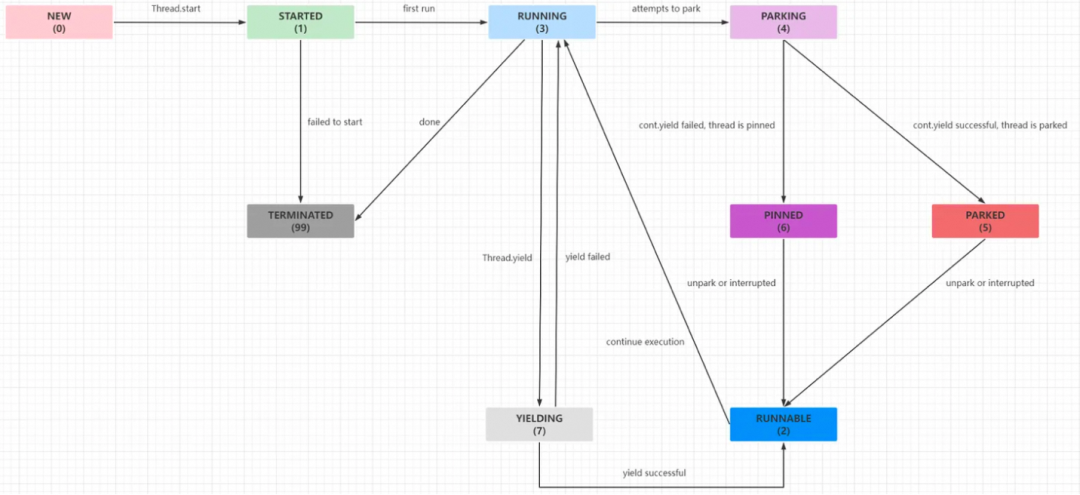
在线程dump文件里还能找到一个叫Read-Poller的线程(对应的还有一个写操作的 Write-Poller线程):
{"tid": "27","name": "Read-Poller","stack": ["java.base/sun.nio.ch.KQueue.poll(Native Method)","java.base/sun.nio.ch.KQueuePoller.poll(KQueuePoller.java:66)","java.base/sun.nio.ch.Poller.poll(Poller.java:363)","java.base/sun.nio.ch.Poller.pollLoop(Poller.java:270)","java.base/java.lang.Thread.run(Thread.java:1589)","java.base/jdk.internal.misc.InnocuousThread.run(InnocuousThread.java:186)"]}
JDK底层做了什么调整呢?从Read-Poller可以看出,其实就是把原来的阻塞调用改为了非阻塞的IO调用。流程如下:
/*** Unparks any thread that is polling the given file descriptor.*/private void wakeup(int fdVal) {Thread t = map.remove(fdVal);if (t != null) {LockSupport.unpark(t);}}
虚拟线程的unpark()方法如下:
/*** Re-enables this virtual thread for scheduling. If the virtual thread was* {@link #park() parked} then it will be unblocked, otherwise its next call* to {@code park} or {@linkplain #parkNanos(long) parkNanos} is guaranteed* not to block.* @throws RejectedExecutionException if the scheduler cannot accept a task*/void unpark() {Thread currentThread = Thread.currentThread();if (!getAndSetParkPermit(true) && currentThread != this) {int s = state();// CAS设置线程状态if (s == PARKED && compareAndSetState(PARKED, RUNNABLE)) {if (currentThread instanceof VirtualThread vthread) {Thread carrier = vthread.carrierThread;carrier.setCurrentThread(carrier);try {// 提交给scheduler执行submitRunContinuation();} finally {carrier.setCurrentThread(vthread);}} else {submitRunContinuation();}} else if (s == PINNED) {// unpark carrier thread when pinned.synchronized (carrierThreadAccessLock()) {Thread carrier = carrierThread;if (carrier != null && state() == PINNED) {U.unpark(carrier);}}}}}
/*** Submits the runContinuation task to the scheduler.* @param {@code lazySubmit} to lazy submit* @throws RejectedExecutionException* @see ForkJoinPool#lazySubmit(ForkJoinTask)*/private void submitRunContinuation(boolean lazySubmit) {try {if (lazySubmit && scheduler instanceof ForkJoinPool pool) {pool.lazySubmit(ForkJoinTask.adapt(runContinuation));} else {// 默认shceduler就是ForkJoinPoolscheduler.execute(runContinuation);}} catch (RejectedExecutionException ree) {// 省略异常处理代码}}
而在park()里,虚拟线程让出资源的关键方法是VirtualThread.yieldContinuation(),可以发现mount()和unmount()操作。
/*** Unmounts this virtual thread, invokes Continuation.yield, and re-mounts the* thread when continued. When enabled, JVMTI must be notified from this method.* @return true if the yield was successful*/private boolean yieldContinuation() {boolean notifyJvmti = notifyJvmtiEvents;// unmountif (notifyJvmti) notifyJvmtiUnmountBegin(false);unmount();try {return Continuation.yield(VTHREAD_SCOPE);} finally {// re-mountmount();if (notifyJvmti) notifyJvmtiMountEnd(false);}}
mount()和unmount()会在Java堆和本地线程栈之间做栈帧的拷贝,这是Project Loom中为数不多的在JVM层面实现的本地方法,感兴趣的可以去Loom的github库里搜一下continuationFreezeThaw.cpp。其余的大部分代码在JDK中实现, 参见java.base模块下的jdk.internal.vm包。
在我看来,将近而立之年的Java仍然充满活力。虚拟线程的到来,给我们展示了一种新的可能性,在处理IO密集这类特定场景的任务时,可以有”Code Like Sync, Scale Like Async”的两全之法。
原创文章,作者:guozi,如若转载,请注明出处:https://www.sudun.com/ask/90833.html